# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
面对同行评审,许多作者都有过这样的经历:明明回答了审稿人的每一个问题,态度也足够谦卑,为什么最终还是没能打动对方?
现有的通用大模型在处理这类任务时,往往陷入一种 “表面礼貌” 的陷阱:它们擅长生成流畅、委婉的 “Thank you for your insightful comment”,却缺乏对审稿人言外之意的深度洞察,导致回复虽然客气,但缺乏直击痛点的说服力。
究竟什么样的回复策略,才能在有限的篇幅内,有效消除误解、赢得共识?
针对这一问题,来自香港科技大学的研究团队提出了一种全新的框架 ——RebuttalAgent。该研究首次将认知科学中的 心智理论(Theory of Mind, ToM) 引入学术 Rebuttal 任务,让 AI 能够像资深学者一样 “读懂” 审稿人,从而生成兼具战略性与说服力的回复。
目前,该论文已被 ICLR 2026 接收。

在学术界的博弈论视角下,Rebuttal 是一个典型的 “不完全信息动态博弈”(Dynamic Game of Incomplete Information)。作者不仅要面对审稿人显性的质疑,还要应对隐性的信息不对称,你不知道审稿人的知识背景、潜在偏见,也不知道你的解释会引发怎样的连锁反应。
现有的基于监督微调的模型,大多止步于对人类回复的‘语言学拟态’。它们精准复刻了礼貌的‘外壳’,却未能触及审稿人意图的‘内核’,即缺乏对审稿人的深度建模。 针对这一痛点,研究者提出了 RebuttalAgent,其核心洞察:有效的说服机制,必须建立在对他人的‘心智理论’建模之上。
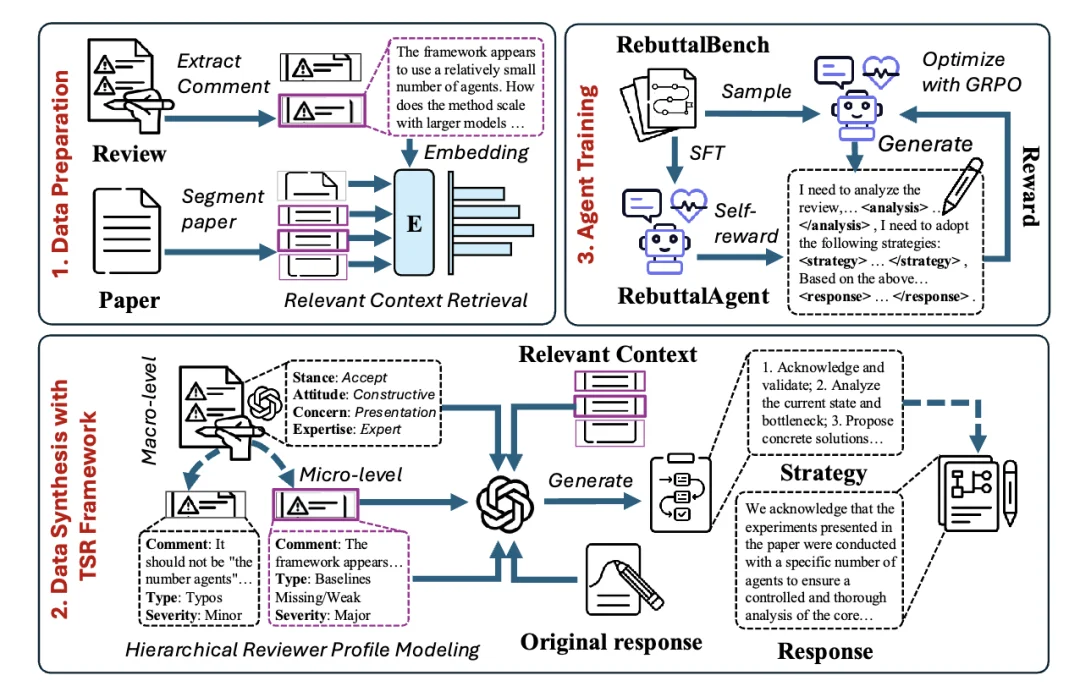
图一:RebuttalAgent 框架总览图,展示 Data Preparation, TSR Framework 和 Agent Training 三个阶段
RebuttalAgent 并没有直接端到端地生成回复,而是模拟了人类专家的思维过程,通过 ToM-Strategy-Response (TSR) 框架来拆解这一复杂任务:
1. ToM(心智理论建模):不仅仅是读文本 AI 首先充当一名 “分析师”,对审稿意见进行分层剖析。
2. Strategy(谋定而后动):基于上述画像,AI 会生成一个明确的战略计划。例如,面对一个 “专业度高但态度怀疑” 的审稿人,策略可能是 “先承认局限性以建立信任,再用补充实验数据进行强力反击”;而面对 “误解型” 评论,策略则是 “澄清概念,重述核心贡献”。
3. Response(精准打击):最后,AI 结合原始论文片段、战略计划和审稿人画像,生成最终的回复。
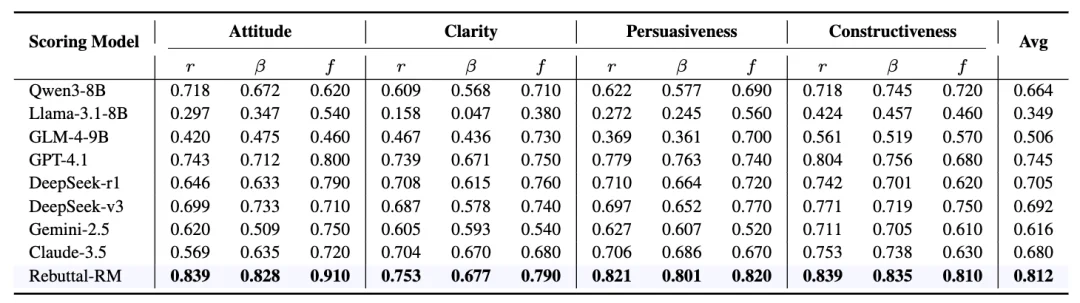
表一:评估的一致性:Rebuttal-RM 在对齐人类偏好上超越 GPT-4.1
为了训练这样一个能够 “运筹帷幄” 的 Agent,研究团队面临的最大挑战是数据的稀缺与主观性。为此,他们构建了 RebuttalBench,包含超过 7 万条高质量的 “分析 - 策略 - 回复” 链条数据。
更进一步,研究者引入了 Self-Reward 机制 的强化学习策略。与传统的依赖外部奖励模型不同,RebuttalAgent 利用自身生成的评价信号进行迭代:
为了量化评估效果,研究团队开发了 Rebuttal-RM,这是一个专门针对学术反驳场景训练的奖励模型。在与人类专家评分的一致性测试中,Rebuttal-RM 的表现超越了 GPT-4.1。
在这一评估体系下,RebuttalAgent 展现出了显著优势:
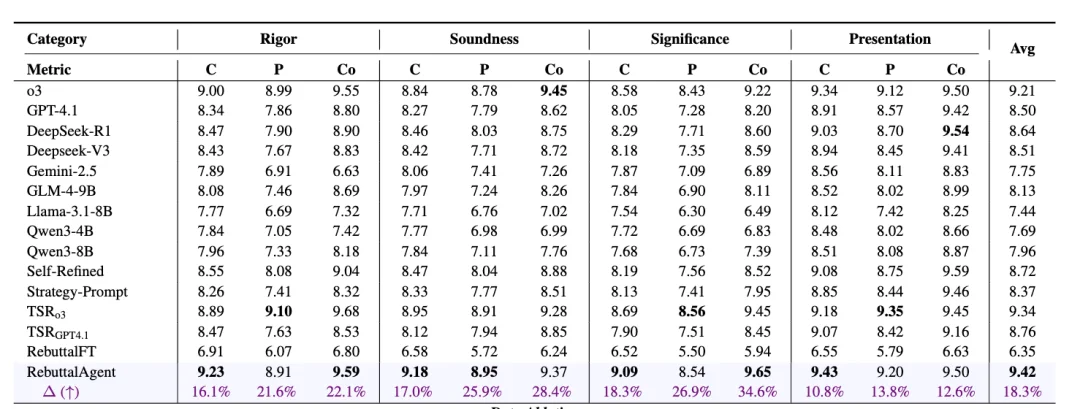
表二:RebuttalAgent 与其他强基线的性能对比
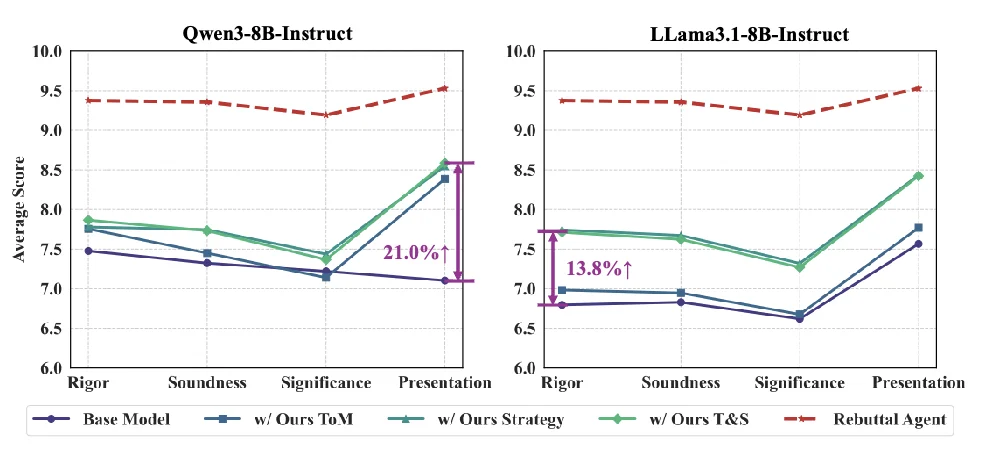
RebuttalAgent 生成的 “分析(Analysis)” 和 “策略(Strategy)” 是否具有普适性?研究者设计了一个巧妙的实验:将 RebuttalAgent 生成的策略作为上下文(Context),喂给参数量较小的基础模型(如 Qwen3-8B 和 Llama-3.1-8B),观察它们的表现变化 (Average Score)。
实验发现,这是一个通用的 “思维外挂”。仅需引入 RebuttalAgent 的策略指导,Qwen3-8B 在 “表达清晰度” 上的得分就暴涨了 21.0% ,这有力地证明了 TSR 框架的可迁移性。
RebuttalAgent 的提出,展示了 LLM 在处理高阶认知任务,特别是涉及复杂人际博弈和战略沟通场景的巨大潜力。但 Agent 无法替你完成实验,也不会凭空捏造数据,模型在训练之初就刻意剥离了涉及实验结果生成的指令,杜绝了 “幻觉造假” 的可能。
RebuttalAgent 本质上是对 大语言模型在严重信息不对称条件下战略说服能力的一次探索性研究。最终的科学判断与责任,始终掌握在人类作者手中。
作者介绍:
何致涛,香港科技大学计算机系博士生,导师 Yi R. (May) Fung。曾在中国科学院自动化研究所、清华大学 AIR、蚂蚁集团从事研究,并在 ACL、NeurIPS、COLM、ICLR 等机器学习与自然语言处理顶级会议上发表多篇论文。
文章来自于“机器之心”,作者 “机器之心”。



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
