# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
“时光流转,谁还用日记本。往事有底片为证。”—— 许嵩《摄影艺术》
“找到那次看完那场烟花秀的几天后,我去海边拍的那些照片”。当你脑海中闪过这样的念头,没有任何一个图像检索系统能帮上忙。不是因为 AI 看不懂海滩或烟花,而是因为在它眼里,你的几千上万张照片只是一堆散乱的图片,而不是一段连贯的情景记忆。
这背后是一个根本性的范式缺陷:过去所有的图像检索技术,无论 Embedding 模型多强大,都在做同一件事,把每张图片当作孤岛,逐张匹配。它们能看懂画面里的每一个物体,却读不懂串起你经历的时间线索、空间脉络和事件逻辑组成的复杂人生。
人大高瓴人工智能学院窦志成教授团队联合 OPPO 研究院,正式提出了 DeepImageSearch 这一图像检索新范式,将其从 “逐张语义匹配” 推向 “语料库级上下文推理” 的全新范式。
团队同时构建了该范式首个评测基准 DISBench,并通过 ImageSeeker 框架对当前所有主流前沿模型进行了系统评测。结果颇为震撼,包括 GPT-5.2、Claude-Opus-4.5、Gemini-3-Pro 在内的最强多模态模型,单次尝试能完美解决的查询比例都不超过三成。
当 AI 不再只是匹配单张图片的内容,而是像你本人一样,带着对整段人生经历的理解去翻阅相册,相册搜索才算真正进入了深度搜索时代。而通往这个时代的路,才刚刚被打开。

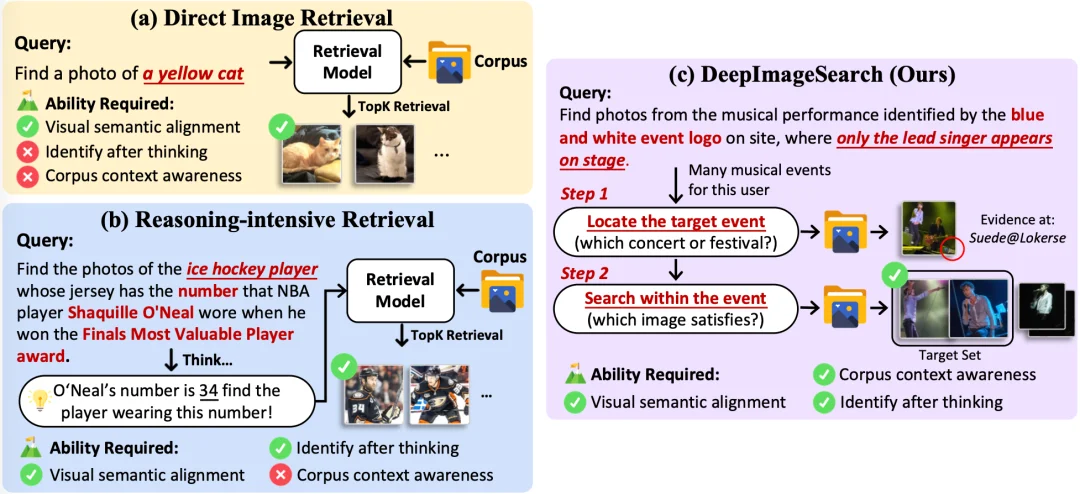
DeepImageSearch 的核心洞察,可以用一句话概括:真正的相册搜索,不是对 1 万张照片做 1 万次独立的图文匹配,而是需要像侦探一样,在你的视觉历史中规划搜索路径、串联散落线索、构建证据链,最后把结果直接送到用户的手上。
过去几年,图像检索的效果随着视觉 - 语言模型基座的进步也日益增强。系统可以通过直接语义对齐帮你找到 “黄色毛发的猫”,甚至可以通过 think-then-embed 的范式帮你找到 “穿奥尼尔取得 FMVP 时球衣号码的冰球运动员照片”(先思考奥尼尔 FMVP 时的号码是 34 号再生成 embedding)。
但无论能力如何增强,他们都有同一个底层假设:每张图片被独立评估,目标仅凭自身的视觉内容就能被识别出来。
DeepImageSearch 打破的正是这个假设。
论文中给了一个很直觉的例子:假设你想找到 “某次音乐节上,只有主唱一个人站在舞台上” 的照片。你可能去过好几场音乐节,拍了大量视觉上高度相似的演出照。灯光、舞台、乐手,外观几乎无法区分。这些目标照片本身不携带任何独特的视觉特征,让你能把它们从其他演出照中挑出来。
但你记得一条线索:那场演出的现场挂着一个蓝白色的活动 logo。
这就是问题的关键所在:解决问题所需的证据(蓝白色 logo)和最终的目标(主唱独自在台上的照片),分散在完全不同的图片里。 模型不能只看目标图片本身就做出判断。它必须先找到包含蓝白色 logo 的照片,锚定这是 Lokerse 音乐节上 Suede 乐队的演出,然后再回到这场演出的所有照片中,筛选出符合条件的那几张。
这不再是一次检索,而是一次多步探索。如果说传统检索是在图书馆按书名找书,那 DeepImageSearch 更像是福尔摩斯破案。线索散落在不同的房间里,每一条都不足以独立指向答案,唯有将它们串联起来,真相才会浮出水面。
这就是 DeepImageSearch 定义的范式转变:图像检索从被动的语义匹配,进化为主动的上下文推理探索。 模型不再只是搜索工具,而更像一个拥有你全部视觉记忆的私人助手。它理解事件之间的时间脉络、空间关联和因果逻辑,能在你人生经历编织成的网络中,循着蛛丝马迹找到答案。
新范式提出来了,但要推动研究进展,还需要一套足够有挑战性的评测基准。然而,给 DeepImageSearch 出题本身就是一件极其困难的事。
想象一下,你面前摆着一个用户三四年来积累的数千张照片。你需要发现类似 “这座雕像在半年内的两次不同旅行中都被拍到了” 这样隐藏的跨事件关联,再基于它设计出一道需要多步推理才能解答的题目。让人类标注员肉眼从头翻到尾去挖掘这种联系是成本极其高昂、不可接受的。
研究团队的解法很巧妙:让模型先做大规模的自动化挖掘,人类专家再核验改进。
他们设计了一套人机协作的流水线,先用视觉语言模型自动解析每张照片中的关键视觉线索(标志性建筑、显眼物体、可见文字等),再通过检索和验证自动挖掘这些线索在不同事件之间的隐藏关联,将所有发现组织成一张结构化的记忆图谱。最后,在这张图谱上采样局部子图,让大语言模型沿着其中的推理路径自动生成候选查询。
简单来说,最耗费心力的关联发现交给了模型,最需要判断力的质量把关留给了人类。
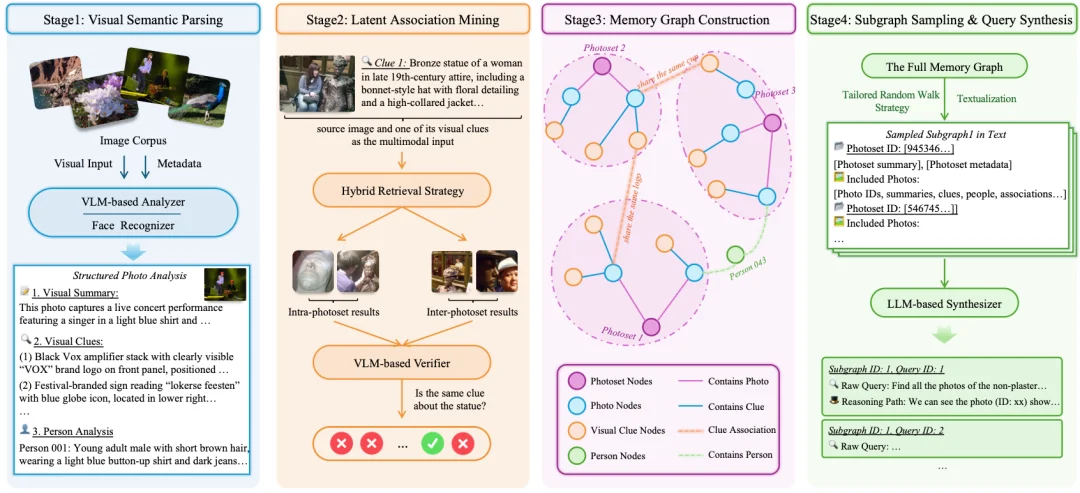
最终的 DISBench(DeepImageSearch-Bench) 包含两类查询,考察两种不同的破案能力:
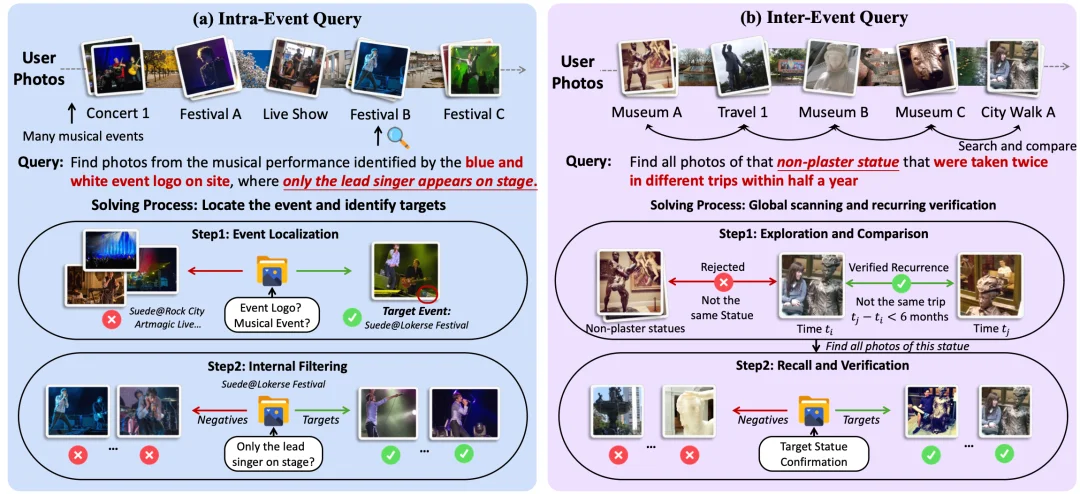
1. Intra-Event 查询(占 46.7%)“先定位是哪次活动,再进一步锁定目标”。 比如音乐节的例子:先通过蓝白 logo 锚定是哪场演出,再从中筛出 "只有主唱一人在台上" 的照片。线索指向一个事件,目标藏在事件内部。
2. Inter-Event 查询(占 53.3%)” 跨越整个相册的多段经历,理解他们之间的关联关系”。 比如 “我曾经在半年内的两次不同旅行中拍到过有一座非石膏雕像,请找到包含这个雕像的所有照片”。模型需要在所有旅行照片中全局扫描、识别同一座雕像、核实时间约束,再召回全部相关照片。
整个基准覆盖 57 位用户、近 11 万张照片,平均每位用户的视觉历史跨度 3.4 年,每条查询平均指向 3.84 张目标图片。而模型在评测时对 "哪些照片属于同一事件" 这样的内在结构完全不可见。它必须像一个真正的助手一样,从一片混沌中自主发现结构、串联线索。
DeepImageSearch 定义了一个全新的任务,但一个随之而来的问题是:要完成这种以个人相册为代表的视觉历史深度搜索,agent 到底需要具备什么样的能力?这在此前是一片空白。没有人在 “探索视觉历史” 这个场景下系统性地思考过这个问题。
研究团队因此设计了 ImageSeeker 框架。它的目标不是追求极致性能,而是作为先驱者做一次系统性的探索:这类任务到底需要什么能力?工具该怎么设计?长程推理中的状态该怎么管理?这些探索所得到的 insight,和框架本身一起,为后续研究提供了参考基线。
工具层面:一种能力远远不够。 团队的核心观察是,模型需要灵活组合四种能力才能应对这个任务:语义检索(用自然语言在相册中搜图)、时空过滤(处理时间和地理位置的精确约束)、视觉确认(把照片调出来仔细看,做细粒度判断)、以及外部知识补充(解决查询中涉及的百科类知识)。更关键的是,这些能力之间可以协同。agent 能把一次检索的结果保存为命名子集,后续在子集内继续搜索或过滤,使得先缩小范围,再精确定位的多步推理成为可能。
记忆层面:战线太长,记不住怎么办? 一次查询可能需要数十步交互,处理大量图片很容易撑爆上下文窗口。ImageSeeker 为此引入了双层记忆机制。一层是显式状态记忆,通过命名子集把中间发现持久化保存,确保多步探索中不丢失已有成果;另一层是压缩上下文记忆,在对话历史接近上限时,自动将其提炼为 "全局目标" 和 "当前行动计划" 两部分摘要,在有限的空间内尽可能保留关键推理状态。
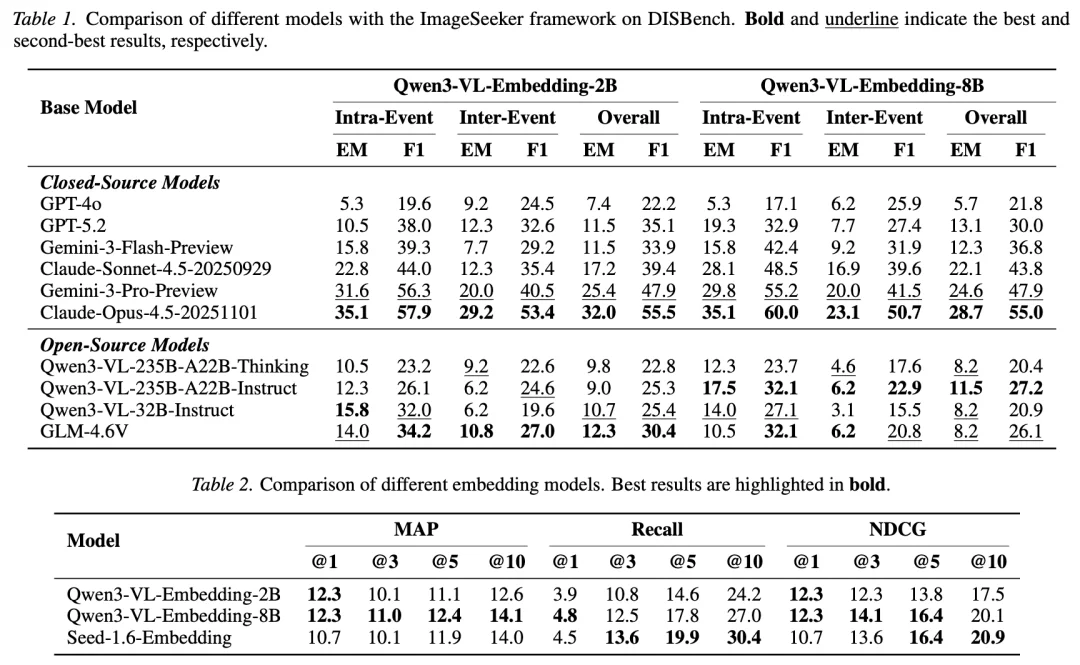
ImageSeeker 框架的模块化设计,使得我们可以将不同的多模态大模型插入同一套工具和记忆机制中,公平地比较它们在这个全新任务上的表现。研究团队测试了几乎所有主流前沿模型:闭源阵营的 GPT-4o、GPT-5.2、Gemini-3-Flash/Pro、Claude-Sonnet-4.5/Opus-4.5,开源阵营的 Qwen3-VL-235B/32B 和 GLM-4.6V。
结果是全线受挫:表现最好的 Claude-Opus-4.5,一次尝试的完美率也只有约 29%。开源最佳的 GLM-4.6V,综合得分不到最强闭源模型的四成。要知道,在传统图像检索基准上,这些模型的表现早已逼近天花板,而 DISBench 让它们集体回到了及格都困难的状态。
那干脆不用 agent,直接用最好的 Embedding 模型做传统检索行不行呢?更不行。三个代表性 Embedding 模型的表现几乎等于盲猜,因为个人相册中存在大量视觉高度相似的照片,传统检索会把所有 “看起来像” 的图片一股脑返回,完全无法区分 “满足上下文约束的真正目标” 和 “来自其他事件的干扰项”。这不是模型不够强的问题,而是范式本身的天花板。
但更值得关注的,是这些模型到底 “笨” 在哪里。研究团队对失败案例进行了系统性的人工分析,发现了一个清晰的结论:感知能力已经不是主要短板,规划和推理才是。
具体来说:最大的错误类型是推理出错,占所有错误的 36% 到 50%。模型已经找到了正确的线索,却在执行多步计划的过程中迷了路、丢了约束、或者过早停了下来。其次是视觉判别失败,比如把不同角度拍摄的同一座建筑误判为两座不同的建筑。AI 不是看不见答案,而是在推理的半路上把答案弄丢了。
还有几个值得进一步关注的发现:
跨事件推理是核心瓶颈:强模型在单个事件内的搜索明显优于跨事件搜索(如 Claude-Opus-4.5 的表现直接打了八折),而弱模型则是一视同仁地差。这说明一旦基本的 agent 能力建立起来,真正拉开差距的是长程的跨事件关联发现能力。
搜得更准不等于答得更好:将检索用的 Embedding 模型从小换到大,各模型表现并不一致,有的提升、有的反降,但总的差异不大。核心挑战不在于搜索本身,而在于如何对搜到的结果进行正确的推理和筛选。
模型们有着做对的潜力:通过 Best@k 和 Majority Voting 等方式测试,可以发现总分会随着测试次数的增加而提升。这表明模型在多次尝试中是有可能得到正确结果的,但是如何释放他们的潜力有待后续工作的继续探索。
回到最开始的问题,“找到那次看完那场烟花秀的几天后,我去海边拍的那些照片”。DeepImageSearch 告诉我们,这不是一个更好的 Embedding 能解决的问题,而是一个需要理解你人生叙事结构的推理问题。
这篇工作的贡献可以归纳为三件事:提出了从独立语义匹配到上下文推理的图像检索新范式;构建了第一个评估这种能力的高质量基准 DISBench;并通过 ImageSeeker 框架的系统探索,揭示了当前最强模型在规划、状态管理和长程推理上的关键短板。
当 AI 真正学会在我们的视觉历史中 "读懂" 事件之间的脉络、串联碎片化的记忆线索,相册搜索将不再只是一个工具功能,而会成为一个真正理解你人生故事的记忆伙伴。
通往这个时代的路已经被打开,但显然,我们还有很长的路要走。
作者简介:
本工作第一作者邓琛龙,目前就读于中国人民大学高瓴人工智能学院,博士四年级,目前研究方向聚焦于高效长上下文语言模型与深度搜索智能体。在NeurIPS、ACL、EMNLP、WSDM等国际顶级会议和期刊发表多篇论文,曾担任ACL 2025和EMNLP 2025审稿周期的领域主席。
本文的通信作者窦志成,中国人民大学高瓴人工智能学院长聘教授、博士生导师、副院长。主要研究方向为信息检索、大模型、智能体、大模型检索增强、AI搜索、司法智能等。在国际知名学术会议和期刊上发表论文200余篇,带领团队研发涉外法治大模型,开源大模型检索增强工具包FlashRAG、信息智能体系列工作累计获得GitHub星标1万余枚。
文章来自于“机器之心”,作者 “邓琛龙”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
