# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
“把水果放进盘子里”——机器人看懂了指令,开始执行,却在最后关头抓偏了。
这不是能力不够,而是它在关键时刻“走神了”。
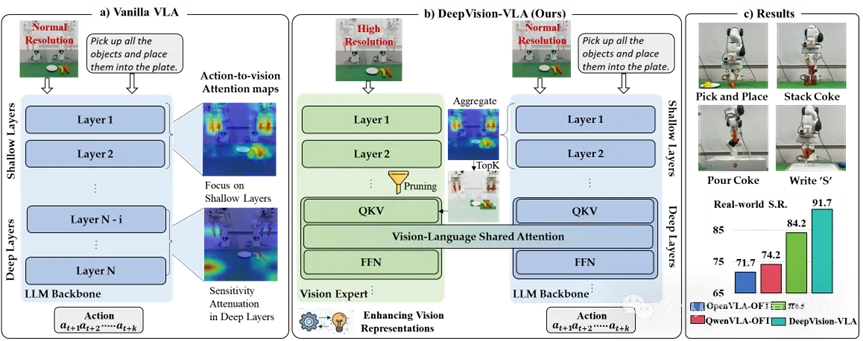
至简动力、北大、港中文的研究团队发现:VLA模型在深层动作预测时,对关键视觉区域的依赖会持续下降。换句话说,模型不是一开始看不清,而是越到后面越容易“丢”掉关键视觉证据。
研究团队提出的DeepVision-VLA框架,给VLA装上一个即插即用的“视觉增强器”:用视觉基础模型在深层注入高质量特征,同时让浅层的动作注意力来指导筛选哪些视觉信息值得传下去。
效果在仿真和真实任务中都有体现:RLBench模拟器上平均成功率83%,真实世界任务91.7%,相比Pi0.5分别提升18%和7.5%。在未见过的背景和光照条件下,性能依然稳定。

近日,至简动力、北京大学计算机学院多媒体信息处理国家重点实验室、香港中文大学,提出了DeepVision-VLA:一种面向机器人操作的视觉增强VLA框架。
研究核心目标不是简单再加一个视觉模块,而是回答一个更本质的问题:
当VLA在深层动作决策时逐渐“看不清”关键目标,能不能把高质量视觉信息重新注入进去?
围绕这个问题,研究团队首先系统分析了多个代表性VLA模型内部的视觉利用机制,发现其深层动作预测对关键视觉token的敏感性持续下降;随后提出了Vision-Language Mixture-of-Transformers(VL-MoT)框架,以及Action-Guided Visual Pruning(AGVP)策略,在保持计算开销可控的前提下,让模型在关键时刻重新聚焦任务相关区域。
最终,DeepVision-VLA在仿真与真实机器人任务中都取得了显著提升:在RLBench模拟器上达到83%平均成功率,在真实世界任务中达到91.7%平均成功率,相较于Pi0.5分别有18%和7.5%的成功率提升。
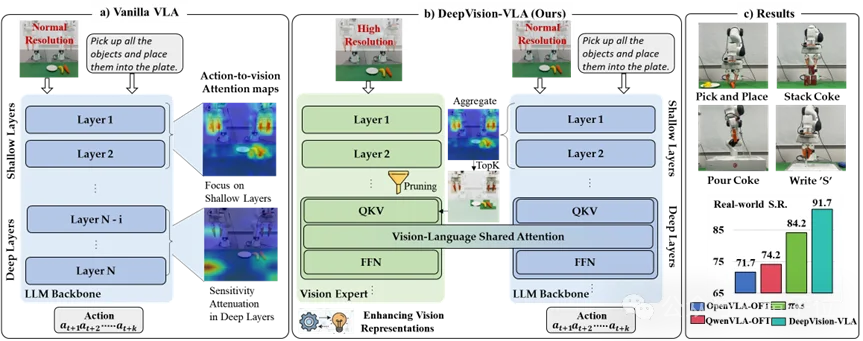
(a)在原始VLA模型中,模型对任务相关视觉token的依赖会随着层数加深而逐渐减弱,从而导致深层动作预测对视觉信息的敏感性下降。
(b)针对这一问题,DeepVision-VLA提出视觉-语言混合Transformer框架,将视觉基础模型的多层级视觉特征注入VLA主干网络深层,以增强模型对精细复杂操作所需视觉信息的表征能力。
(c)基于上述设计,DeepVision-VLA在多项真实世界操作任务中取得了更优的性能。
过去很多工作都在增强VLA的视觉能力,例如引入视觉提示、增加辅助视觉目标、融合更多模态信息,或者通过未来状态建模提升动作生成效果。
但这些方法大多默认了一件事:
只要视觉信息被编码进模型,后续动作预测自然会持续利用这些视觉证据。
这件事其实并不显然。VLA的动作生成通常依赖由多层Transformer堆叠而成的LLM backbone。从结构上看,视觉信息往往只在前部进入模型,随后需要随着层间传播不断参与后续动作预测。
因此,一个更本质的问题是:视觉信息在VLA内部究竟是如何被利用的?它会不会在深层逐渐被削弱?
为回答这个问题,研究团队没有把VLA当作“黑盒”,而是对其内部层级行为进行了系统分析。
团队选择了三类具有代表性的VLA模型:
OpenVLA
π
QwenVLA-OFT
它们覆盖了不同的LLM backbone、模型深度和动作生成范式。研究团队的目标不是比较谁更强,而是回答一个更基础的问题:当模型一层一层往后推理时,动作预测到底还在多大程度上依赖任务相关视觉区域?
为了更准确地理解VLA的内部视觉利用机制,团队设计了两个互补的probing实验:
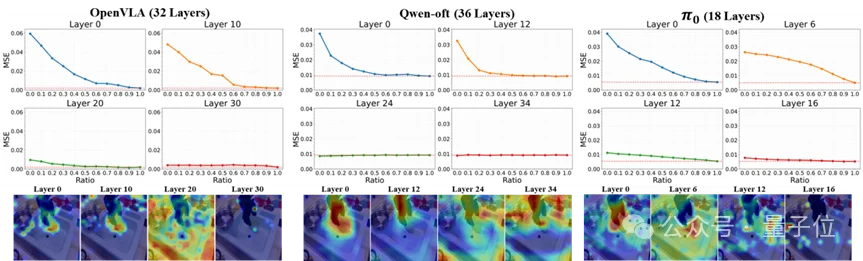
上:在不同层对ROI视觉token进行掩蔽时,动作预测误差(MSE)的变化。在浅层掩蔽关键视觉token会显著恶化动作预测,而这一影响在深层逐渐减弱。
下:不同层的Grad-CAM注意力可视化结果。浅层注意力主要聚焦于任务相关区域,而在深层中逐渐趋于弥散,说明模型对关键视觉区域的grounding能力随层数加深而减弱。
浅层动作表示仍然建立在较强的任务视觉grounding之上,但到了深层,动作预测对关键视觉证据的依赖开始减弱。
换句话说,问题不是模型完全“看不见”,而是:
越到后面,动作决策越不再强依赖最关键的视觉区域。
仅靠可视化还不够。贡献图可以显示“看起来模型在关注哪里”,但它不能直接定量说明:这些区域对动作预测究竟有多重要。因此,团队进一步设计了一个更严格的层级干预实验:ROI visual token masking。
实验结果同样呈现出稳定一致的层级趋势:
这一结果比单纯的可视化更进一步,定量证明了:任务相关视觉线索在VLA深层中被逐渐“低利用化”了。
基于上述分析,团队的目标就变得非常明确:
既然问题出在深层动作预测对关键视觉区域不再敏感,那么改进方向就不应只是增强输入视觉编码,而应直接增强深层的视觉表征能力。
基于这一思路,研究团队提出DeepVision-VLA。其核心思想是:在保留原始VLA结构的基础上,引入一个更强的视觉专家,并让它在深层与VLA backbone协同工作,从而在最容易发生视觉退化的位置补充高质量视觉证据。整个方法由两个关键设计组成:
Vision-Language Mixture-of-Transformers(VL-MoT)
Action-Guided Visual Pruning(AGVP)
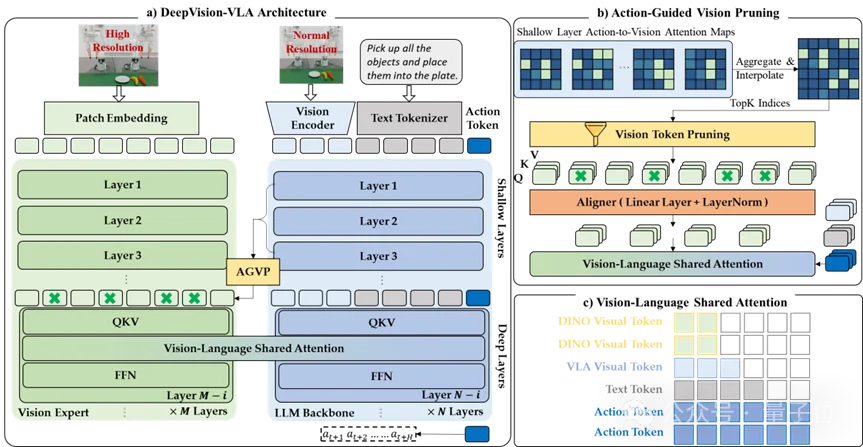
(a)通过所提出的视觉-语言混合Transformer(Vision–Language Mixture-of-Transformers,VL-MoT)框架,将高分辨率视觉专家与LLM主干网络进行耦合,其中LLM深层与视觉专家共享注意力,从而增强动作预测中的视觉grounding能力。
(b)利用LLM浅层的action-to-vision注意力聚合得到任务相关区域,并在特征融合前据此对视觉专家token进行剪枝。
(c)视觉专家token采用双向注意力机制,以保留其预训练表征能力;VLA token对prompt token采用因果注意力,对action token采用双向注意力,以支持并行的动作预测。
该方法建立在自定义基线QwenVLA-OFT之上。在此基础上,团队引入一个高分辨率视觉专家DINOv3,并提出Vision-Language Mixture-of-Transformers(VL-MoT)。它的核心不是把视觉专家特征直接拼接到输入,而是让视觉专家和VLA深层在attention层面进行更紧密的协同。
具体来说,VL-MoT将视觉专家的多层特征与VLA深层进行对齐,并在深层模块中引入Vision-Language Shared Attention。在这一机制下:
这也是VL-MoT与常见早期融合方式的根本区别。问题不只是“有没有用额外视觉特征”,而是:
这些特征有没有在正确的位置、以正确的方式参与动作生成。
尽管高分辨率视觉专家能够提供更强表征,但如果把全部token全部送入深层,也会带来两个问题:
因此,团队进一步提出Action-Guided Visual Pruning(AGVP)。AGVP的核心思想来自前面的probing结果:虽然深层视觉敏感性下降,但浅层仍保留着较强的任务视觉grounding。因此,研究团队利用浅层的action-to-vision响应来估计“当前动作真正关心哪些视觉区域”。
具体来说,AGVP会:
这样一来,深层获得的不是“整张图的全部视觉信息”,而是:由浅层动作grounding筛选过的高价值视觉证据。
这一步非常关键,它不仅降低了冗余和计算开销,也使视觉增强真正与“当前动作需要什么”对齐。
团队在RLBench的10个机器人操作任务上系统评估了DeepVision-VLA。结果显示,模型达到83%的平均成功率,并显著超过多种代表性基线。更重要的是,这种提升在视觉要求更高的任务中尤其明显。例如需要更强空间定位能力和交互判断能力的任务,性能提升往往比平均提升还要更大。这说明DeepVision-VLA并不是简单提高平均分,而是真正增强了模型在复杂视觉场景中的操作能力。
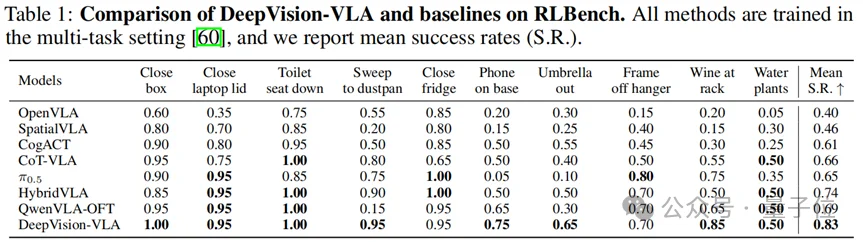
所有方法均在多任务设置下进行训练,评价指标为平均成功率

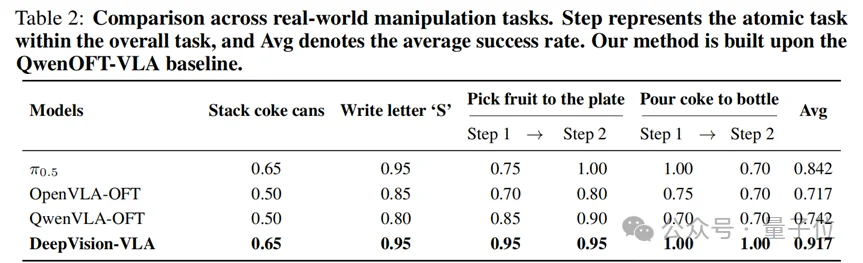
在真实世界实验中,团队基于真实机器人平台评估了多项复杂操作任务,例如抓取放置、堆叠、书写和倒液体等。
这些任务不仅要求识别目标,还要求模型持续跟踪边界、相对位置以及机械臂与物体之间的交互关系。
最终,DeepVision-VLA在真实世界任务中取得了91.7%的平均成功率,展现出更强的精细操作能力和执行稳定性。这一结果说明,深层视觉增强不仅在仿真里有效,也能迁移到真实世界复杂操作中。




为了验证方法是否真正提升了视觉建模能力,团队进一步测试了零样本泛化性能,重点考察两类常见扰动:
未见背景
未见光照条件
结果显示,DeepVision-VLA在这些扰动下仍能保持更稳定的操作表现。这表明,该方法增强的不只是任务记忆,而是模型对任务关键视觉结构的稳定提取能力。也就是说,DeepVision-VLA带来的不是“在固定环境里做得更熟练”,而是:
环境变了,模型依然更容易看对关键区域。
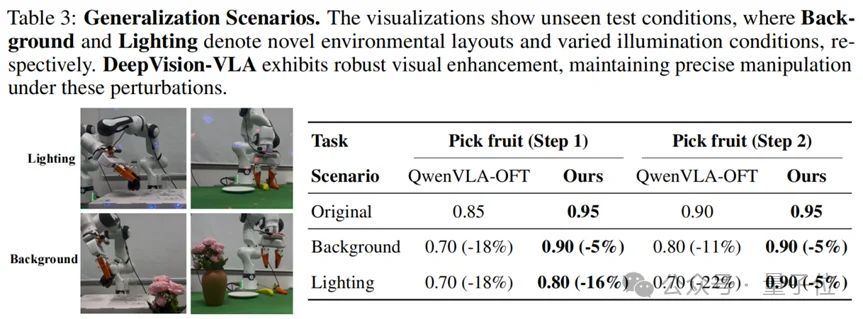
图中展示了未见测试条件,其中Background和Lighting分别表示新的环境布局和变化的光照条件。DeepVision-VLA在这些扰动下仍表现出稳健的视觉增强能力,并能够保持精确的操作性能。
论文链接:
https://arxiv.org/pdf/2603.15618v1
项目主页:
https://deepvision-vla.github.io/
文章来自于“量子位”,作者 “DeepVision团队”。



【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
