
VLA不够了?触觉,将改写具身智能新格局
VLA不够了?触觉,将改写具身智能新格局2026 年,「数据」正成为具身智能竞赛的新焦点,京东、百度等科技巨头纷纷入局。然而,喧嚣之中,一个根本问题悬而未决:什么样的数据,才是具身智能真正需要的?
来自主题: AI资讯
7746 点击 2026-05-06 14:27
 搜索
搜索
2026 年,「数据」正成为具身智能竞赛的新焦点,京东、百度等科技巨头纷纷入局。然而,喧嚣之中,一个根本问题悬而未决:什么样的数据,才是具身智能真正需要的?

智元机器人的办公室里,最近员工们一上班就能看到机器人熟练地切着水果:这么全面的能力是如何做到的?答案是直接在真实环境中搞大规模分布式强化学习训练。它们使用的是全新的具身智能训练范式:面向通用机器人策略的分布式多机强化学习(LWD)。这一套技术捅破了当前VLA的「天花板」。

今天,大洋彼岸,硅谷自动驾驶领域的秘密,终于有大佬站出来分享了。如果你对自动驾驶、人形机器人中炙手可热的 VLA、世界模型还有疑惑,全球“物理 AI” 领域头部的基础设施平台 Applied Intuition 两位创始人:CEOQasar Younis、CTO Peter Ludwig的分享可真的是太对口了。

就在这一背景下,银河通用联合清华北大英伟达等众多机构联合发布了跨本体「隐式世界-动作基础模型」LDA-1B,将目光投向了具身智能 Scaling Law 的这个终极命题:如何让模型有效利用互联网规模的异构数据。

就在刚刚,自变量机器人发布了全球首个世界统一模型架构的具身智能基础模型:WALL-B。基于世界统一模型,WALL-B解决了传统VLA架构在模块间数据搬运上的bug点——
今天凌晨,Physical Intelligence发布了全新的VLA模型π0.7,狠狠敲了世界模型一记闷棍。π0.7第一次在机器人领域证明了Compositional Generalization(组合泛化),且VLA。
最近,具身智能圈被 Generalist CEO 的一篇长文《Going Beyond World Models & VLAs》刷屏。文章抛出了一个看似振聋发聩的观点:目标远比工具标签更重要。与其陷入 “我们到底是在做 VLA(视觉 - 语言 - 动作模型)还是世界模型(World Model)” 的教条之争,不如回归本源:让机器高效、准确地作用于物理世界。
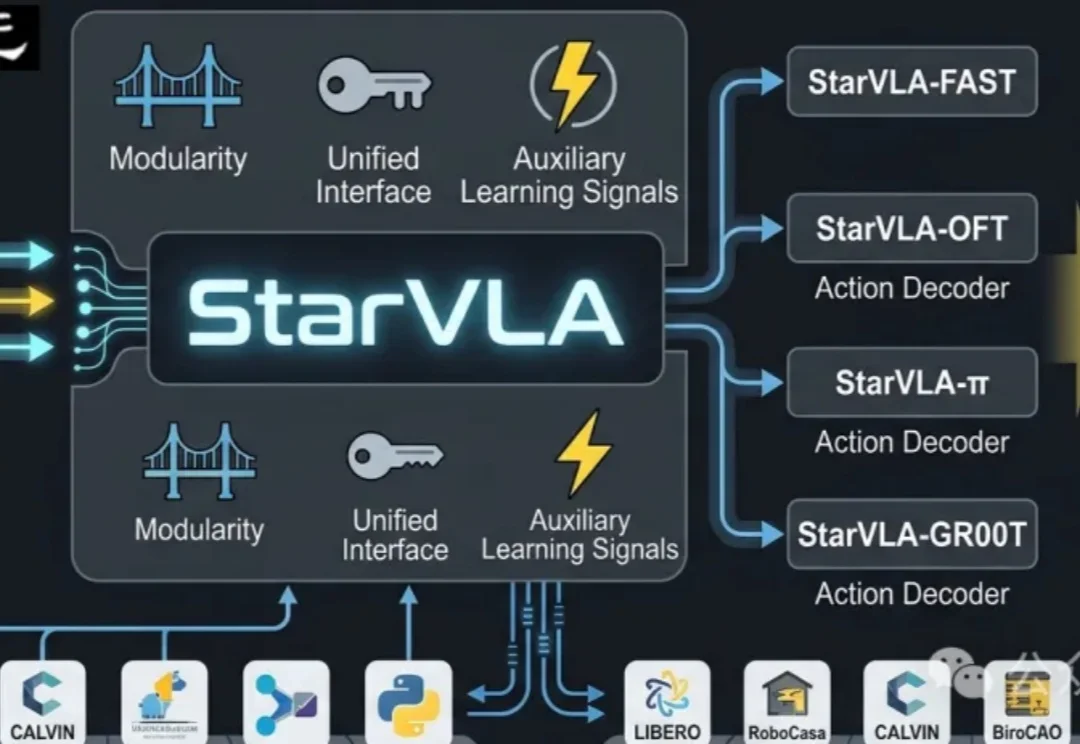
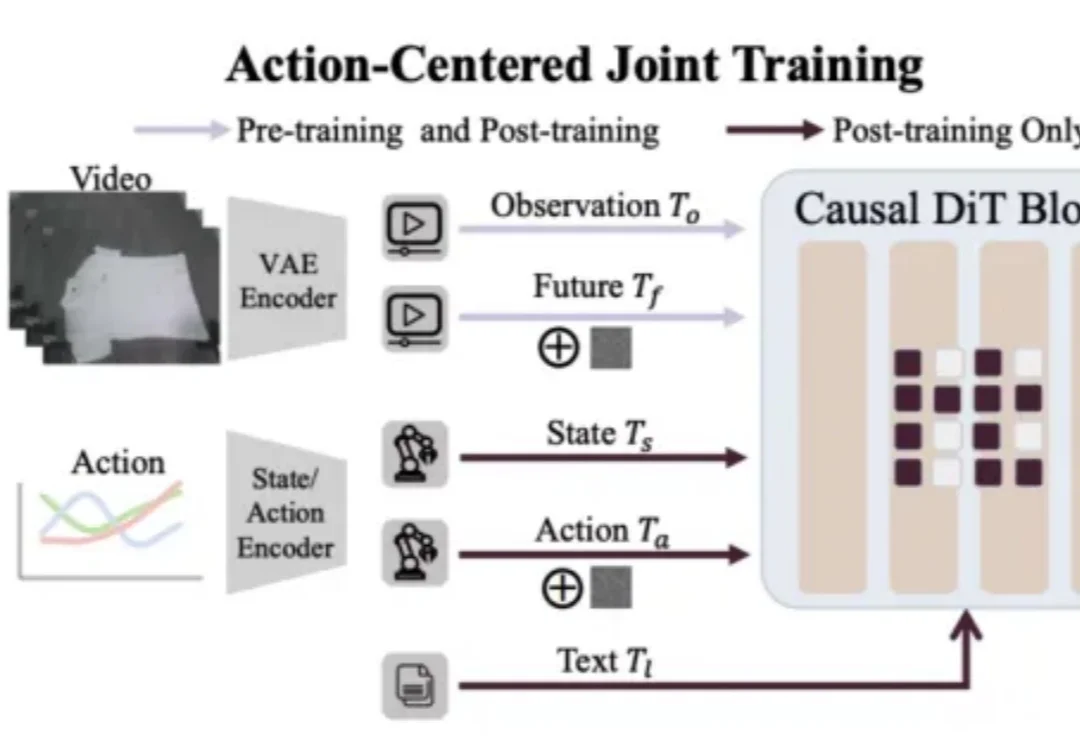
当前具身智能的VLA(Vision-Language-Action)赛道正陷入典型的「碎片化」泥潭:不同团队采用异构的动作解码范式、强耦合的数据管线、互不兼容的评测协议,导致方法难以横向对比,复现成本极高。

这个月,具身智能领域又卷出新高度:硅谷独角兽公司 Generalist AI 发布全新一代基础模型 GEN-1,将机器人包装手机、折纸箱这些活的平均成功率直接拉到了创纪录的 99%,折纸箱的速度更是飙到了以前的三倍(34s vs 12.1s)。

从 2024 年底的关于潜在空间的早期探索,再到 2025 年底和 2026 年初的相关研究爆发,潜空间范式正在彻底重塑大模型 (LLMs, VLMs, VLAs 等延伸模型) 的底层设计逻辑。