# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
几何问题,真的只是“推理难”吗?
近年来,视觉语言模型(VLMs)在图文问答、表格理解、数学应用题等多模态任务上取得了显著进展。
但当问题变成几何图形时,它们的表现却往往明显下降。
为什么?
近日,来自光明实验室与清华大学的研究团队深入剖析了多个主流模型的错误案例,观察到一个值得关注的现象:
当前VLM在几何问题上的失败,很大程度上暴露出其几何感知错误(perceptual errors)的短板,而这一核心因素在现有研究中往往未被单独系统分析。
换句话说,在不少情况下,模型并不是不会推理,而是在更早阶段——对图形结构的识别已经出现偏差。
常见问题包括:
这些问题发生在推理之前,却直接影响后续逻辑链条。

现有几何benchmark通常采用端到端评测方式:
图像+问题→自然语言答案
仅判断“是否答对”。
这会将感知错误与推理错误混合统计,难以定位能力瓶颈。
为此,研究团队提出了GEOPERCEIVE
这是首个面向几何感知能力的独立评测框架。
过去的基准关注:模型是否“答对”。
GEOPERCEIVE关注:模型是否“看对”。
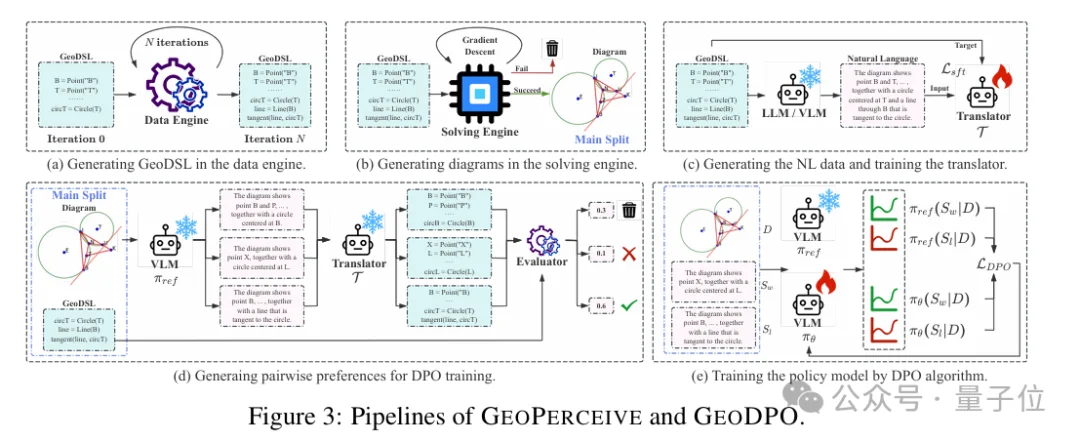
研究团队设计了一种几何领域专用语言——GeoDSL,用于结构化表示:
几何图形首先由程序自动生成,再渲染为图像。
模型输出的自然语言结果会被翻译为结构表示,并进行精确匹配。
这种设计带来两个关键优势:
GEOPERCEIVE采用:
评估粒度从“答案是否正确”,细化到:
每一个几何元素、每一条结构关系是否识别准确。
这使研究团队能够精确定位模型在结构识别层面的能力瓶颈。
在诊断出几何感知短板之后,一个自然的问题是:
如何在不破坏自然语言表达能力的前提下,引入结构级优化信号?
直接监督模型生成结构化程序(SFT)容易带来分布偏移,并对token顺序高度敏感。
因此,研究团队提出:
GEODPO:Translator-Guided Reinforcement Learning
整体流程如下:
自然语言输出
→ 专用翻译器(NL→GeoDSL)
→ 结构级精确评分
→ 构造偏好对
→ DPO优化
模型依然输出自然语言,但优化信号来自结构匹配分数。
这种方式具有三个优势:
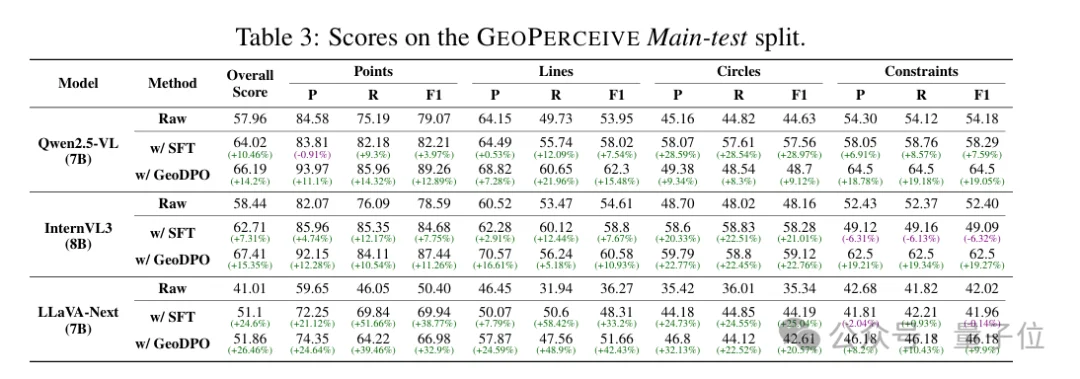
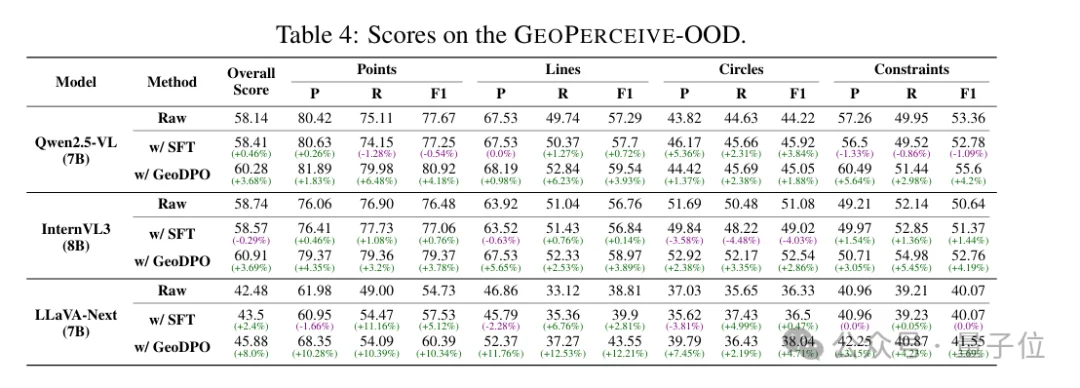
研究团队在多个主流视觉语言模型上进行了系统评测。
在分布外测试集上:
这提示结构化奖励在分布偏移场景下可能具备更好的稳定性。
在MathVista等几何推理benchmark上,研究团队观察到:
当结构识别准确度提高时,整体推理表现往往同步改善。
这一现象表明,底层结构表示质量可能是影响几何推理性能的重要因素之一。
研究团队提出了:
GEOPERCEIVE——首个面向几何感知能力的独立评测框架
GEODPO——基于结构化奖励的优化方法
通过将几何结构识别从端到端推理任务中显式拆分出来,研究团队能够更清晰地分析模型在“感知—推理”链条中的能力分布。
实验结果显示:
几何感知能力可能是影响几何推理表现的重要因素之一,而结构化强化学习提供了一种稳定、可解释的优化路径。
更重要的是,这项工作提供了一种研究范式:
几何场景由于其高度结构化特性,为研究多模态模型的底层表示能力提供了一个理想入口。
类似思路或许可以扩展至:
在多模态模型逐步迈向更可靠结构理解的过程中,几何,也许不仅仅是一类任务,而是理解模型“是否真正看懂结构”的关键窗口。
论文链接:
https://arxiv.org/pdf/2602.22703
文章来自于"量子位",作者 "光明实验室&清华大学"。


