# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
随着机器人操作从短程、单步技能逐步走向长程、富接触、需要持续协调与恢复能力的复杂任务,传统以二元成功率为核心的评测方式开始暴露出明显局限。它能够回答 “任务是否完成”,却难以回答 “策略推进到了哪里”“执行过程是否高效稳定”“失败究竟发生在什么阶段”。
围绕这一问题,来自中国科学院自动化研究所、北京大学和智源研究院等机构的研究人员提出 PRM-as-a-Judge:不再只根据终局结果评价策略,而是从轨迹视频中恢复任务相关的连续进度信号,并据此对执行过程进行细粒度审计。该框架的核心包括任务条件化的进度势能、OPD 三层指标体系,以及用于验证评估器细粒度分辨能力的 RoboPulse 基准。

在现有具身智能研究中,策略评估仍然高度依赖二元成功率。对于短程、结构清晰的任务,这一指标能够提供一种直观的比较方式;但当任务逐渐演化为长程、多阶段、强交互的复杂操作时,二元成功率所能提供的信息开始明显不足。
这种不足主要体现在两个方面。
因此,对于长程任务来说,决定策略优劣的关键已经不再只是终点上的 “成功” 与 “失败”,而是执行过程中究竟推进到了哪一阶段、推进得是否稳定,以及失效究竟发生在什么位置。
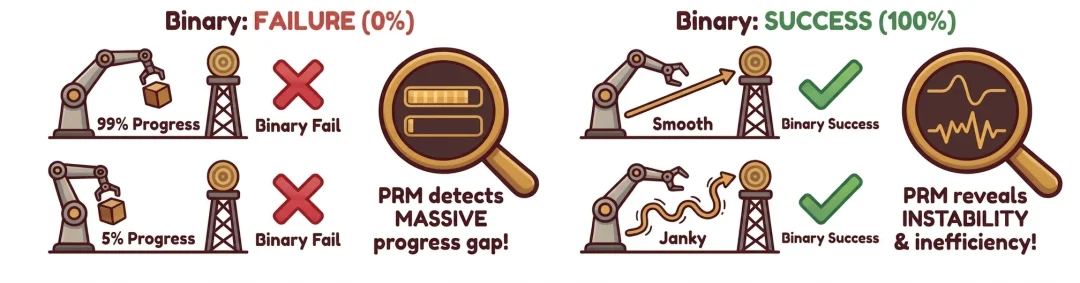
相同的二元标签下隐藏着截然不同的物理执行逻辑。失败可能发生在任务的任何阶段(从 5% 到 99% 进度),而成功亦有 “平稳高效” 与 “反复修正” 之分 。
为了恢复被二元标签压缩掉的轨迹信息,作者将评测重心从 “结果” 转向 “过程”。在真实物理场景中,研究者通常拿不到模拟器中的特权信息,例如精确位姿、接触力或完整状态变量。
因此,这项工作没有把评测建立在这些理想化信号上,而是选择了一条更具现实意义的路径:直接根据视觉状态的演化来刻画任务进度。
具体来说,作者为给定任务条件下的每个状态分配一个位于 [0,1] 区间上的进度势能 Φ。一旦有了这个势能表示,一条原本只对应 “成功/失败” 标签的执行轨迹,就可以被表示为一条随时间变化的连续进度曲线。这样,研究者看到的就不再只是一个终点结果,而是一条可比较、可分解、可诊断的过程信号:轨迹推进得有多深,推进过程中是否反复回退,哪些阶段容易停滞,都可以被显式刻画出来。
在这一框架下,作者进一步把 “密集评测” 形式化为两个核心性质。
第一个是 macro-consistency。它要求评测结果在时间上具有可加性和路径一致性:同一段执行过程,无论如何切分为更短的时间片,其累积进度都应保持一致。换句话说,评测结果不能随着轨迹分段方式的改变而漂移。
第二个是 micro-resolution。它要求评测器能够识别细粒度、任务相关的状态变化,而不是只对粗粒度视觉差异做出反应。
作者进一步指出,在其采用的 potential-based formulation 中,只要评测器能够在固定任务上下文下,为每个状态赋予一个可比较的标量进度值,并将任意时间区间上的进度定义为两个状态势能的差值,那么宏观上的时间加性与分段不变性就可以直接得到保证。PRM judge 在这里被作者视为这种表述的一个自然且实用的实现:它通过任务条件化的标量进度输出,为 OPD 指标提供统一的进度坐标。
相比之下,许多依赖相对比较或相似度启发式的方法,往往并不显式对应这样一个全局一致的势能表示,因此在不同时间段、不同视角或不同比较基准下,更容易出现尺度漂移或路径相关的问题。至于 micro-resolution,则不能仅由这种结构性定义自动推出,而仍需通过专门的诊断基准进行检验。
在进度势能 Φ 的基础上,作者构建了 OPD(Outcome–Process–Diagnosis) 指标体系,用于把一条复杂执行轨迹分解为三个层次的审计结果。Outcome 层回答 “推进到了哪里”,Process 层回答 “推进得怎么样”,Diagnosis 层回答 “如果没做好,问题主要出在哪里”。这也是 PRM-as-a-Judge 的核心输出形式。
在 Outcome 层,作者采用 MC 和 MP 两个指标描述推进深度。其中,MC(Milestone Coverage)用于刻画轨迹到达了哪些关键里程碑,MP(Max Progress)则记录整段轨迹曾达到的最高连续进度值。它们共同回答的是:这条轨迹究竟走到了什么位置。
在 Process 层,作者定义了 PPL(Path-weighted Progress Length),用于衡量推进是否高效、是否存在明显冗余。PPL 越高,说明轨迹越接近单调推进、回绕和反复修正越少。它对应的是 “同样推进到某个位置,不同策略的路径质量是否一致” 这一问题。
在 Diagnosis 层,作者使用 CRA 和 STR 刻画两类常见失效机制。CRA(Cumulative Regret Area)衡量轨迹相对于历史最佳状态的累计回退程度;STR(Stagnation Ratio)则衡量轨迹中 “几乎没有任务相关推进” 的时间占比,用于反映犹豫、等待或停滞。与单一成功率相比,OPD 的价值不在于 “多报几个数”,而在于它把执行过程重写为结构化、可诊断的行为信号。
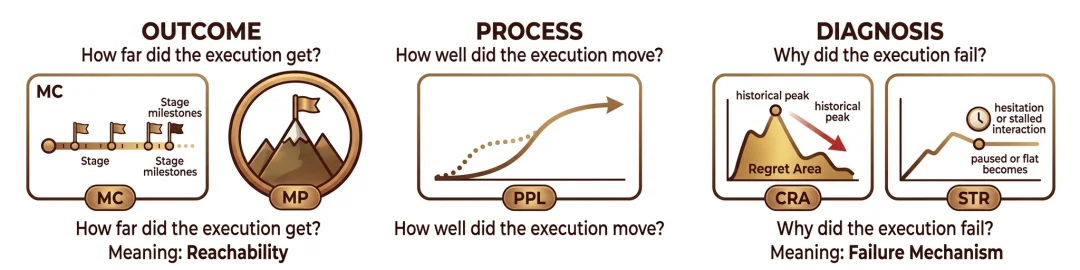
OPD 将一次执行分解为三层信号:Outcome 刻画推进深度,Process 刻画执行质量,Diagnosis 刻画失败机制。五个核心指标 MC、MP、PPL、CRA 与 STR 分别对应阶段可达性、最大进度、路径效率、回退代价与停滞比例。
有了理论上的性质约束和过程级指标之后,接下来的关键问题是:评估器是否真的能看懂微小但任务相关的物理变化?
为此,作者构建了 RoboPulse。论文明确指出,在该框架下,macro-consistency 由势能形式在结构上保证,而 micro-resolution 则需要通过受控实验进行检验;RoboPulse 正是围绕这一点设计的诊断基准。
RoboPulse 将进度评测转化为一个成对判断问题:给定来自同一执行轨迹的两个状态,评估器需要判断后一个状态相对于前一个状态,是 “前进” 还是 “回退”。这种设计不依赖绝对进度标定,而是直接考察更本质的能力:当物理变化很细微时,评估器是否仍能稳定识别出进度方向。作者在构建基准时,先用关键帧把轨迹划分为语义一致的阶段,只保留进度单调的区间,过滤掉近静止、往复振荡和难以标注的片段,再在这些区间内按 Small、Medium、Large 三个 hop 范围采样样本。
从规模上看,RoboPulse 包含 1800 个成对进度判断样本,这些样本来自 1622 条执行轨迹、覆盖 816 个任务,并汇集了 7 个数据源。基准同时覆盖真实机器人、仿真、UMI 采集和人类第一视角等多种设置,并在不同相对进度跨度上系统考察评估器的分辨能力。
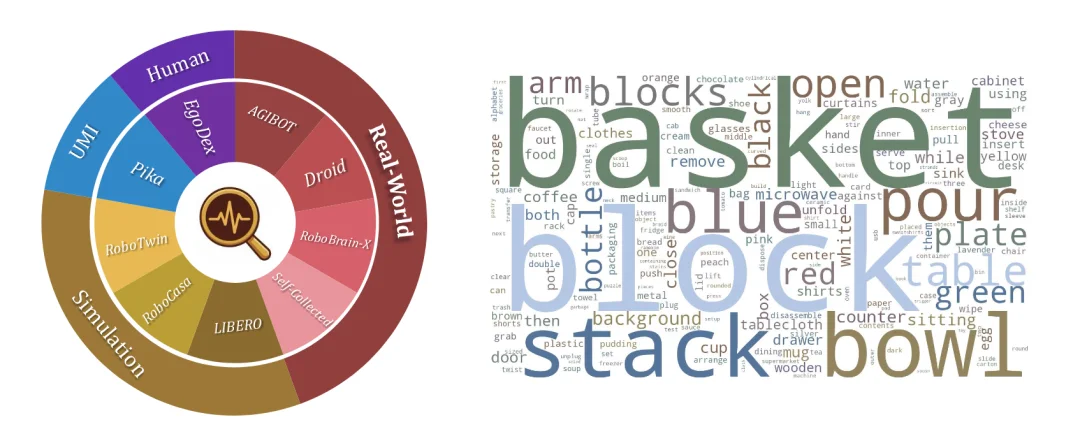
RoboPulse 涵盖了多个数据源和不同的本体型号,用于评估 judge model 的微观进度分辨能力。
在 RoboPulse 上,作者将 PRM-based judges 与两类常见替代方案进行比较:一类是基于 CLIP 的视觉相似度评测方法,另一类是通用多模态基础模型,如 Gemini、GPT-5.2。实验结果显示,PRM 在细粒度进度判断上整体表现更强。以 Robo-Dopamine 为例,其总体准确率达到 0.83;Gemini 为 0.66,Qwen3-VL-8B 为 0.59,而多种 CLIP 变体整体落在 0.46–0.59 区间。
更关键的是,在最具挑战性的 Small-hop 区间,优势会进一步扩大。Robo-Dopamine 的平均准确率达到 0.80;另外两个 PRM judge 也达到 0.61 和 0.63。相比之下,Gemini 在该区间为 0.54,GPT-5.2 为 0.47。论文据此指出,当比较尺度变得足够细时,粗粒度语义线索的帮助会下降,而真正与物理过程相关的进度监督会体现出更明显优势。
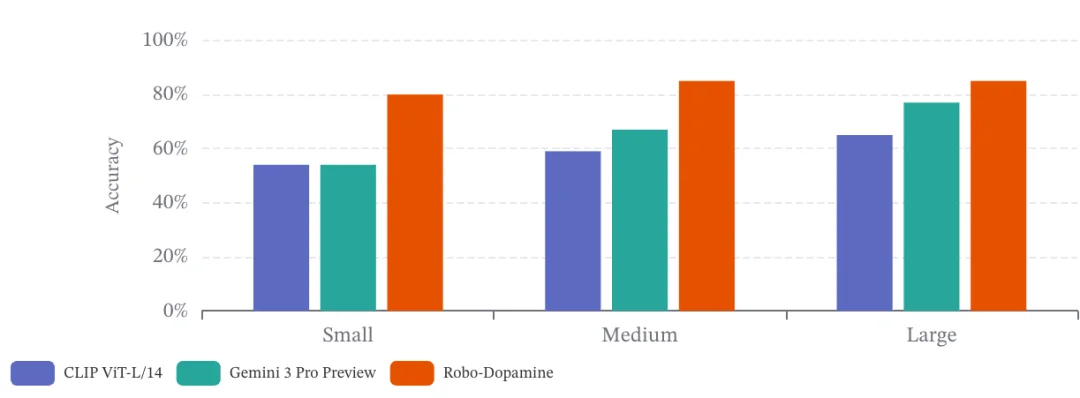
在 RoboPulse 基准上,PRM-based judges 在不同相对进度跨度下均表现出更强的分辨能力,在最困难的 Small-hop 区间优势尤为显著,证明其对细微、任务相关的物理状态变化具备极高的敏感性。
在验证了 judge 的 micro-resolution 之后,作者进一步将 PRM-as-a-Judge 应用于 RoboTwin 2.0 ,并选择了 5 类代表性的 policy 模型(DP、ACT、RDT、pi0、OpenVLA-OFT),在多个长程操作任务上统一评测,每个策略 - 任务组合进行 50 次 rollout。
6.1 失败究竟发生在什么阶段?
Outcome 层最直接的价值,是把 “失败” 进一步分解为不同阶段的失败。以 Blocks Ranking RGB 为例,大多数策略在早期阶段的可达性都不低:MC@25 落在 84–100 区间;但到了最终完成阶段,MC@100 只剩 0–8。这说明大量 rollout 并不是 “一开始就不会”,而是在已经取得相当推进后,集中失效在末段阶段。
更进一步,OPD 还能区分 “同样是零成功率” 但物理含义完全不同的策略。例如在同一任务上,pi0 的 MC@75 为 40,而 OpenVLA-OFT 的 MC@75 仅为 6,尽管两者的 MC@100 都接近于零。前者的失败通常更接近终点,后者则更容易在中早期阶段提前掉队。这类差异,在传统成功率下是不可见的。
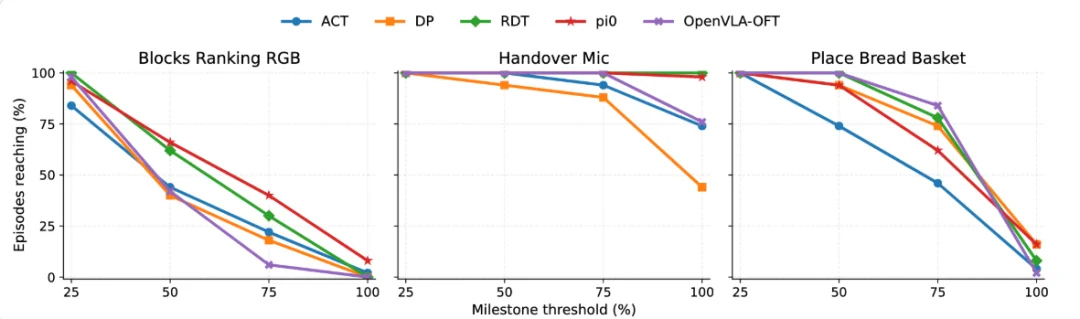
阶段性可达性揭示了 “最后一公里” 的差距,并将早期崩溃与近乎完全的故障区分开来。
6.2 成功与成功,并不等价
为了评价 policy model 在成功条件下的执行质量,作者选取了 Handover Mic 任务上成功的样本进行了分析。结果显示,DP 在成功样本中的 PPL 为 94.9,高于若干对比方法;同时其 CRA 仅为 0.26,也显著低于 OpenVLA-OFT 的 2.55。这意味着,DP 一旦进入成功轨道,往往能够以更高效率、更低回退代价完成任务。
但这并不意味着它在总体上最可靠。结合 Outcome 层结果可以看到,DP 在 Handover Mic 上的 MC@100 只有 44,而另外一些策略则达到 98 甚至 100。论文据此指出:成功条件下的高质量执行,不必然等于更高的总体可靠性。 有些方法在 “成功时” 做得非常漂亮,但它们在失败时,完全没有从错误中恢复的能力。
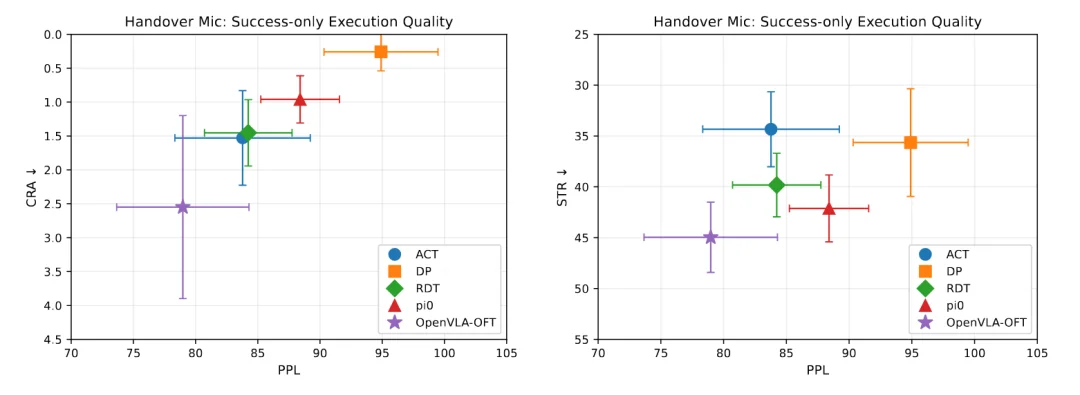
成功条件下的执行质量图:在成功样本内部,不同策略仍然可能呈现显著不同的执行质量。路径效率与回退代价共同表明:成功并不自动意味着高质量成功,高精度执行与整体可靠性也并不总是一致。
6.3 “失败” 也有不同机制
Diagnosis 层则把原本统一的失败标签,进一步拆解为不同的失效机制。以 Place Bread Basket 任务为例,OpenVLA-OFT 的 MP 达到 92.6,说明它常常能够推进到相当靠后的位置;但其 CRA 达到 26.3,显示出明显的晚期回退和恢复代价。与之相对,ACT 在该任务上的 MP 为 73.1,而 STR 达到 65.4,更接近一种早期停滞主导的失败模式。
类似地,在 Handover Mic 上,DP 的失败更偏向高停滞,即 STR 为 57.2;OpenVLA-OFT 则表现为更高的回退和较低效率,其 PPL 为 66.2,CRA 为 5.66。作者据此提出,OPD 给出的并不是简单的 “好 / 坏” 排序,而是一种可复现的 failure fingerprint:不同策略家族会在 OPD 空间中表现出相对稳定的失效画像,这种画像能够为后续改进提供更具针对性的方向。
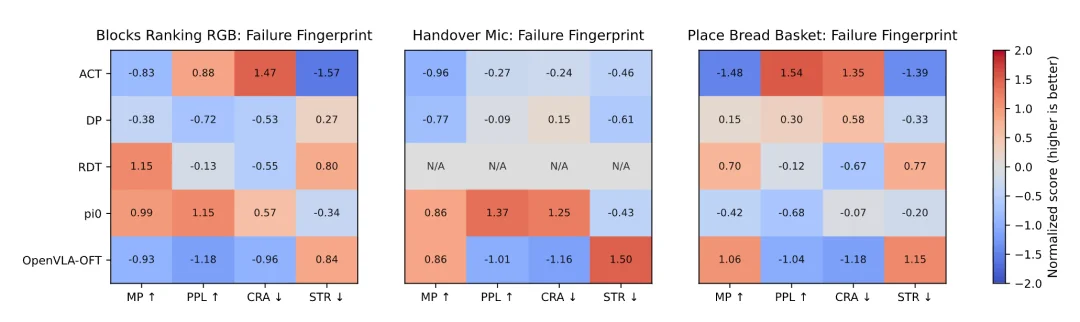
失败指纹图:在失败样本上,CRA 与 STR 将 failure 从单一终局标签进一步拆解为不同机制:有些策略更接近晚期失稳与明显回退,有些策略则更表现为长时间停滞和推进不足。相同的 “失败” 标签背后,可能对应完全不同的原因。
6.4 差异体现在指标联合画像中
作者也将 OPD 框架应用到 RoboChallenge Table30 公开榜单比较中,使用 Robo-Dopamine-2.0-8B-Preview 作为评估器,对不同模型在真实执行中的轨迹特征进行统一分析。
从 OPD 指标下的 RoboChallenge 总榜来看,可以清楚地发现:真正拉开方法差距的,往往不只是 “最后是否完成”,而是推进深度、执行质量与失败形态这几类信号的共同作用。在头部模型中,DM0 的优势并不只是更常完成任务,而是同时体现在推进深度和执行质量上:它不仅拥有最高的 Avg MC@100(62.0),也同时在 Avg MP(70.3)和 Avg PPL(31.2)上领先。这说明它的领先并不是单纯依赖更高的终局完成率,而是同时来自更深的平均可达性和更高的执行效率。
相比之下,GigaBrain-0.1 虽然在 Avg MP 上几乎与 DM0 持平,但 Avg PPL(26.2)明显更低,说明它虽然能够推进到接近的位置,路径质量却相对较差。因此,OPD 所刻画的并不只是谁成功更多,而是谁的成功更接近高效、平稳、少修正的成功。
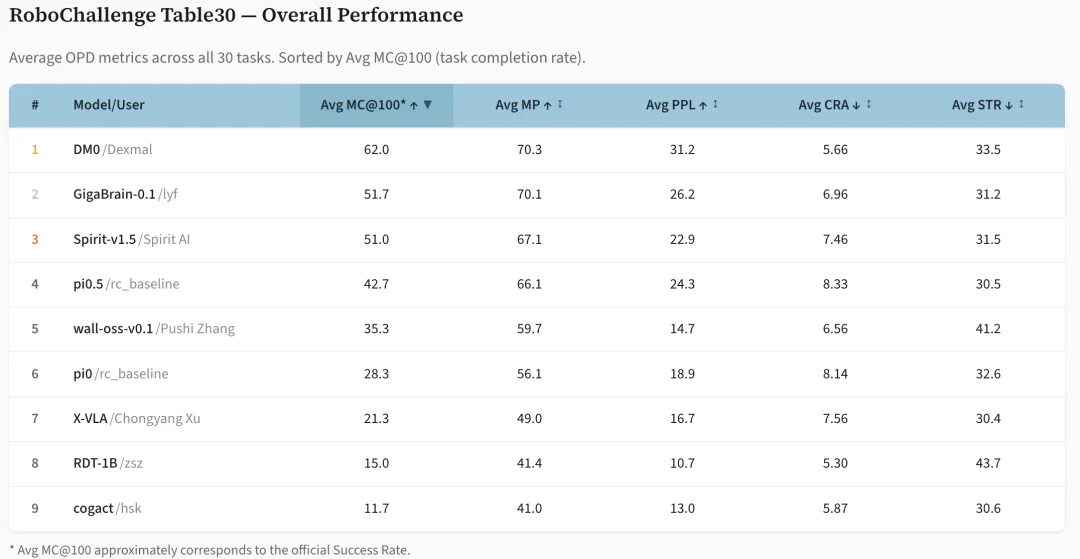
OPD 指标下的 RoboChallenge Table30 总榜:DM0 拥有最高的 Avg MC@100,Avg MP 和 Avg PPL,其成功来自更高水平的推进深度和执行质量;GigaBrain-0.1 则呈现出 “最后一公里” 差距。详细指标见官方博客:https://prm-as-a-judge.github.io/leaderboard.html
与之相比,GigaBrain-0.1 则呈现出一种更典型的 “最后一公里” 差距。它的 Avg MP 达到 70.1,与 DM0 的 70.3 几乎相同,但 Avg MC@100 却只有 51.7,相比 DM0 的 62.0 明显更低,说明两者并不是在 “能否把轨迹推进到高进度区间” 上存在本质差异,而是在 “能否把已经获得的高进度稳定转化为最终完成” 上拉开了距离。把 Avg MP 和 MC@100 一起纳入分析后就会发现,GigaBrain-0.1 在末段收束上仍然存在缺口。
值得注意的是,回退、停滞与推进深度不能被割裂地理解。RoboChallenge 中 RDT-1B 的 Avg MC@100 只有 15.0,但 Avg CRA 却仅为 5.3,是总榜中最低的一档;这并不意味着它的执行更平滑,而更说明其整体推进深度本就有限,因此较少出现推进到后期再明显回退的情况。
相对地,wall-oss-v0.1 的 Avg MP 仍达到 59.7,说明它并非完全缺乏推进能力,但其 Avg STR 高达 41.2,则显示出更明显的停滞和低效推进。低回退或中等进度本身都不足以说明执行更强或更顺;OPD 的价值不在于提供彼此孤立的若干指标,而在于通过 Outcome、Process 与 Diagnosis 三层信号的联合刻画,更完整地揭示轨迹的推进状态、执行质量与失效机制。
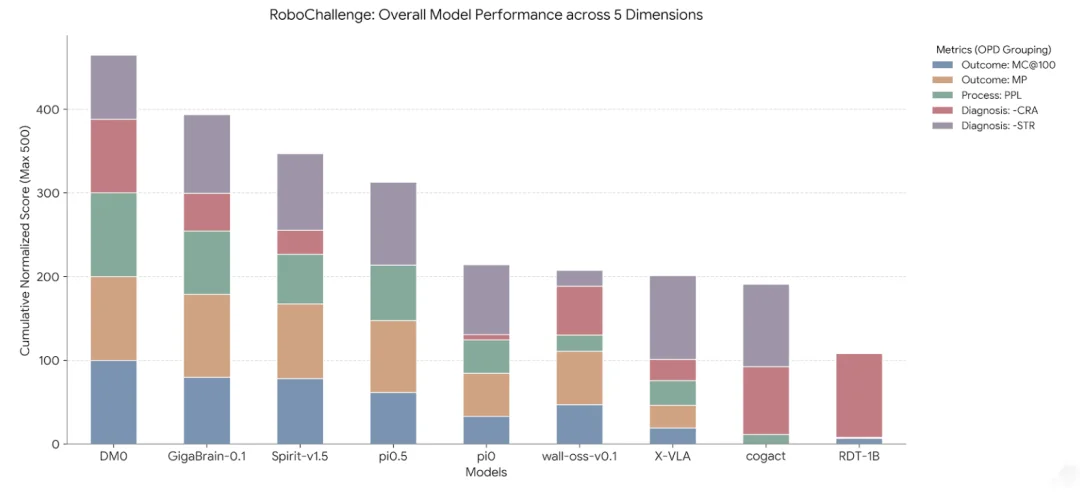
9 个模型在 RoboChallenge Table30 上的整体表现:OPD 指标提供了联合而非孤立的轨迹画像,通过 Outcome、Process 与 Diagnosis 三层信号的统一刻画,揭示模型走到了哪里、走得如何,以及问题主要出现在什么阶段。
除了论文和基准,项目博客还提供了交互式轨迹分析界面。用户可以在页面中同步查看视频播放、进度曲线以及 MC、MP、PPL、CRA、STR 等核心指标,并随着时间轴拖动观察它们如何实时更新。博客将这一模块定位为单条轨迹的完整时间审计工具:进度上升、回退和停滞,不再只是抽象曲线,而能和具体物理行为逐帧对应起来。
读者可进一步访问项目主页与博客中的交互式 Demo,查看单条轨迹的逐帧审计结果👉https://prm-as-a-judge.github.io/blog.html
PRM-as-a-Judge 的意义,不只是对 success rate 做一次补充,而是把机器人评测从终局判定推进到了过程刻画。借助任务条件化的进度势能、OPD 三层指标体系以及 RoboPulse 的细粒度验证,这项工作把原本被压缩为单一标签的执行轨迹,重新表示为可解释、可比较、可诊断的过程信号。
对于越来越长程、越来越复杂的具身操作任务来说,单一二元标签已经很难完整反映模型行为的真实差异。相比只比较 “做没做成”,过程级审计更关心 “推进到了哪里”“成功得是否高效稳定”“失败主要由什么机制导致”。从这个意义上说,PRM-as-a-Judge 提供的不只是一个新指标系统,更是一种更适合长程机器人任务的评测视角。
该团队表示:「我们也呼吁更多 benchmark 组织者与模型开发者,在提交 leaderboard 结果的同时公开执行视频与 rollout 证据,让机器人评测从 “只看分数” 进一步走向 “可回放、可核查、可诊断”。只有当轨迹本身是开放和透明的,我们才真正有机会比较不同策略在推进深度、执行质量与失败模式上的真实差异,而不仅仅停留在最终是否完成任务这一单点结论。
我们也期待与更多基准团队和研究者协作,把这种面向过程的稠密审计扩展到更广泛的机器人任务中,共同建立一个跨 benchmark、可复核、可演进的透明评测生态。评测不应只是终点处的一次裁决,而应成为理解机器人行为、诊断系统能力边界、推动社区共同进步的基础设施。」
本文第一作者冀昱衡,为中国科学院自动化研究所博士生,研究方向为具身智能与基础模型,已在 NeurIPS、CVPR、AAAI、ACM MM 等国际顶级会议上发表多篇论文,通讯作者为仉尚航助理教授和郑晓龙研究员。
文章来自于"机器之心",作者 "机器之心"。



