# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
文本驱动的人体动作生成是游戏NPC、虚拟主播、机器人控制等实时交互系统的核心技术。
但目前相关产品生成出的动作普遍有些僵硬。

近年来,非流式(non-streaming)动作生成模型已逐渐成熟,如MDM、MoMask等方法在给定完整文本后能够生成高质量的动作序列。然而,这些方法需要一次性获取完整的文本指令才能开始生成,无法满足实时交互场景中“边说边动”的需求。直接将多段非流式生成的结果进行拼接会导致动作不连贯和明显的延迟。
已有的流式生成方法主要分为两类:基于分块扩散(Chunk-based Diffusion)的方法(如PRIMAL)需要等待填满整个上下文窗口才能开始生成,存在严重的首帧延迟;基于自回归模型+扩散头的方法(如MotionStreamer)难以显式利用长期历史信息。这两类方法都存在训练-推理不一致的问题——训练时使用完整动作,推理时通过手动检测提示词变更、停止并刷新来实现流式输出。
针对这些问题,盛大AI研究院(东京)与东京大学的研究者联合提出了FloodDiffusion,首个基于定制化扩散强制(Diffusion Forcing)的流式人体动作生成框架。给定随时间变化的文本流,FloodDiffusion能够以零延迟生成丝滑过渡、与指令精准对齐的无限长动作序列。
本文已经入选CVPR 2026 Highlight。

△ FloodDiffusion流式生成效果:给定时变文本提示(如“抬腿”紧接着“深蹲”),生成平滑连续的人体动作序列
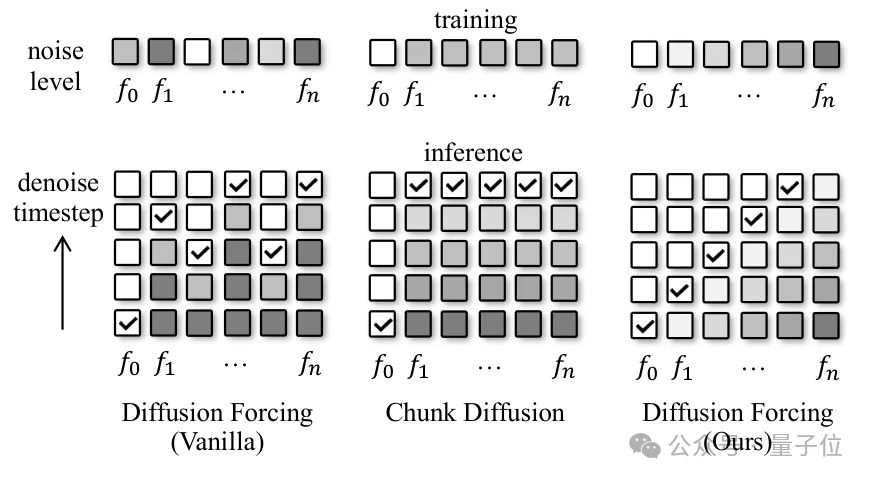
△ 噪声调度对比:扩散强制(随机调度)vs分块扩散(均匀调度)vs FloodDiffusion(下三角调度)
原始扩散强制为序列中每一帧随机采样不同的噪声时间步,导致训练与推理时的噪声分布不一致。FloodDiffusion采用确定性的下三角噪声调度:在任意时刻t,序列中仅存在一个固定大小的“活动窗口”(Active Window),窗口前方的帧已完全去噪,窗口后方的帧仍为纯噪声。
这一设计从数学上保证了:流式推理时每一帧的生成质量与完整扩散模型一致(精确似然,而非ELBO近似)。同时,模型仅需在活动窗口内进行计算,实现了恒定的计算开销和1帧的流式延迟。
与视频领域的扩散强制使用因果注意力不同,FloodDiffusion在滑动窗口内采用双向注意力机制。由于活动窗口内不同帧处于不同的去噪阶段,当前帧需要“看到”窗口内所有上下文才能基于最新的文本提示进行去噪。因果掩码会丢弃窗口内可用的上下文信息,导致严重的性能下降。
传统流式系统依赖“显式刷新”机制——检测到新的文本提示后停止当前生成、清空缓存、重新开始。FloodDiffusion摒弃了这一机制,采用逐帧的文本条件注入方式:利用预训练T5编码器提取文本特征,通过旋转位置编码与动作token对齐,在注意力层中每一帧仅关注当前时刻对应的文本提示。
这一设计使模型能够自适应地融合新指令,无需推理时的复杂优化,实现从“走路”到“跑步”的自然无缝切换。同一组文本提示在不同时刻输入可以产生不同的动作结果,体现了模型对时序信息的精确感知。
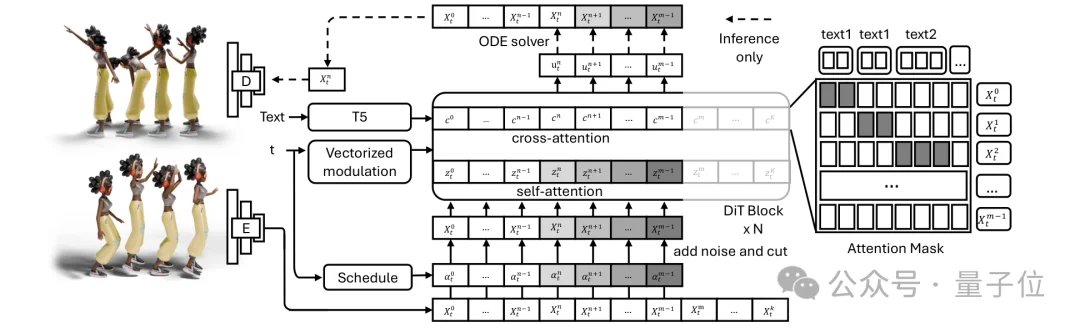
△ FloodDiffusion整体框架:263维动作流经因果VAE编码到4维隐空间,在活动窗口内进行扩散去噪,逐帧解码输出
FloodDiffusion采用隐空间扩散(Latent Diffusion)框架。263维的原始动作流首先通过因果VAE编码为紧凑的4维隐空间序列,扩散过程仅在隐空间中进行,降低了流式延迟并让去噪器专注于时序结构建模。
模型在活动窗口[m(t), n(t))内预测隐变量的速度场,条件为上下文[0, n(t))内的历史帧和对应文本。推理时,窗口逐帧滑动,生成的隐变量立即解码为动作输出,实现真正的流式生成。
不同于非流式方法使用的双向卷积VAE或VQ-VAE,FloodDiffusion采用严格因果设计的VAE:解码器在时刻t不依赖未来帧。架构基于视频生成模型Wan2.1的因果VAE,所有时空模块均适配为1D时序动作序列。使用L2重建损失和标准承诺/码本损失进行训练,时间下采样因子为4,隐空间通道维度为4。
隐空间去噪器基于DiT(Diffusion Transformer)架构,采用共享时间嵌入路径(而非逐块的时间MLP)。使用均匀时间步采样,流匹配时间偏移设置为1以适配下三角调度。文本条件逐帧施加,T5编码器(最大长度128)提取的token特征通过旋转位置编码与当前时刻的动作token对齐,在自注意力中通过偏置掩码确保每帧仅关注当前激活的文本提示。
在HumanML3D权威基准上,FloodDiffusion取得了FID 0.057的成绩,不仅超越了现有流式模型PRIMAL(FID 0.511)和MotionStreamer(FID 0.092),甚至达到了SOTA非流式模型MoMask(FID 0.045)的水平。在文本-动作对齐指标上,R-Precision@1/2/3分别达到0.523/0.717/0.810,MM-Dist达到2.887,均为所有方法中最优。
在BABEL数据集的流式评估中,FloodDiffusion在过渡平滑度指标上同样全面领先:Peak Jerk(PJ)为0.713(最接近真实数据的1.100),Area Under Jerk(AUJ)为14.05,远优于PRIMAL(PJ 1.304, AUJ 19.36)和MotionStreamer(PJ 0.912, AUJ 16.57)。
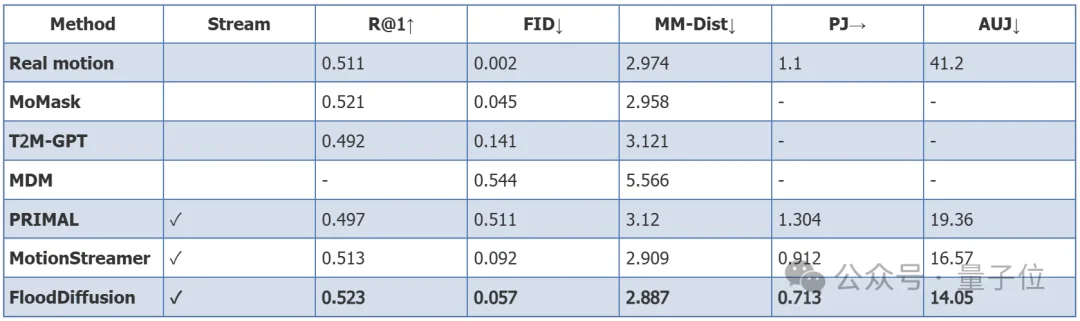
△ HumanML3D与BABEL数据集上的定量评估结果(粗体为FloodDiffusion)
在100人参与的盲测用户研究中,采用Bradley-Terry模型对三个生成模型和真实动作进行打分。FloodDiffusion在“动作质量偏好”(Preference: 0.024)、“过渡自然度”(Transition: 0.152)和“指令一致性”(Consistency: -0.021)三个维度上均显著优于PRIMAL和MotionStreamer,且在过渡自然度上甚至接近真实数据(0.299)。
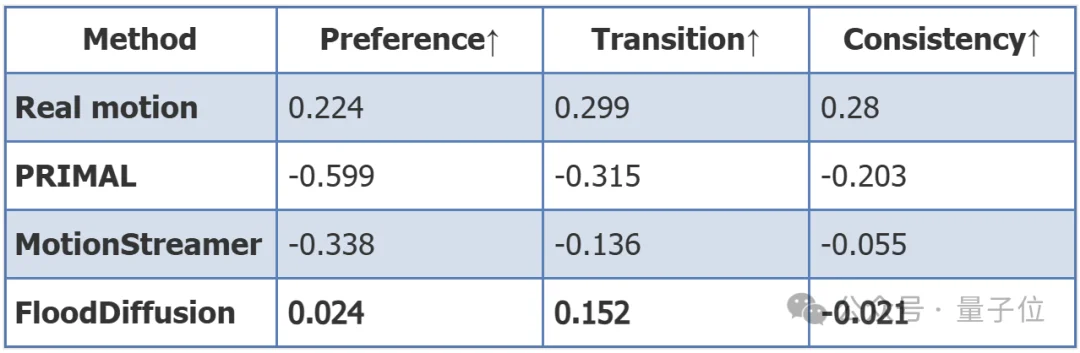
△ Bradley-Terry用户研究结果(100名参与者)
消融实验验证了两项核心设计的不可或缺性:
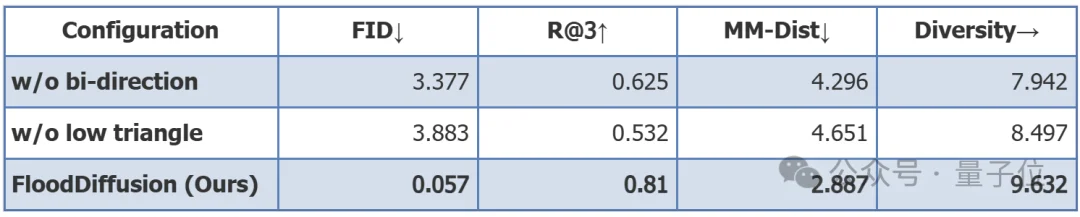
△ 核心设计消融实验:移除任一改进均导致性能断崖式下降
移除双向注意力(仅使用因果注意力):FID从0.057飙升至3.377,R@3从0.810降至0.625;移除下三角调度(使用随机调度):FID从0.057飙升至3.883,R@3从0.810降至0.532。两项改进的缺失均导致模型性能断崖式下降,证明了定制化改造对扩散强制框架在动作生成任务上的决定性作用。
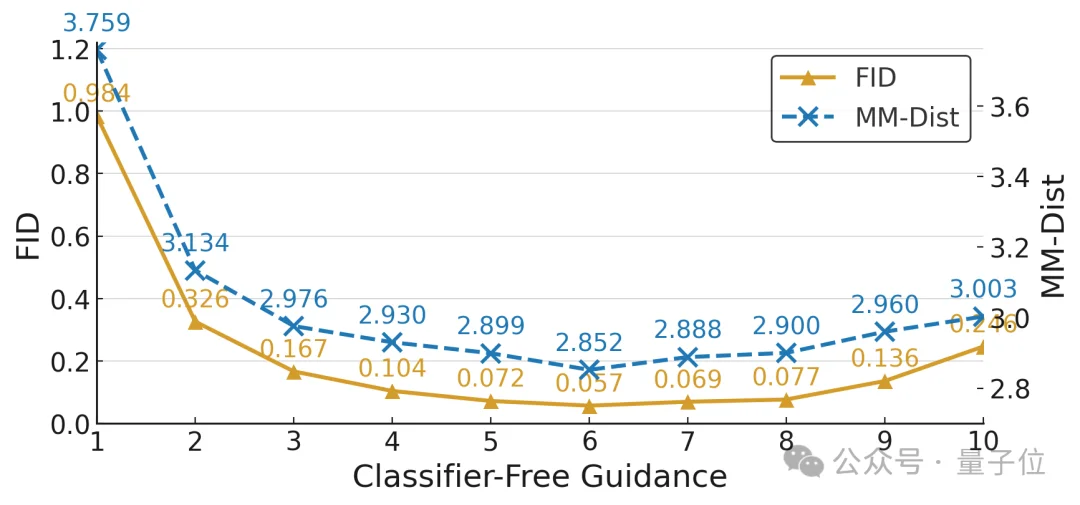
△ Classifier-Free Guidance(CFG)对FID和MM-Dist的影响,最优CFG=6
时变条件响应:

△ 时变条件对比:同一文本提示在不同时刻输入产生不同的动作结果,体现模型对时序信息的精确感知
FloodDiffusion能够根据文本提示的输入时机生成不同的动作结果。如图所示:(左上)两个提示词分别在不同帧输入,模型依次响应生成对应动作;(右上)同样的提示词作为单一输入一次性给出,模型生成不同的混合动作;(左下)两个提示词在序列前期输入;(右下)同样的提示词在序列后期输入——模型对时序信息的精确感知使其在不同场景下产生合理的差异化输出。
长序列生成:

△ 长序列生成:无新提示词时重复当前动作(左),可通过“stand”等指令停止(右)
在长序列场景中,FloodDiffusion展现了两种典型行为:(左)当没有新的提示词输入时,模型会持续重复当前文本提示对应的动作;(右)在实际应用中,可以通过显式给出静止类指令(如“stand”)来停止当前动作,实现灵活的交互控制。
FloodDiffusion是首个将扩散强制框架成功应用于流式人体动作生成的系统。通过下三角时间调度、窗口内双向注意力和连续时变文本调节三项定制化改造,FloodDiffusion从根本上解决了原始扩散强制在动作数据上的分布坍塌问题。该框架训练与推理保持一致、无需推理时的手动优化、具备恒定计算开销和极低的控制响应延迟,为实时交互游戏NPC、虚拟主播及机器人控制等场景提供了高质量的流式动作生成解决方案。
未来工作将扩展至音频、力反馈、环境信息等更多时变条件的融合。
作者:
Yiyi Cai, Yuhan Wu, Kunhang Li, You Zhou, Bo Zheng, Haiyang Liu
单位:
盛大网络AI研究院(东京),东京大学
论文地址:
https://arxiv.org/abs/2512.03520
项目主页:
https://shandaai.github.io/FloodDiffusion/
代码:
https://github.com/ShandaAI/FloodDiffusion
文章来自于"量子位",作者 "FloodDiffusion团队"。


【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
