# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
当前大模型的发展呈现出类似于“军备竞赛”的趋势——模型规模持续攀升,对计算硬件的需求也随之快速增长。
从千亿参数到万亿规模,每一次迭代都对硬件资源提出了更高的要求。

在这一背景下,一个关键的“隐性开销”日益凸显:数据搬运。在传统计算架构中,一次推理过程往往需要在DRAM、SRAM与计算单元之间反复读写数据。频繁的访存操作不仅带来高延迟,也消耗大量能耗。有研究指出,实际计算所占的时间远少于数据搬运所耗费的时间。
为此,一种极具潜力的思路应运而生:彻底消除数据搬运。这引出了两条备受关注的技术路径:存算一体与晶圆级集成。
存算一体:将存储与计算融合在同一芯片内,使数据在原地完成处理,避免频繁搬运。
晶圆级集成:直接在整片硅晶圆上构建超大规模系统,通过超高带宽互连,实现晶圆级的统一内存与计算资源。
中国科学院计算技术研究所的研究团队在该方向上取得了重要进展。其最新成果Ouroboros发表在体系结构领域的顶级会议——第31届ACM编程语言与操作系统架构支持国际会议(ASPLOS)上。
Ouroboros实现了一款完全由SRAM存算单元构建的晶圆级芯片。在该芯片中,模型推理所需的所有数据——权重、KV Cache以及激活值——全部存放于片上SRAM中,无需从外部DRAM进行搬运。所有计算均在数据存储位置完成,真正实现了“数据不搬家,计算就地化”的存算一体范式。
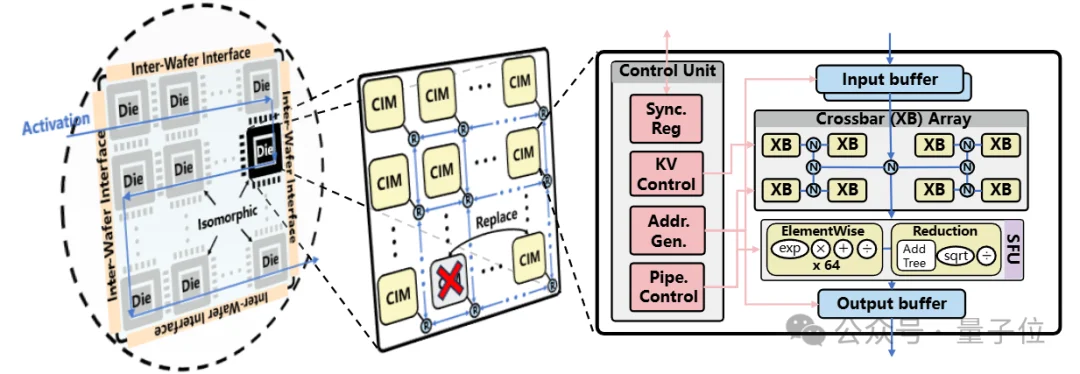
芯片采用层次化设计,自上而下分为三层:
1. 晶圆级集成
芯片顶层为一块巨型单晶圆,集成有54GB SRAM,可完整存储模型权重、激活值与KV Cache,彻底消除DRAM访问开销。整片晶圆由相同尺寸的小芯片通过stitching技术无缝拼接,形成统一调度的计算平面。
2. 芯片级组织
每个芯粒内部由上百个存算核心构成网格网络,核心间通过高带宽链路互联。设计将芯粒面积推向光刻极限以最大化SRAM容量,并引入核心级容错机制以保障大规模芯片的可靠性。
3. 存算核心微架构
每个核心包含输入输出缓存、存算阵列、专用函数单元及控制单元。缓存容量可容纳典型大模型的token数据,显著减少核心间数据传输。存算阵列通过优化的片上网络互联,专用函数单元以匹配的并行度执行softmax等操作,控制单元则协调核心间与核心内的流水线同步。
尽管Ouroboros构建了强大的晶圆级计算平面,在运行大模型时仍面临若干关键挑战:
虽然在晶圆上集成了大量SRAM,但受限于SRAM自身的密度,片上存储容量仍显不足。当模型规模继续膨胀,如何用有限的片上空间装下越来越大的权重和状态,依然是绕不开的难题。
当计算单元以成百上千的规模铺满晶圆,如何高效地把模型“拆解”并映射到这个分布式阵列上,就成了一个复杂的系统工程。存储布局、数据流调度、任务分配……每一项都需要全新的设计思路。
在存算一体的架构里,计算和存储是高度绑定的——计算发生在数据存放的位置,存储的布局也直接制约着计算的效率。因此,必须同时对两者进行协同设计与优化,才能最大化整体性能。
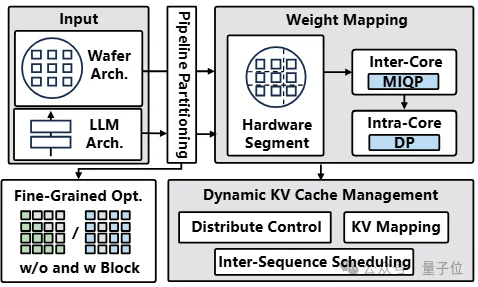
为了充分释放这片晶圆的计算潜力,团队专门打造了一个端到端大模型推理框架。
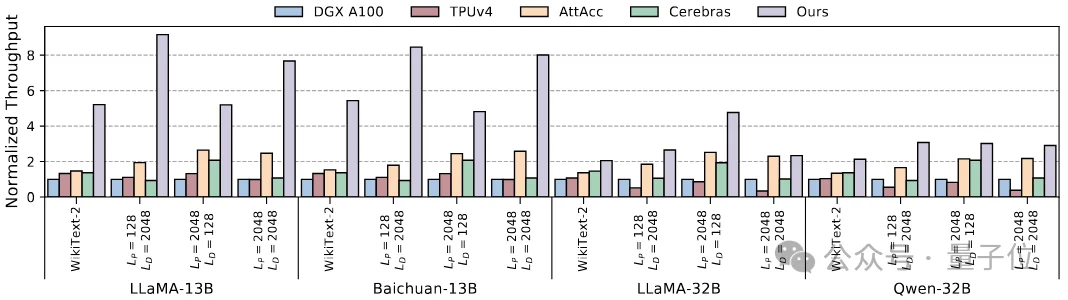
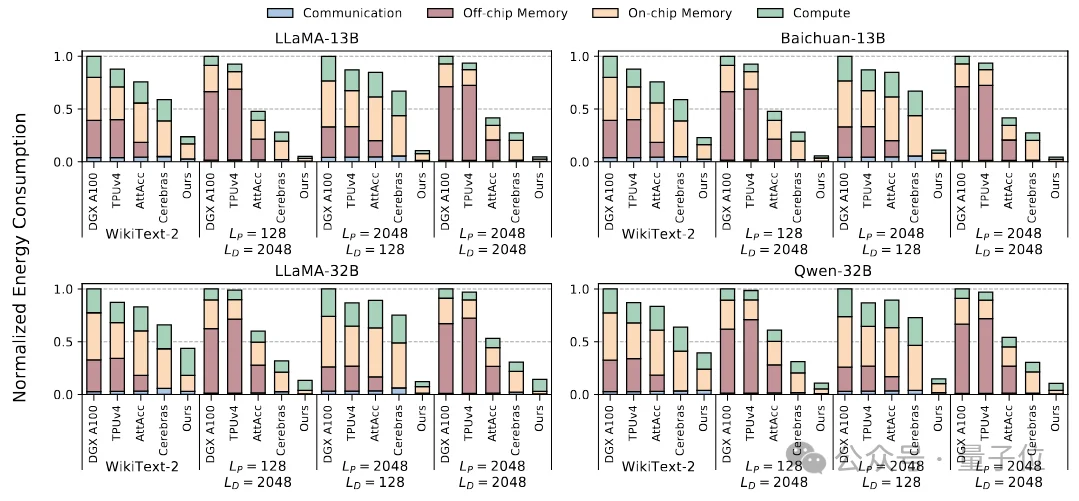
在从芯片到系统的协同设计下,Ouroboros实现了“原地计算”理念,取得了显著的性能与能效表现。实验结果表明:
平均吞吐量达到现有顶尖系统的4.1倍
平均能效提升至4.2倍
而在13B参数规模的模型上,表现尤为突出:
吞吐量最高达9.1倍
能效比甚至提升到17倍
采用单晶圆推理Llama 13B模型、在WikiText‑2数据集上进行测试时,系统吞吐量可稳定达到 15万tokens/s。这一结果进一步验证了Ouroboros在真实大模型负载下的极致性能
上述数据不仅验证了性能与能效的突破,也为“存算一体+晶圆级集成”这一技术路线的可行性提供了有力支撑。该研究标志着在消除数据搬运、构建高效大模型推理系统方向上迈出了重要一步。
论文链接:
https://dl.acm.org/doi/10.1145/3779212.3790197
作者介绍:
本文作者来自中国科学院计算技术研究所智能计算机研究中心和泛在计算系统研究中心物端计算系统实验室,团队长期致力于芯粒集成芯片研究。本文的共同第一作者是刘艺圻和潘煜东,均为计算技术研究所在读博士生。指导老师为中科院计算所王颖研究员、韩银和研究员、王梦迪特别研究助理。
文章来自于"量子位",作者 "非羊"。



