# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
过去十年,计算机视觉领域有一条铁律:看懂图片的模型,和画出图片的模型,是两拨人。
检测用检测网络,分割用分割网络,生成用扩散模型。
每一个新任务,都意味着一套新架构、一条新流水线、一群新论文。
整个领域的工程师,本质上在干同一件事——给每种视觉能力定制一把专用钥匙。
谷歌把这些钥匙全扔了。
最近,谷歌联合ResNet作者何恺明、谢赛宁、NeRF先驱Jonathan T. Barron、 3D图形学名家Thomas Funkhouser,正式发布了Vision Banana。

预印本:https://arxiv.org/abs/2604.20329
项目网址:https://vision-banana.github.io/
它向世界宣告:视觉AI终于不再需要那些臃肿的任务头了,理解,本质上只是生成过程中的一次「对齐」。

一个模型,统治所有视觉任务
传统计算机视觉的逻辑是「分而治之」。
目标检测靠回归框坐标,语义分割靠逐像素分类,图像生成靠噪声去噪。
三条技术线各有各的损失函数、各有各的训练流程、各有各的SOTA排行榜。
Vision Banana的逻辑完全反过来:不管你问什么视觉问题,答案都是一张图。
这背后有一个极其反直觉的发现——强大的生成能力,能反哺理解精度。
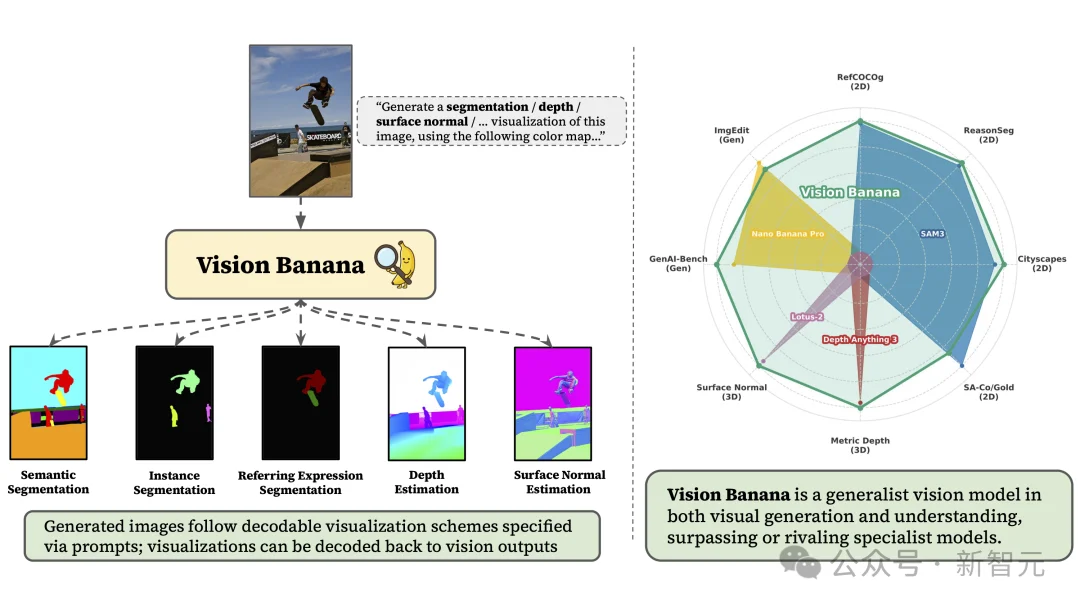
传统观点认为,理解和生成是两种截然不同的能力。
理解是压缩信息,生成是展开信息,方向相反,怎么可能互相帮忙?
极简主义的胜利:手术刀式的「指令微调」
Vision Banana的诞生路径,堪称工程美学的典范。
它不是从零开始烧掉几万张显卡的产物,而是基于基础模型Nano Banana Pro的一次「点睛之笔」。
研究团队采用了一种极度克制、甚至有些反直觉的策略:极低比例的数据混入。
他们只将一小部分具备「可逆格式」的任务数据,像添加催化剂一样,混入Nano Banana Pro自身的庞大训练集中。
这种轻量级的指令微调(Instruction Tuning),既没有洗掉模型原有的「生成本性」,又成功将模型内部涌现出的生成式表征,精准对齐到了真实的物理世界。

在与母体Nano Banana Pro的正面对决中,Vision Banana在文本生图任务(GenAI-Bench)中获得了53.5%的人类评估胜率,在图像编辑任务(ImgEdit)中获得了47.8%的胜率。


Vision Banana用数据证明:它并没有因为学会了「看世界」而遗忘如何「造世界」。
它依然是那个顶级的画师,只是现在,它的每一笔线条都具备了物理世界的逻辑。它生成的每一颗像素,既是美学,也是测量。
诸神黄昏与新王登基
Vision Banana的实验数据给出了回答:当模型在海量图像上做生成预训练时,它自发学会了深层语义对齐。
换句话说,一个能画出极其逼真图像的模型,天然就「理解」了图像里的结构、层次和语义关系。
这让人想起一个认知科学里的老命题——人类理解视觉世界的方式,本质上就是「脑补」。
看到一张被遮挡了一半的椅子,大脑会自动补全另一半。
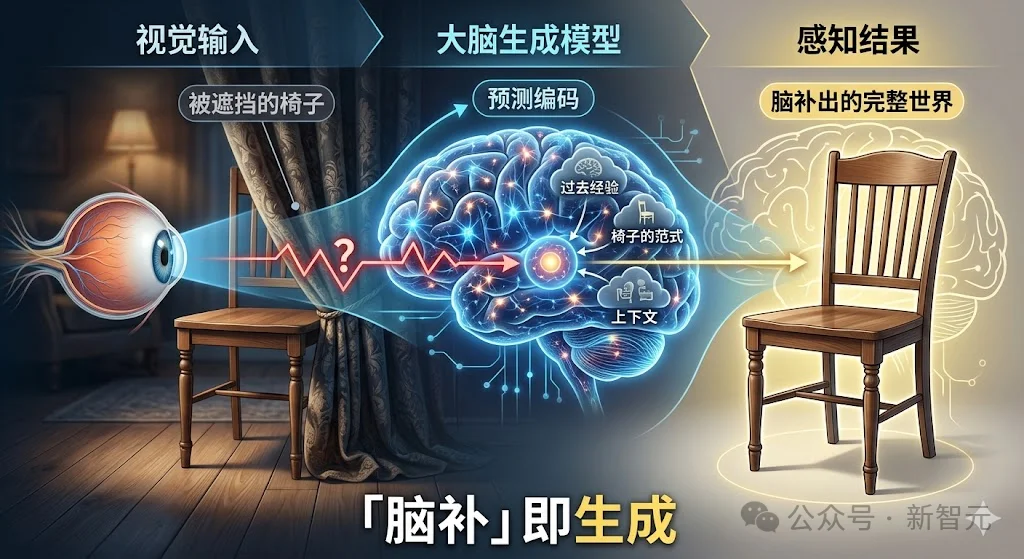
这个补全过程,就是生成。Vision Banana把这个直觉工程化了。
在多项基准测试中,它的表现直接碾过了那些为单一任务精心调教了多年的专用模型,尤其在极端遮挡、复杂场景理解等任务上,优势最明显。
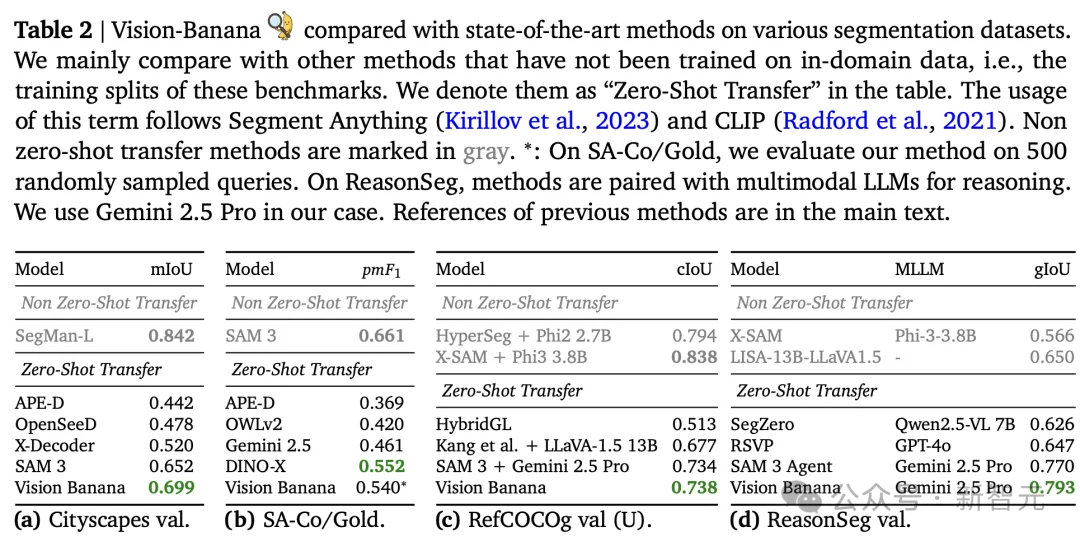
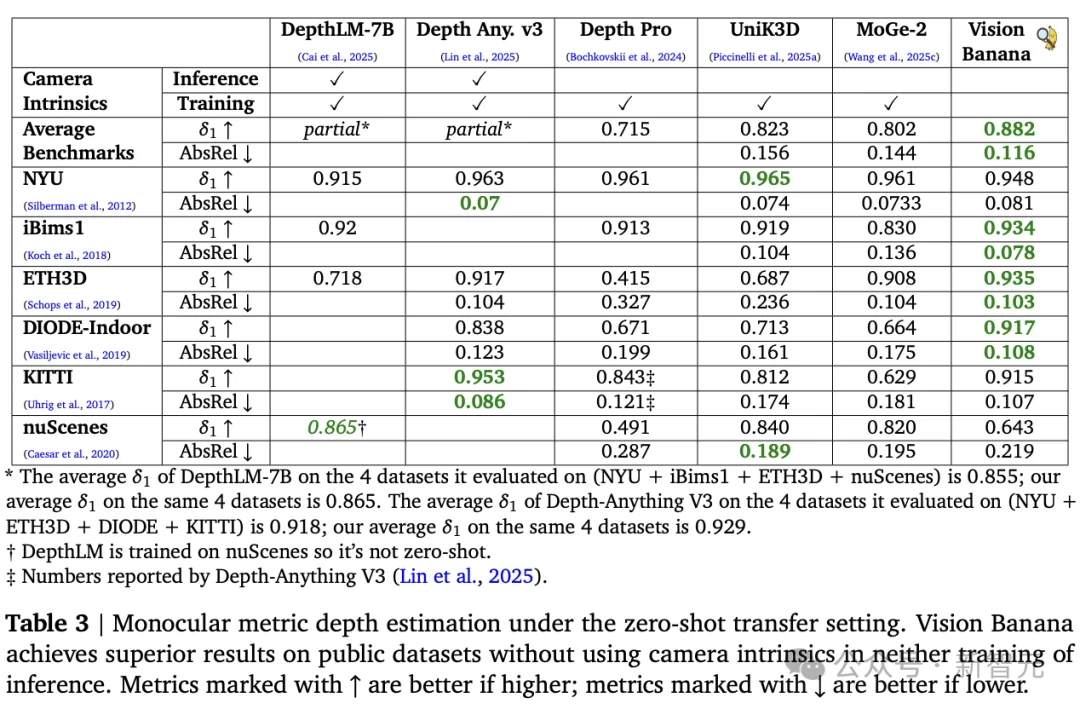
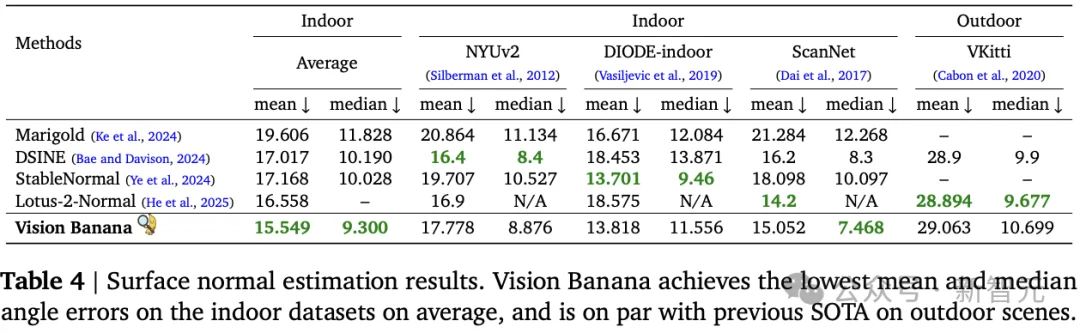
原因不难理解:专用模型只学会了「看」,Vision Banana学会了「想象」。能想象的模型,处理残缺信息的能力天然更强。
检测物体?生成一张标注了框的图。语义分割?生成一张涂了颜色的图。场景描述?还是生成图。
Vision Banana宣告了AI视觉领域的「哥白尼革命」:它彻底抛弃了过去20年的「识别」范式,转而用「想象」来征服现实。
从此,理解不再是目的,它只是生成过程中的一个「副产品」。
熟悉深度学习历史的人会立刻反应过来,
这一幕似曾相识。
2017年,Transformer论文的标题叫「Attention Is All You Need」,把NLP里七八种专用架构一锅端了。
Vision Banana干的事情本质上一样:Generation Is All You Need。
旧范式的裂缝,早就在了
很多人第一反应是:又一个「大一统」的故事,AI领域这类叙事听太多了,真正落地的有几个?
这种怀疑完全合理。过去几年,「统一模型」的概念被滥用到了通货膨胀的程度。
但这次的区别在于,Vision Banana不是在讲概念,它是在跑分上直接证明了:统一不意味着妥协。
传统上,统一模型的代价是每个子任务都比不过专用模型。所谓「万能工具不如专用工具」。
Vision Banana打破了这个诅咒——它在生成和理解两个方向上同时达到了SOTA。
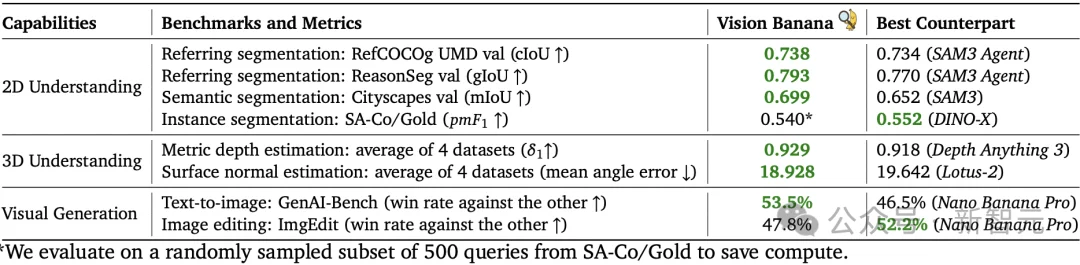
在视觉生成与理解任务上,指令微调后的Vision Banana模型实现SOTA
这意味着一件事:不是统一模型做不好,是之前的统一方式选错了接口。
过去的尝试大多是在模型内部硬塞多个任务头,本质上还是「多个专用模块共享一个骨干网络」。Vision Banana的做法更彻底——它连任务头都不要了,所有输出都是像素。
这个设计选择的优雅之处在于:像素是视觉领域最底层的通用语言。不管你要检测、分割、生成还是编辑,最终呈现在屏幕上的都是像素。Vision Banana把输出统一到了最底层,反而获得了最大的灵活性。
视觉AI的Transformer时刻
把时间线拉长一点就会发现,Vision Banana的出现不是孤立事件。
2017年,NLP领域经历了从「专用模型时代」到「通用模型时代」的范式切换。
Transformer一统江湖之后,整个领域的研究方式、工程实践、商业逻辑全部重写。
计算机视觉到现在还没完成这个切换。
ViT出来之后,Transformer进了视觉领域,但任务层面的统一一直没有实现。检测、分割、生成,依然是三条独立的技术线。
Vision Banana可能是补上这最后一块拼图的那个模型。
当所有视觉任务都变成「生成像素」,一个直接的后果是:未来的视觉AI不再是「看图识字」的工具,而是具备「视觉想象力」的系统。
它通过在生成空间内推理,来应对现实世界中无穷无尽的变体。
它背后的野心则是构建一个统一的视觉世界模型(World Model)。
Vision Banana证明了一个深邃的哲学命题:视觉推理本质上就是一种受约束的生成。
这种能力直接指明了具身智能(Robotics)的未来:如果一个机器人拥有Vision Banana的灵魂,它不再需要复杂的路径规划算法。
它只需要在脑中「生成」一段它成功取到杯子的像素序列,然后按照这段序列去对齐物理现实。
最好的视觉模型,不应该是一个完美的分类器,而应该是一个拥有完美想象力的观察者。
这事儿放进更大的坐标系里看,谷歌在下一盘很大的棋。
Gemini统一了文本和多模态理解,Vision Banana统一了视觉理解和生成。两者如果接通,一个真正意义上的「世界模型」的雏形就出现了——既能理解世界,又能想象世界。
十年前,计算机视觉的工程师们为每个新任务焊一条新流水线。十年后,一个模型用同一个动作回答所有视觉问题。
从专用到通用,从理解到想象,这条路NLP用了七年走完。视觉AI走到了同一个路口。
这一次,钥匙只有一把。
参考资料:
https://vision-banana.github.io/%20
https://x.com/arankomatsuzaki/status/2047139493543846251?s=20
文章来自于微信公众号 "新智元",作者 "新智元"



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
