# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
「快!」
说到索尼克,不管是刺猬索尼克还是音速索尼克,大家的第一印象多半就是「快」,而「快」也是现在许多 AI 模型和应用优化的一大核心目标。
近日,由普林斯顿大学 Tri Dao(FlashAttention 的一作)和加州大学伯克利分校 Ion Stoica 领导的一个联合研究团队也做出了一个超快的索尼克:SonicMoE。

一作 Wentao Guo 的推文,他目前正在普林斯顿大学就读计算机科学博士
据介绍,SonicMoE 能在英伟达 Blackwell GPU 上以峰值吞吐量运行!并且运算性能超过了 DeepSeek 之前开源并引发巨大轰动的 DeepGEMM。
有趣的是,DeepSeek 前些天还在 DeepGEMM 库中开源了新的技术 Mega MoE,即巨型 MoE—— 从名字也能看出来,这与 SonicMoE(音速 MoE)显然是两个不同的方向,我们也期待能看到「大」与「快」这两个方向的更直接的对比。
下面我们就基于官方技术博客,简单了解下 SonicMoE。

MoE 与它的隐患
要理解 SonicMoE 解决的是什么问题,先得认识一种正在主导前沿 AI 的架构设计 —— 混合专家模型(Mixture of Experts,MoE)。
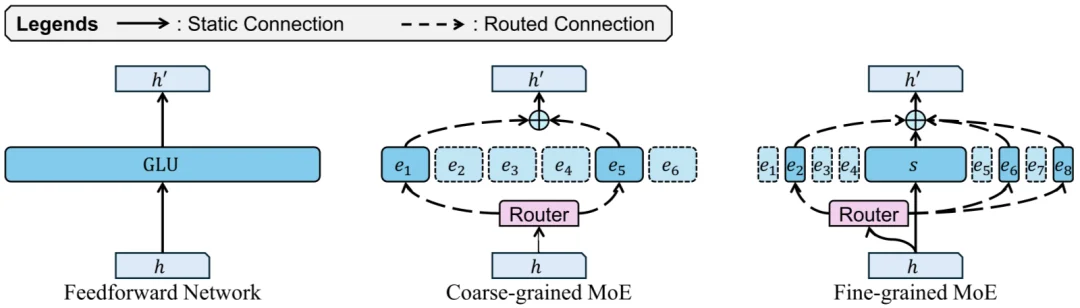
细粒度 MoE 架构
想象一家医院。面对每一位患者,医院不会让所有科室同时出动,而是先由全科医生判断,再分诊给最合适的专科。MoE 架构的逻辑与此相似:模型内部有大量「专家」子网络,每一个输入的信息片段(即 token,可以理解为文字或词语)只会被路由到其中一小部分专家处理,而不是流经所有参数。
这样做的好处显而易见:用相对较少的计算量,撑起了一个参数规模庞大的模型。
2024 年发布的 Mixtral 8x22B,以及近期的 DeepSeek V3.2、Kimi K2.5、Qwen3 等明星模型,都是 MoE 架构的忠实拥趸。按照模型缩放法则,专家越「细粒度」(即每个专家越小、数量越多),模型在同等计算量下的表现往往越好。于是在短短两年间,MoE 专家的粒度提升了整整 9 倍,每次激活的专家比例则降至原来的十二分之一。
然而,代价也随之而来。
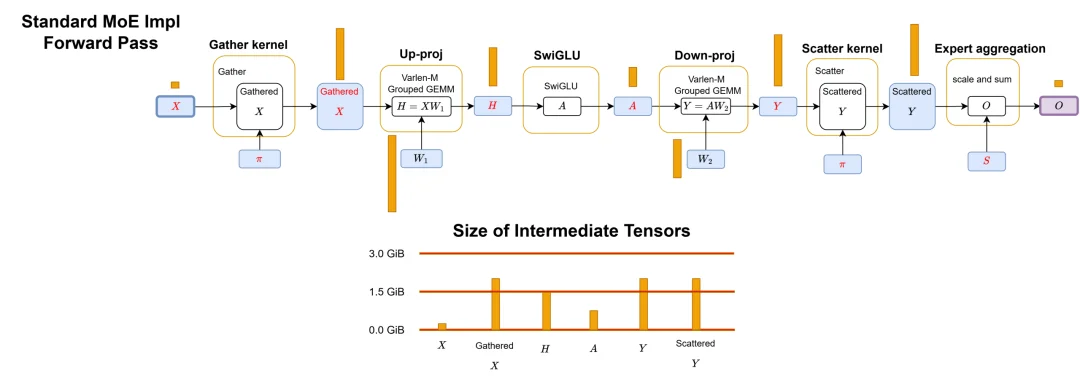
标准 MoE 实现前向传播的工作流程。π 是存储路由元数据的二进制掩码。黄色框表示内核边界。蓝色框是 HBM 中的变量。红色标签表示在正向 / 反向传播过程中缓存的激活值。紫色框是最终输出。全局内存中每个变量旁边的橙色框表示对应 Qwen3-235B-A22B-Thinking-2507 MoE 模型在处理 32k 个 token 时的张量大小比例。
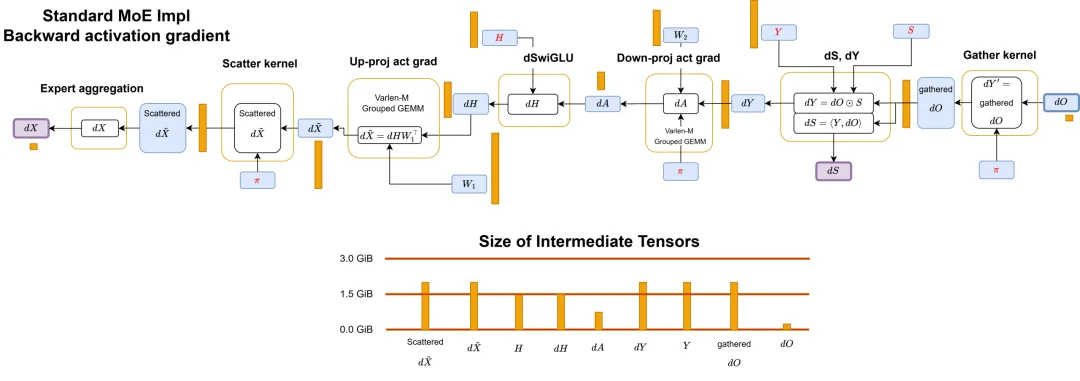
标准 MoE 实现的反向激活梯度传递工作流程。
当专家越来越多、越来越「细」,训练这样的模型会遭遇两堵越来越高的墙:
第一堵墙是显存。在训练神经网络时,前向传播的中间结果必须被保存下来,以便反向传播时计算梯度。对于细粒度 MoE 来说,这些中间结果(激活值)的规模与专家粒度成正比 —— 专家越细,显存占用越大,最终会逼近 GPU 显存的物理极限。
第二堵墙是内存带宽。GPU 的性能取决于两个维度:算力(每秒能做多少次运算)和带宽(每秒能搬多少数据)。当专家足够细时,每个专家处理的数据量太少,GPU 的算力根本来不及被填满,大量时间都花在了从内存「搬运」数据上。这正是所谓「内存瓶颈」。对于典型的 Qwen3 细粒度 MoE,其单位计算量的内存访问强度比等参数量的普通模型高出 12 倍。
现有的开源训练工具(如 ScatterMoE 和 MoMoE)对这两个问题都存在明显不足,尤其是随着模型越来越细粒度,差距愈发显著。而 SonicMoE 正是为此而生。
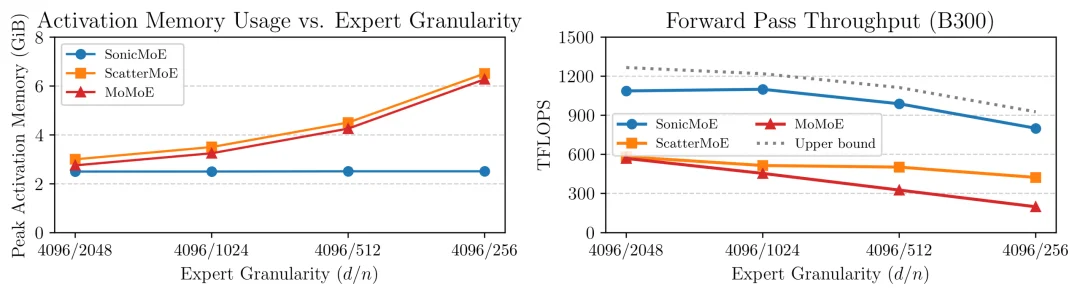
SonicMoE 的每一层激活记忆占用空间(左图)即使在专家粒度(嵌入维度 / 专家中间维度)增加时也保持不变,并且与现有的 MoE 训练核 ScatterMoE 和 MoMoE 相比,SonicMoE 可以实现 1.87-4.04 倍的相对加速。
核心创新:一次算法级的重新设计
SonicMoE 的关键洞察,乍听简单,却需要深厚的系统级思维才能想到:问题的根源在于,现有 MoE 训练框架在中间结果的存储上过于「慷慨」—— 它们把太多临时数据写入了显存,而这些数据本可以不存。
传统方法在执行 MoE 的前向传播和反向传播时,会在每个计算阶段之间将中间张量(即矩阵形式的中间数据)写入 GPU 的高带宽内存(HBM)。这就好比一个厨师每炒完一道中间步骤,就把食材装盘放进冰箱,下一步再取出来继续 —— 频繁的存取本身就是大量时间的浪费。
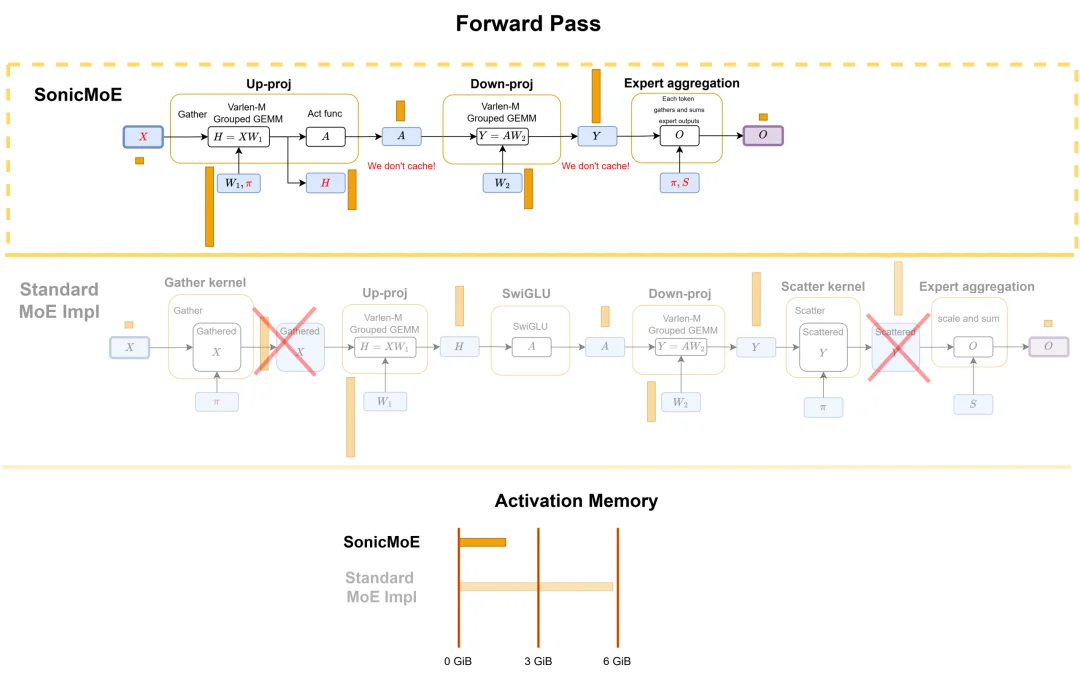
SonicMoE 的前向计算工作流程以及与 PyTorch 中标准 MoE 实现的比较。这里还比较了两种方法的激活内存和 IO 成本。
SonicMoE 的算法重设计从根本上改变了这一流程,核心有两点:
第一,激活内存与专家粒度解耦
在训练反向传播中,SonicMoE 通过重新设计计算顺序,完全避免了缓存任何与专家规模成比例的中间张量。
具体来说,它将原本需要缓存的「下投影输出」等关键中间量,通过重排矩阵乘法的收缩顺序来消除 —— 不再存储中间结果,而是在需要时通过聪明的计算路径直接推导出所需梯度。
这使得 SonicMoE 的每层激活内存占用,在专家粒度大幅增加时保持恒定,相当于一个相同激活参数量的稠密模型。
这一改进无需任何额外的矩阵重计算代价,正面回答了此前业界一直认为「鱼和熊掌不可兼得」的问题。
第二,IO 感知的算子融合
SonicMoE 将原本分散成多个 GPU 核函数(kernel)的操作大量融合在一起。
例如,「Gather 融合」技术让数据搬运操作在矩阵乘法计算核的执行过程中同步完成,而不是作为单独步骤先把数据重排好再交给矩阵乘法 —— 这不仅省去了一次完整的内存读写,还利用了 GPU L2 缓存的局部性优势,让缓存命中率从约 66% 提升至约 75%,进一步降低了访问慢速 HBM 的频率。
此外,SwiGLU 激活函数的计算也被融入矩阵乘法的尾声(epilogue)阶段,在数据还驻留在寄存器时就地完成,无需额外的内存读写。
在最关键的反向传播核函数(dH kernel)中,SonicMoE 还进一步利用 GPU 的异步执行特性,将数据搬运的等待时间与矩阵运算重叠起来。
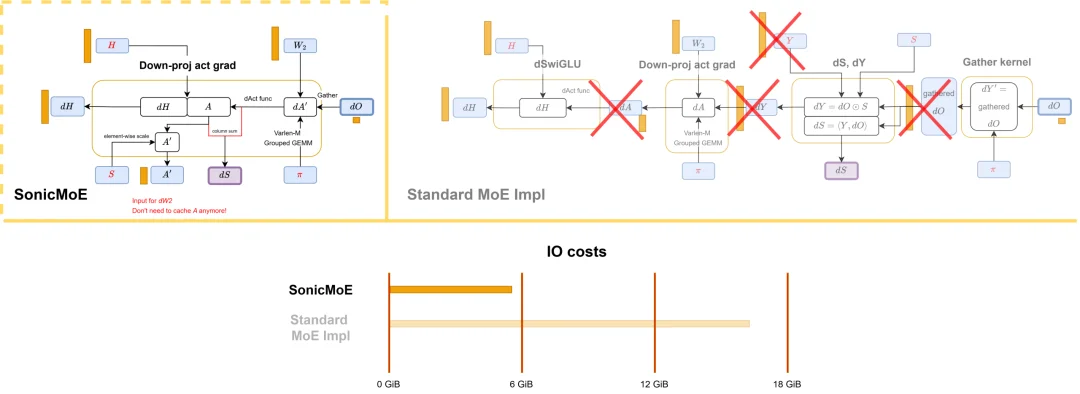
SonicMoE 的 dH 工作流程图的语义与标准 PyTorch MoE 多核实现等效,同时 SonicMoE 显著降低了 IO 成本。
实测结果显示,即便该核函数的 HBM 数据流量增加了 24%,张量核心(Tensor Core)的利用率仅下降约 10%—— 内存开销几乎被算力完全「吸收」。
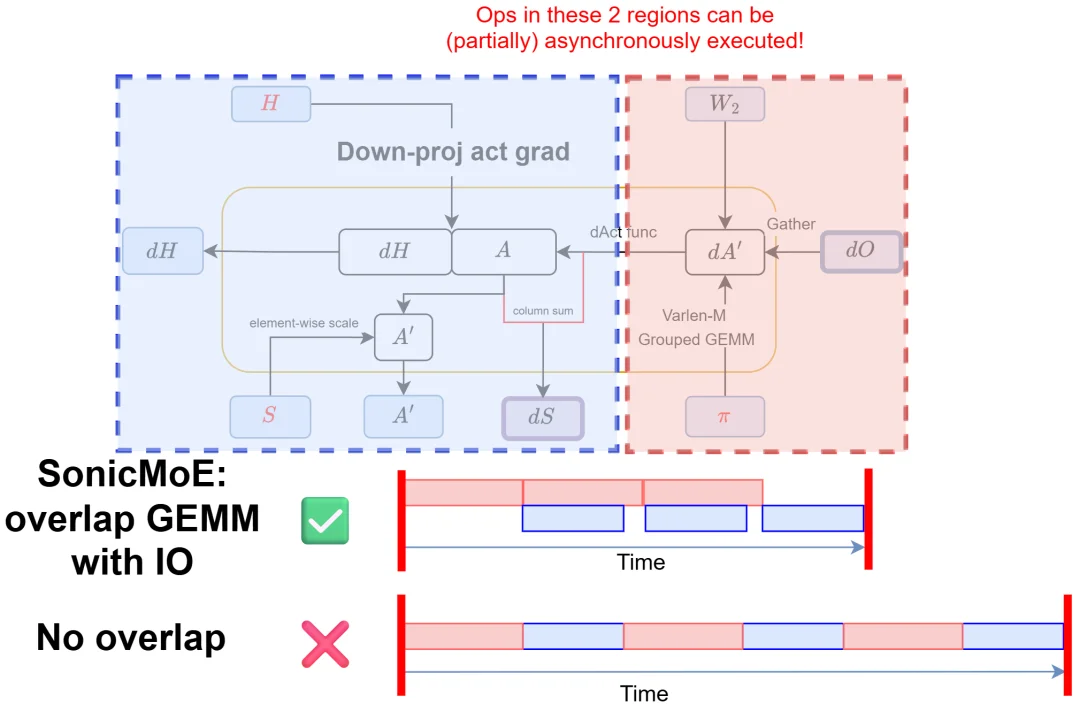
可以利用最新的 NVIDIA 硬件特性来隐藏 SonicMoE 的 dH 内核中的 IO 延迟,并大幅减少整体运行时间。
软件抽象层 QuACK:让创新能跨代迁移
SonicMoE 还有一个容易被忽视的工程亮点:研究团队开发了一套名为 QuACK 的统一软件抽象层,将所有 MoE 矩阵乘法核函数统一为「主循环 + 可定制尾声」的共同结构。

两个使用 QuACK 实现的 SonicMoE 内核。左侧:内核工作流程图。中间:QuACK 尾声混合类,其中每个内核重写 epi_visit_subtile(dH 为 88 行代码,上投影前向为 21 行代码)。右侧:SonicMoE 的简化内核启动调用。
这样的设计意味着,当 GPU 从上一代 Hopper 架构(H100)升级到最新的 Blackwell 架构(B200/B300)时,硬件特有的优化只需要在极少数地方做局部修改,核心算法逻辑无需重写。
Tri Dao 与 Ion Stoica 团队之所以能快速将 SonicMoE 移植到英伟达最新旗舰 Blackwell GPU 并达到峰值吞吐,很大程度上正是受益于这一前瞻性的软件架构。
实验结果
研究团队在英伟达最新 B300 GPU 上,以六个真实开源 MoE 模型配置为基准进行了全面测评,涵盖从 7B 到 685B 参数的不同规模,包括 OLMoE、Qwen3-235B、DeepSeek V3.2 等当下最受关注的 MoE 架构。
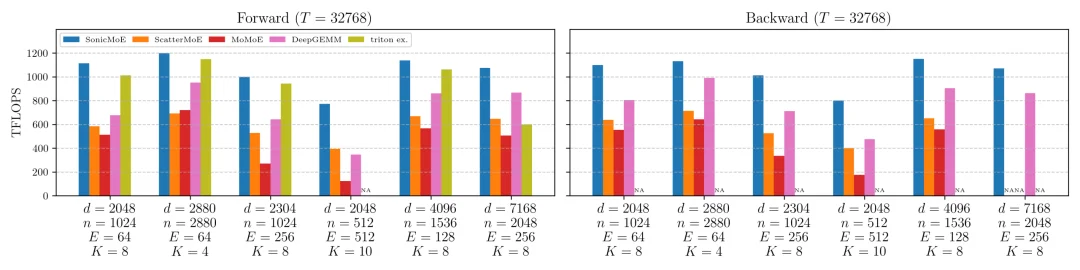
B300 上 6 种真实 MoE 配置的前向(左)和后向(右)TFLOPS。从左到右依次为:OLMoE-1B-7B-0125、gpt-oss-20b、Kimi-Linear-48B-A3B-Base、Qwen3-Next-80B-A3B-Thinking、Qwen3-235B-A22B-Thinking-2507 和 DeepSeek-V3.2-Exp。Triton 官方示例不支持后向传播,Qwen3-Next-80B 的前向传播也不支持 K=10。
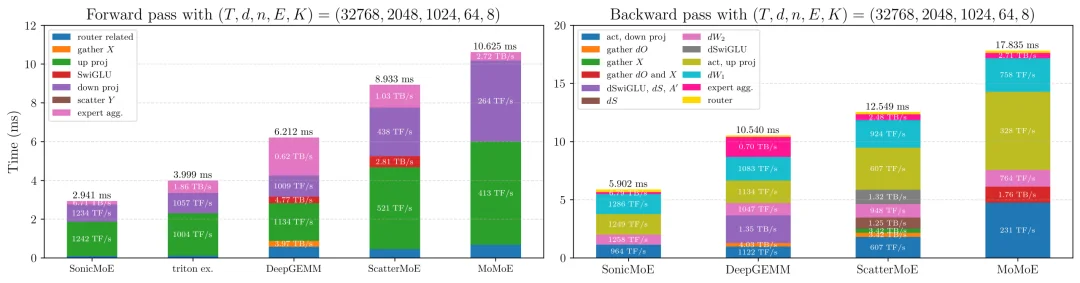
SonicMoE 与基线模型在 B300 上针对 7B OLMoE 规模 MoE(T=32768,d=2048,n=1024,E=64,K=8)的运行时分解情况。
结果相当显著:
从核函数级别的运行时分析来看,SonicMoE 的加速主要来自两个方面:其一,Gather 融合消除了独立的数据搬运核函数,这是最主要的加速来源;其二,更快的分组矩阵乘法实现(得益于 Blackwell 独有的 CLC 调度器和 2CTA MMA 技术)贡献了额外约 10% 的提升。
在激活内存方面,当专家粒度从 Mixtral 时代提高到 Kimi K2.5 量级时,传统方案的每层激活内存会线性膨胀,而 SonicMoE 的占用则保持稳定。这对于在有限显存中训练更细粒度的未来模型,意味着更大的操作空间。
结语
SonicMoE 很快,同时还有更深层的意义:当硬件的进步受制于物理规律逐渐放缓,软件层面的创新正越来越多地扮演起「平权者」的角色。
SonicMoE 的论文标题是「硬件高效、软件可扩展的细粒度 MoE 蓝图」—— 这个「蓝图」二字,或许正是研究团队想传递的信号:这不只是一个工具,而是一种可以被复制和继承的设计哲学。
SonicMoE 目前已在 GitHub 和 PyPI 开源,支持 H100 和最新 B200/B300 GPU,未来计划扩展至专家并行、MXFP8/FP4 精度支持,以及下一代英伟达 Rubin GPU。
在内存和算力日益稀缺的今天,这种创新极具价值,毕竟这是在为整个 AI 生态节省真金白银的成本。
你更看好 DeepSeek 的 Mega MoE 还是今天介绍的 SonicMoE?
文章来自于微信公众号 "机器之心",作者 "机器之心"



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
