# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在代码大模型和代码智能体技术快速发展的今天,一个日益凸显的现象是:能够在经典代码生成基准上取得优异成绩的模型,一旦被放入真实软件工程环境中,表现却往往大幅下滑。
这种落差的根源在于,真实软件工程并不是一道孤立的编程题,而是一个长时程、强上下文持续交互、反复验证与修正的复杂过程。
模型不仅要会写代码,还要能够正确理解需求、在仓库中定位文件、在合适时机调用工具、解释测试反馈、修正先前错误,并在必要时及时停止。
这意味着,在评测基准上表现出色的代码模型,其评价体系与训练模式通常更侧重于单一任务的代码生成,并不天然适用于现实世界中复杂的软件工程任务。
围绕这一问题,北京大学金芝教授和李戈教授团队提出了一套软件工程智能体对齐框架 SEAlign,通过对智能体轨迹中的关键决策点进行识别与对齐,显著提升模型在真实工程任务中的表现。实验证明,经过 SEAlign 优化后的 14B 参数开源模型,在 SWE-bench 等真实场景中表现出明显领先同体量模型、甚至媲美顶级闭源模型的能力。相关成果发表于软件工程顶会 ICSE 2026,并荣获 ACM SIGSOFT Distinguished Paper Award (杰出论文奖)。

ICSE,即 IEEE/ACM 国际软件工程会议,是软件工程领域的顶级会议,也是中国计算机学会推荐的 A 类国际学术会议。本年度 ICSE 共收到全球 1469 篇论文投稿,最终录用 321 篇,其中仅 22 篇被评为顶尖论文,获奖比例不足总投稿的 1.5%,用以表彰其在软件工程领域技术创新性和影响力方面的杰出贡献。

现有代码模型的后训练大多围绕编程竞赛、算法题代码生成展开,这类任务通常目标清晰、上下文短、依赖少,主要考察生成代码答案的能力;而真实软件工程任务则要求模型在复杂仓库、工具链和反馈循环中持续做决策。
论文实验数据显示,即便是经过充分后训练、在各种 Benchmark 任务上表现不俗的 Qwen2.5-Coder-Instruct-14B ,配合 OpenHands 框架后,在模拟真实 GitHub 漏洞修复的 SWE-Bench-Verified 上,仅有 2.8% 的问题解决率。这说明现有对齐方式主要教会了模型「如何写代码」,却尚未充分教会模型「如何驱动一个软件工程智能体持续行动」。
论文进一步分析了失败轨迹,发现问题主要集中在三类行为失配上。
1、一是指令跟随不足:模型没有真正读懂 issue 中的约束,或者过早按照自己的理解动手修改,最后写出的代码「看起来合理」,却没有解决真实问题。
2、二是工具调用错误:包括错误地选择工具、传入不合法参数、查看无关文件,或者没有在关键时刻使用正确工具,导致上下文和计算预算被大量浪费。
3、三是重复循环:模型不断重复相似动作,却没有根据环境反馈更新判断,最终陷入无效迭代。也就是说,真实软件工程中的核心瓶颈并不是单步代码生成,而是整个多步决策过程中的行为质量。
针对上述问题,SEAlign 的核心思想非常直接:如果软件工程智能体的成败,取决于一系列中间决策,那么训练目标就不应只关注最终代码是否正确,而应显式优化模型在关键步骤上的行为选择。
论文提出,智能体轨迹中不同动作的重要性并不相同。有些动作即便略有偏差,模型也会在后续路径中纠正错误;但另一些动作一旦出错,就可能让整个轨迹彻底偏航。
因此,软件工程对齐的关键并不在于均匀优化每一个 token 或所有步骤,而在于识别真正决定成败的关键节点,并在这些节点处引导模型偏好更优决策。
最近也有一些研究人员开始将 Agent 与控制论的思路进行类比。从瓦特调速器到现代控制系统,一个更值得关注的共同点在于,它们并不是要预先规定每一步具体动作,而是通过识别那些可能引发系统性偏离的关键状态,并在这些位置上施加适当的校正信号,以维持整体运行方向的稳定。对应到软件工程智能体,模型的能力也不应只是生成某一段代码,而更体现在其能否在关键节点上持续作出较为合理的判断。
SEAlign 的启发性正在于此:它并不对整条轨迹上的所有行为施加均匀约束,而是将对齐的重点放在那些更可能影响轨迹走向的关键决策点上,从而在一定意义上把软件工程智能体的训练问题转化为一个面向闭环反馈的过程控制问题。
具体来说,SEAlign 包含三个核心阶段:
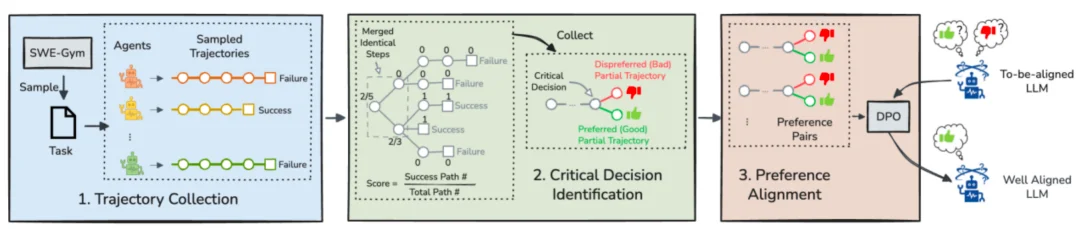
第一步是轨迹数据收集:论文将模型置于真实的软件工程环境中,让其在 Agent 框架下完成任务,并记录完整的 Agent 决策轨迹,同时根据任务是否被最终解决来给出成功或失败的标记。为了避免数据泄漏,论文明确排除了测试数据集所涉及的任何仓库以及与之相近的仓库。
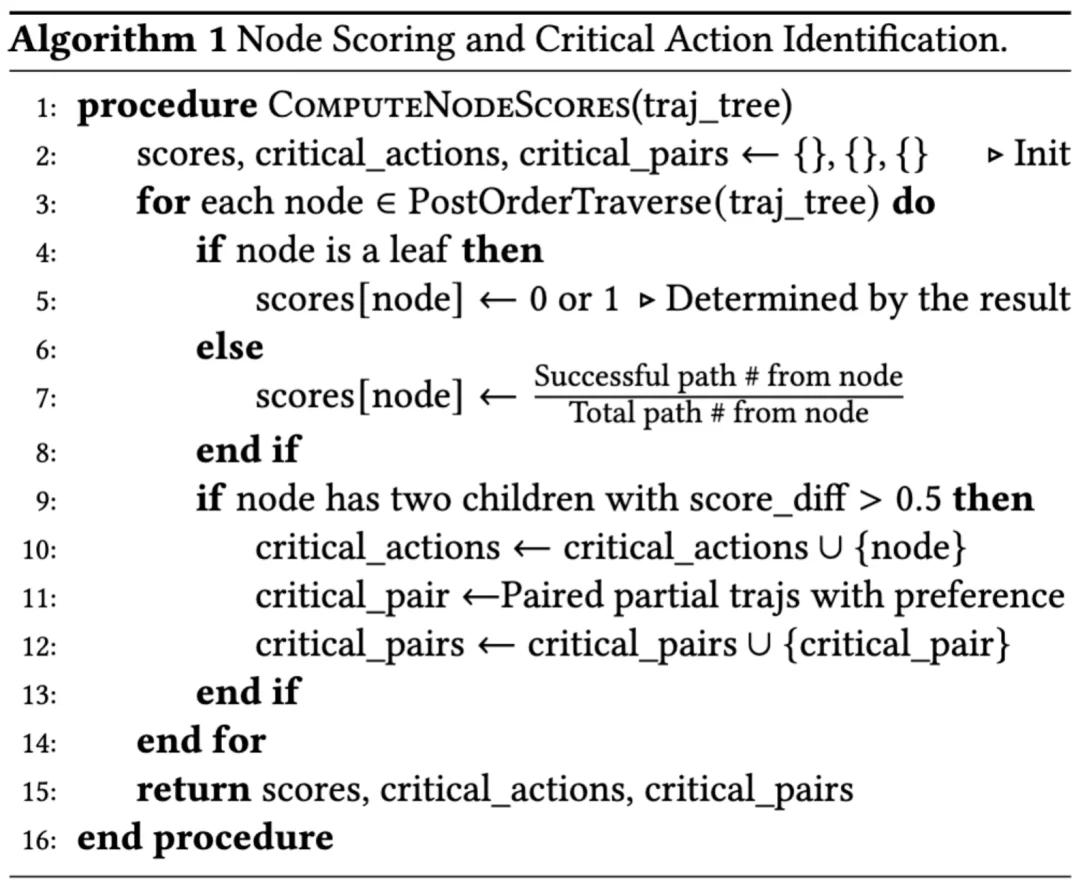
第二步是轨迹树构建与关键动作识别:论文观察到,不同轨迹之间常常共享相同前缀,因此将这些重合的决策路径进行合并,可以将一群独立的智能体轨迹链合并成一个轨迹树结构,每个非叶节点对应一个决策步骤,每个叶节点对应成功或失败结果。基于这棵轨迹树,SEAlign 进一步过滤掉低质量样本,例如反复重复同一动作、没有实质推进的 loop 轨迹,以及与其他样本没有有效重叠的离群轨迹。
第三步是偏好对齐训练:论文利用类蒙特卡洛采样的节点评分方法,从同一前缀下找出「一个动作导致后续成功概率显著更高,另一个动作导致显著更差」的关键动作对,再通过偏好学习让模型在这些关键点上学习偏好更优行为。
从方法设计上看,SEAlign 把软件工程能力明确建模为一种智能体轨迹上的关键点决策能力。这与过去很多代码对齐方法只围绕程序正确性、偏好输出或竞赛题结果来构造训练信号不同:SEAlign 关心的是模型是否会在关键节点避免走偏。这也是它与一般代码生成优化工作的本质差异所在。在当前追逐 Long Running Agent Harness 的时代,SEAlign 采用了近似控制论的设计思路,在关键决策点上为模型提供约束的同时,也允许模型进行广阔的探索。
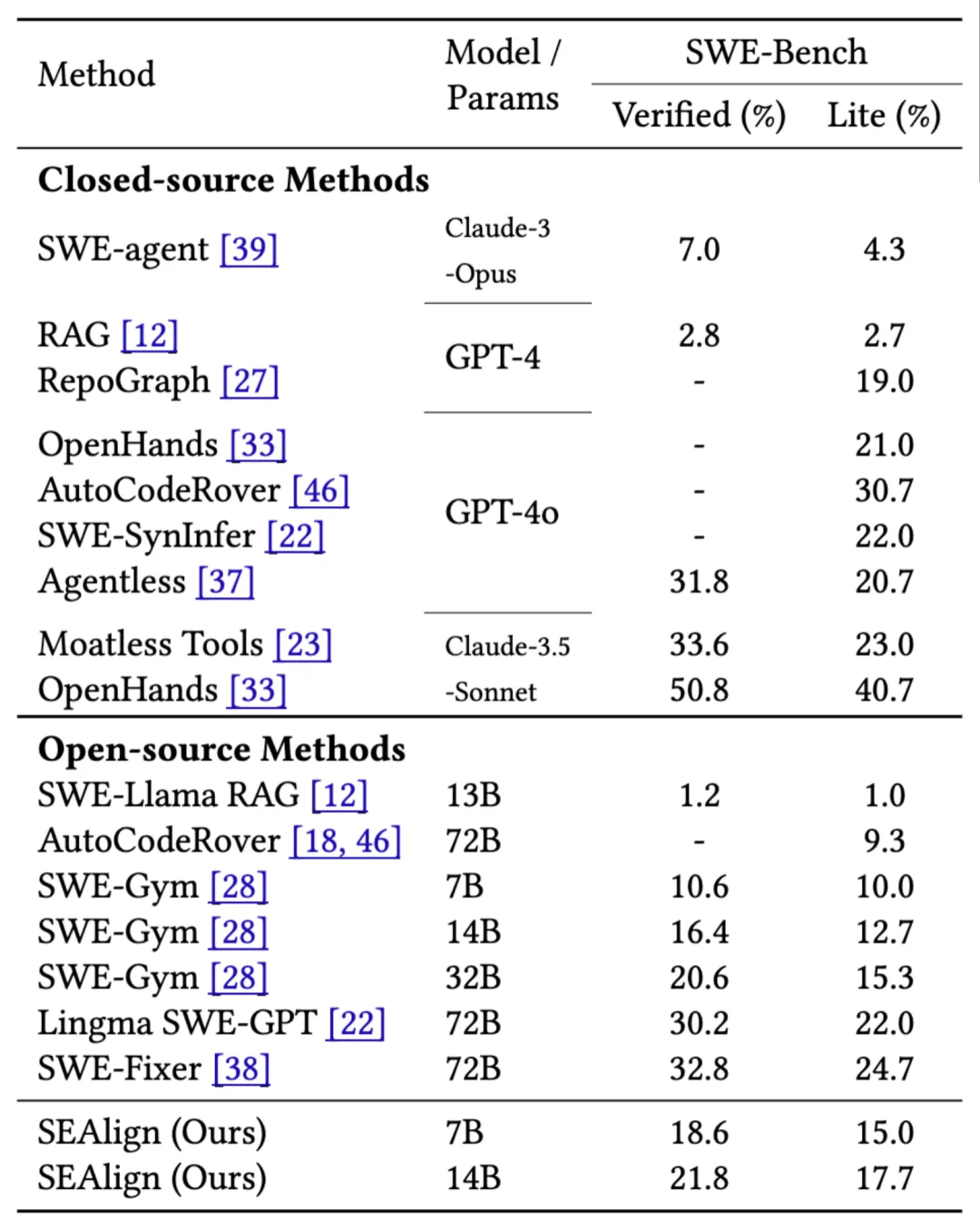
在高度贴近真实软件工程场景的 SWE-Bench 系列实验中,SEAlign 展现出了明显的提升。论文仅使用不到一千条样本,以相对较低的训练开销,便在同等参数规模的开源模型中取得领先表现,部分指标甚至逼近商业闭源模型 GPT4o。
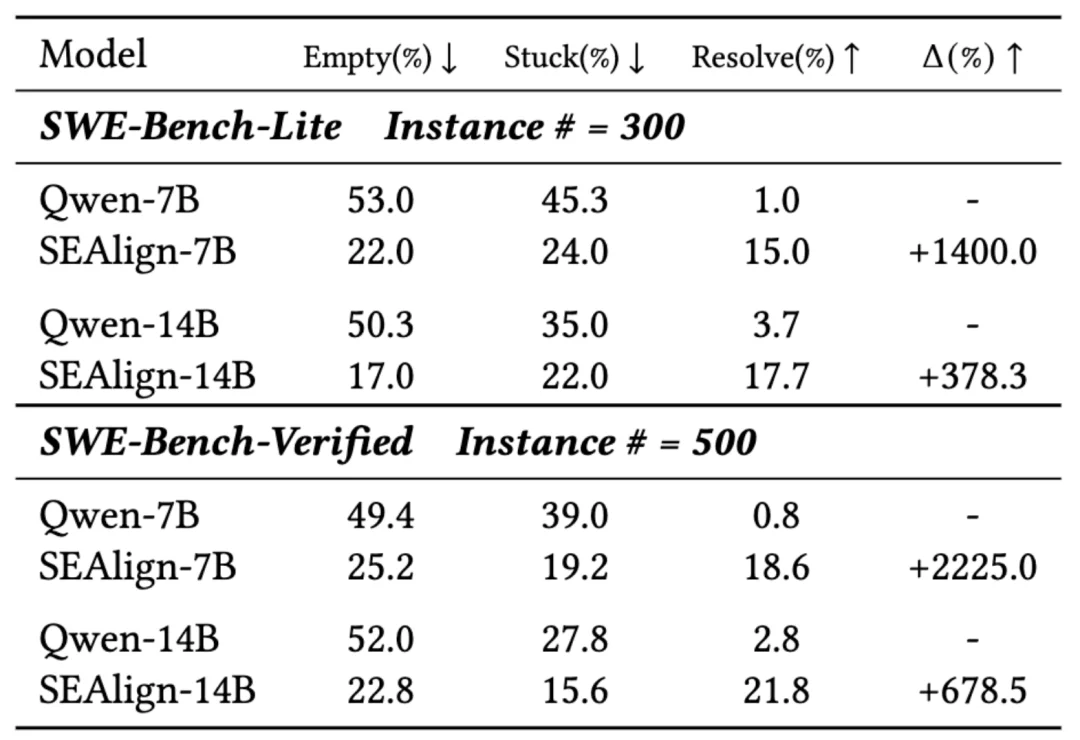
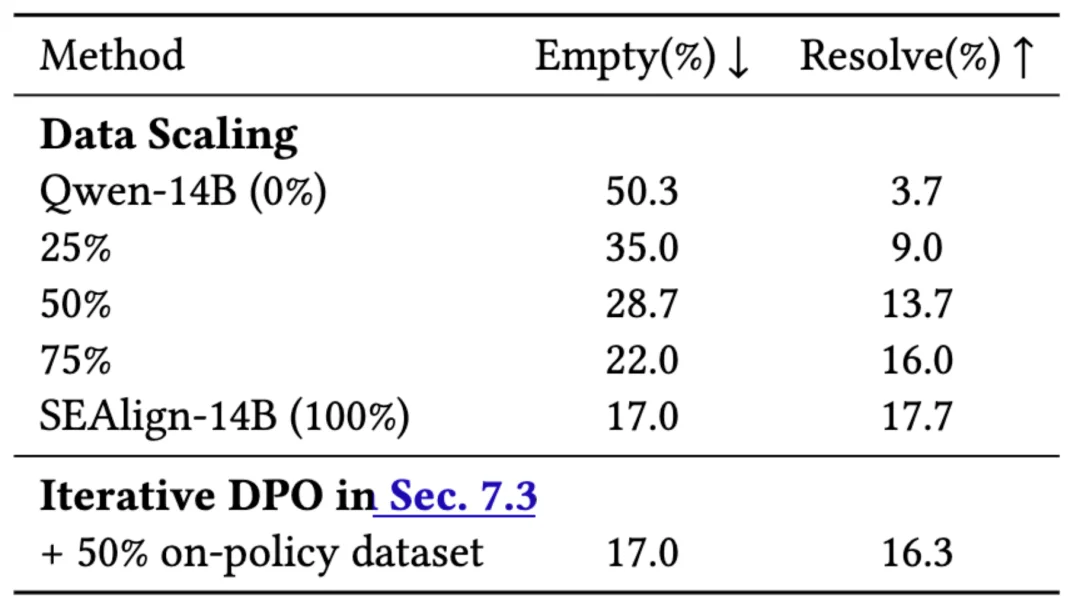
在 Qwen2.5-Coder-Instruct-14B 上的实验显示,SEAlign 的训练方法使得该模型 在 SWE-Bench-Lite 上的问题解决率从 3.7% 提升到 17.7%;在 SWE-Bench-Verified 上,则从 2.8% 提升到 21.8%。
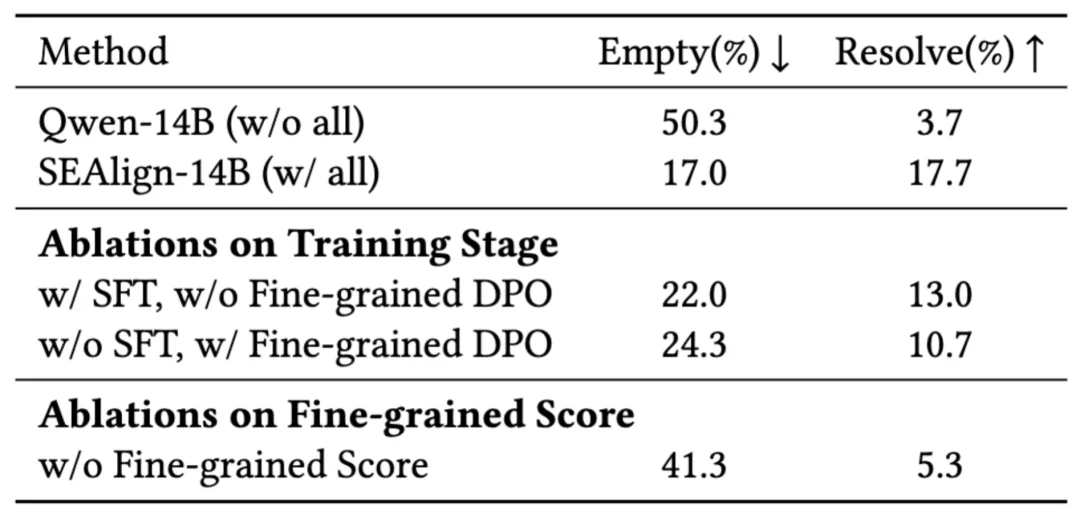
与此同时,基线模型中非常常见的两类问题 —— 空补丁率(empty patch)和循环卡死率 (stuck-in-loop) 也显著下降:例如在 SWE-Bench-Verified 上,14B 基线模型的空补丁率(empty patch)为 52.0%、卡死率(stuck)比例为 27.8%,而 SEAlign-14B 分别降至 22.8% 与 15.6%。这说明 SEAlign 能够系统性改善模型在 Agent 框架中的行为过程。
为了验证 SEAlign 学到的不是对某一个类 Benchmark 的过拟合,论文进一步在 HumanEvalFix 这一类程序修复任务上进行实验。
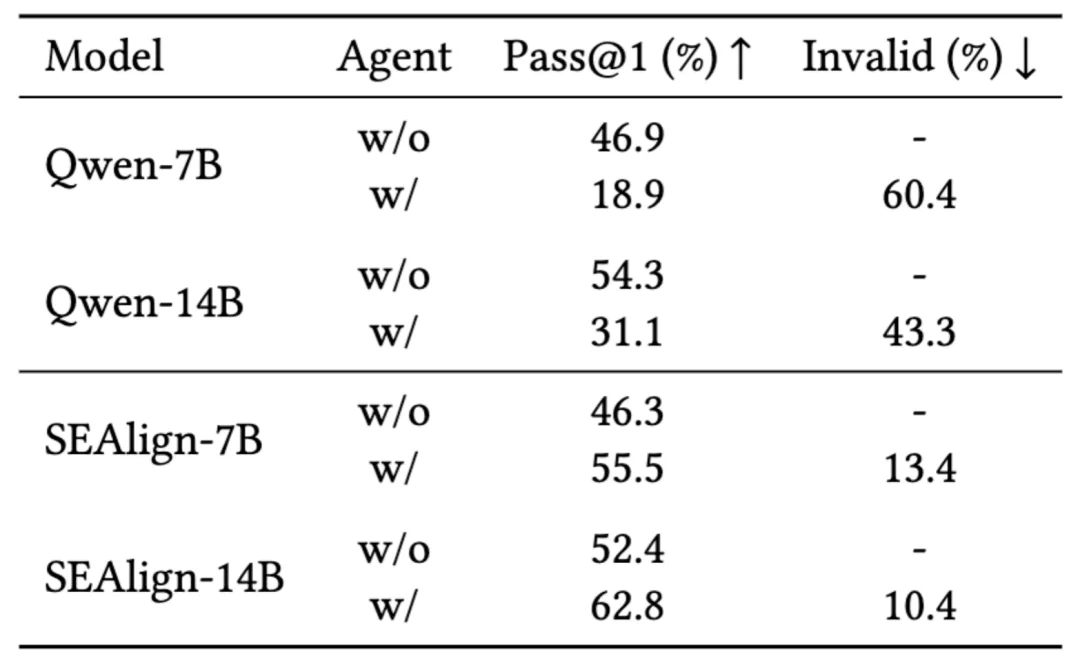
对 Qwen-2.5-Coder-Instruct-14B 而言,不使用 Agent 框架时代码修复通过率(Pass@1)为 54.3%,一旦放入 Agent 工作流中,反而掉到 31.1%,说明它虽然会直接写代码,却并不擅长在工具交互流程中行动。
相反,SEAlign-14B 在无 Agent 时的通过率为 52.4%,加入 Agent 后则提升到 62.8%,同时无效补丁率( invalid patch rate )降到 10.4%。
这表明 SEAlign 的收益并不只体现在 SWE-Bench 这种复杂仓库任务上,也确实提高了模型在工具辅助、多步交互场景下的稳定性与泛化能力。
论文的消融实验进一步说明,SEAlign 的关键在于其对细粒度关键动作优化本身。
数据规模实验也显示出较清晰的趋势:随着训练数据从 25% 增加到 50%、75% 和 100%,SWE-Bench-Lite 上的解决率从 3.7% 稳步提升到 17.7%。
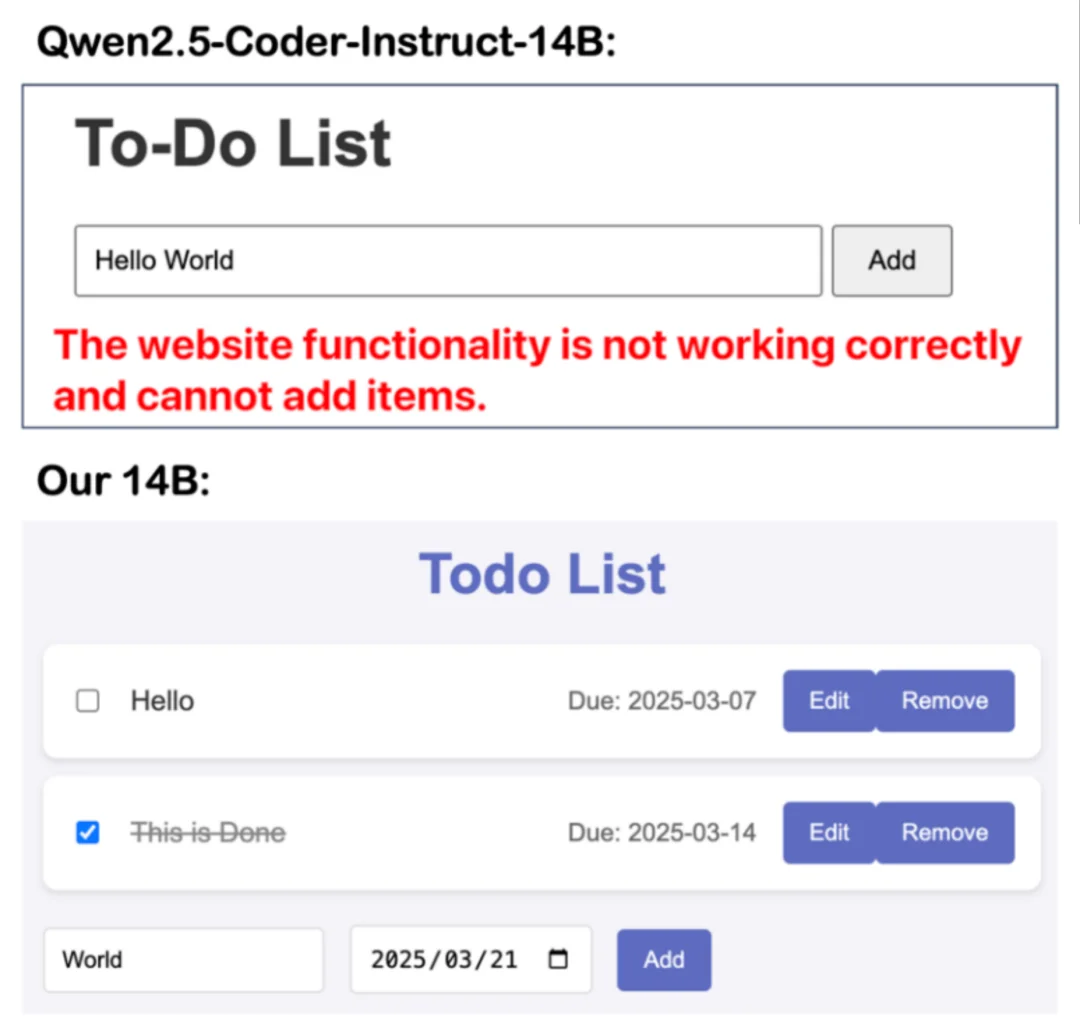
除了标准的智能体 Benchmark,论文还手工设计了五类简单的应用开发任务,包括 to-do list、贪吃蛇小游戏、天气应用、Hacker News 查询应用和个性化主页,并邀请 5 名有至少一年开发经验的志愿者从功能完整性、代码质量和美观度三个维度进行评分。
平均结果显示,SEAlign-14B 相比原始 Qwen-14B 都有明显提升:功能完整性从 1.8 提升到 3.1,代码质量从 2.7 提升到 3.5,美观度从 2.0 提升到 3.2,SEAlign 更接近真实用户感知的开发体验改进。
总体来看,SEAlign 揭示了一个极具现实价值的核心命题:代码模型在真实软件工程中的关键能力,不仅在于写好代码本身,更在于如何在工程流程中持续做出正确决策。
围绕轨迹对齐、工具使用、关键阶段控制与过程级的模型训练优化,SEAlign 对于代码智能体和模型的协同演进,以及保证智能体模型在长序列复杂任务上能够平稳运行都至关重要。这也为代码模型走向实用化、工程化提供了一条可行路径。
文章来自于"机器之心",作者 "张克驰"。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
