# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI 真的理解世界吗?
当一个杯子从桌面掉落,大语言模型可以告诉你 “它会碎”,却无法推演这个过程:它如何下落?碎片如何飞散?液体如何溅开?
这揭示了一个关键问题:语言只是对世界的抽象描述,它可以表达结果,却无法刻画过程。真实世界并不是符号组成的,而是连续变化的物理系统。
相比之下,视觉直接记录了世界的演化 —— 物体的结构、运动以及背后的因果关系,都体现在视觉信号中。这使得视觉成为 AI 学习世界变化最直接、最完整的信息来源。

图 1:语言只能对事件结果进行抽象概括,而视觉才能呈现世界变化的连续过程。
这也是为什么越来越多研究者如 Yann LeCun,Fei-Fei Li 等开始重新思考:如果世界模型是通向通用智能的关键,那么它的起点不应该是语言,而应该是视觉。
人类理解世界,不只是 “说出结论”,而是 “看见变化”。视觉世界模型的目标,正是让 AI 通过视觉学习世界的运行规律,并据此推演未来。
为了理清视觉与世界模型之间的深层联系,并为该领域的未来研究提供一张清晰的脉络图,北京交通大学靳潇杰、魏云超、赵耀等学者联合新加坡国立大学、腾讯、字节等国内外研究机构知名学者,发布了首篇视觉世界模型长篇综述:From Seeing to Knowing the World: A Survey of Vision World Models。
这项工作提出了一次关键的概念转变:视觉不应仅仅被视为一种输入模态,而应成为塑造世界模型表征方式、学习机制以及评估体系的核心驱动力。 在这一 “以视觉为中心” 的视角下,研究团队不仅首次系统性定义了视觉世界模型,还构建了一个贯通 “表征 - 学习 - 模拟” 的统一分析框架,在同一框架下重组四大技术路线、厘清评测体系,并进一步提出面向下一代世界模型的关键研究方向。调研的最新进展截止至 2026 年 4 月 1 日。

1. 为什么现在需要一篇视觉世界模型综述?
世界模型已经成为当前 AI 研究中最受关注的话题之一,该方向的发展跨视频生成、表征学习、具身智能、自动驾驶等多个研究社区。这些路线普遍开始依赖视觉信号,但在多数范式中,视觉仍更多被视为一种观测输入:视频生成方法更关注未来内容的视觉逼真度与时空一致性,表征预测方法强调在潜在空间中捕捉世界演化的预测结构,而状态转移和具身智能相关方法则更重视基于紧凑状态进行长时程推演与决策支持。

图 2:视觉世界模型研究技术路线。上半部分梳理主流模型架构,下半部分归纳不同领域中的数据集与评测基准。
虽然这些路线都在尝试回答 “AI 如何从视觉中建立对世界变化的内部模型” 这一核心问题,但它们长期沿着各自的范式独立发展,存在定义不统一、分类彼此割裂、评测标准难以对齐等问题。
也正因如此,当前迫切需要一篇真正以视觉为中心、能够在统一框架下重新组织这一领域的系统综述。相比于单纯汇总已有工作,这篇综述更重要的地方在于提出了一次关键的视角转换:视觉不应仅仅被视为世界模型的输入模态,而应成为定义模型如何表征世界、学习规律与评估能力的核心出发点。
2. 视觉世界模型统一框架
团队首先给出了 VWM 简洁且明确的定义:视觉世界模型能够从视觉数据中学习世界知识,并基于交互条件生成未来世界状态。
并将 VWM 的研究统一为一个框架内的三个核心组件:
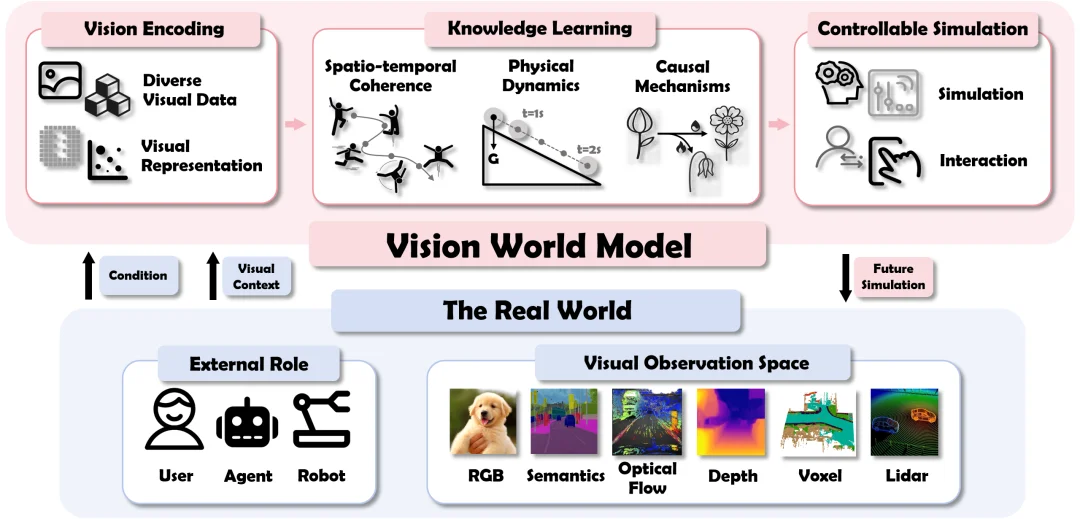
图 3:视觉世界模型统一框架。从视觉编码、知识学习到可控模拟,系统刻画 VWM 如何从观测中学习世界规律,并在交互条件下推演未来,实现闭环模拟。
这个框架的重要性在于,它第一次比较系统地回答了:一个视觉世界模型到底应该学什么,靠什么学,又该如何被控制和评估。
3. 当前视觉世界模型,主要分成哪几条技术路线?
依据上述统一框架,现有方法可被归纳成四大代表性范式,包含七种子范式。研究团队不再把这些路线割裂开,而是放到同一套框架下进行比较。
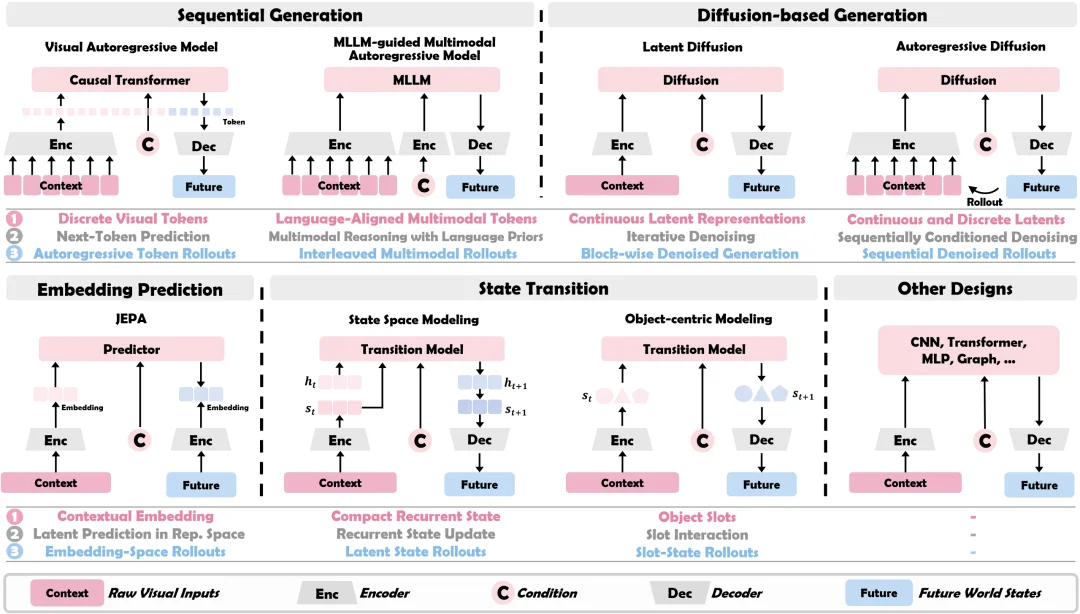
图 4:视觉世界模型方法架构图。每类范式上半部分展示模型架构,下半部分给出其如何实现视觉编码、知识学习和可控模拟的过程。
1. 序列生成(Sequential Generation)
通常会把图像或视频转成 token 序列,然后像语言模型一样一步一步预测未来。它的优势是可扩展性强、适合长上下文,缺陷是长时预测易出现误差累积和漂移,对精细几何、物理交互的模拟效果有限。子范式包括基于视觉自回归的世界模型(visual autoregressive model),以及与大语言模型对齐的多模态自回归世界模型(MLLM-guided multimodal autoregressive model)。
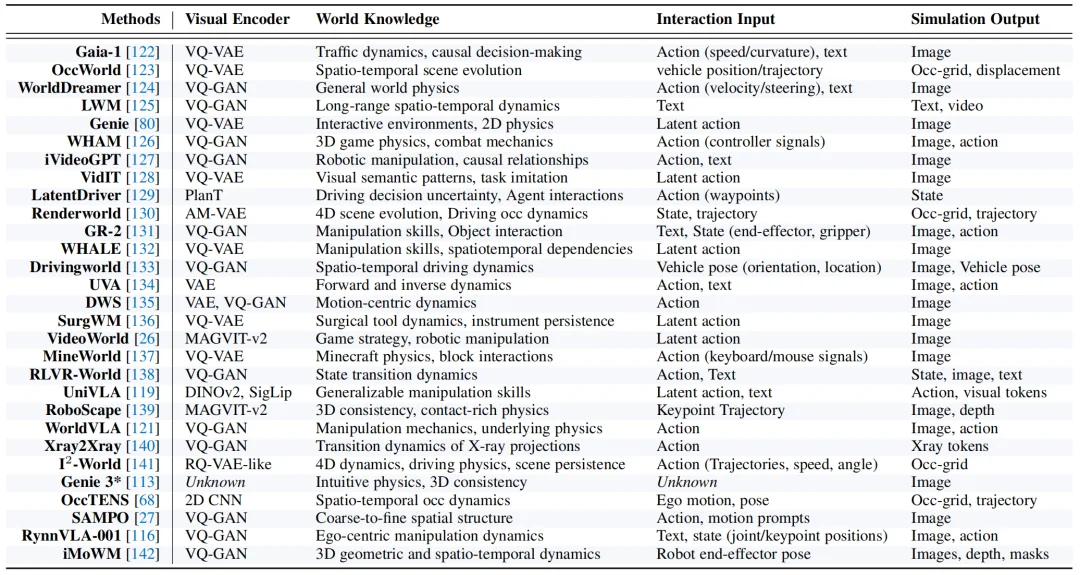
图 5:视觉自回归视觉世界模型代表方法总览。每个方法分析其视觉编码器、所学习的世界知识、交互输入和模拟输出类型。
2. 扩散生成(Diffusion-based Generation)
通常在连续潜空间中通过迭代去噪生成未来。在视觉质量上更强,也更适合生成连贯、逼真的未来片段,但代价是推理开销更大。子范式包括经典的潜空间扩散世界模型(latent diffusion)和当前的主流思路自回归扩散世界模型(Autoregressive Diffusion)。

图 6:扩散生成视觉世界模型代表方法总览。
3. 表征预测(Embedding Prediction)
不执着于生成完整视频,而是直接预测未来的 embedding。这样的好处是能把重点放在 “学规律” 而不是 “画细节” 上,更适合规划、推理和效率优先的场景。但其缺点是可解释性相对较弱。该范式的典型代表是 JEPA 系列。
4. 状态转移(State Transition)
将视觉输入压缩为紧凑的隐状态,通过递归状态转移建模世界随时间的演化。该类范式在潜空间 rollout 高效,递归状态能够持续保留历史信息,是早期世界模型的主流思路。子范式包括经典的状态空间世界模型(State Space Modeling)和具有组合泛化能力的基于对象的世界模型(Object-centric Modeling)。
4. 评估指标与基准:视觉世界模型怎么评?用什么评?
如果说前面的章节回答的是视觉世界模型是如何设计的,那么评测部分回答的就是另一个更关键的问题:什么样的视觉世界模型才算得上好?

图 7:视觉世界模型评估体系概览。包含三类评估指标和两组数据集与基准分析。
首先是怎么评。团队给出的答案很明确:仅仅生成出清晰、逼真的画面还远远不够。一个可靠的视觉世界模型,至少要同时满足三层要求:看起来真实、演化过程合理、并且能够真正支持任务决策。 基于这一判断,团队将现有评估指标统一整理为三大类:
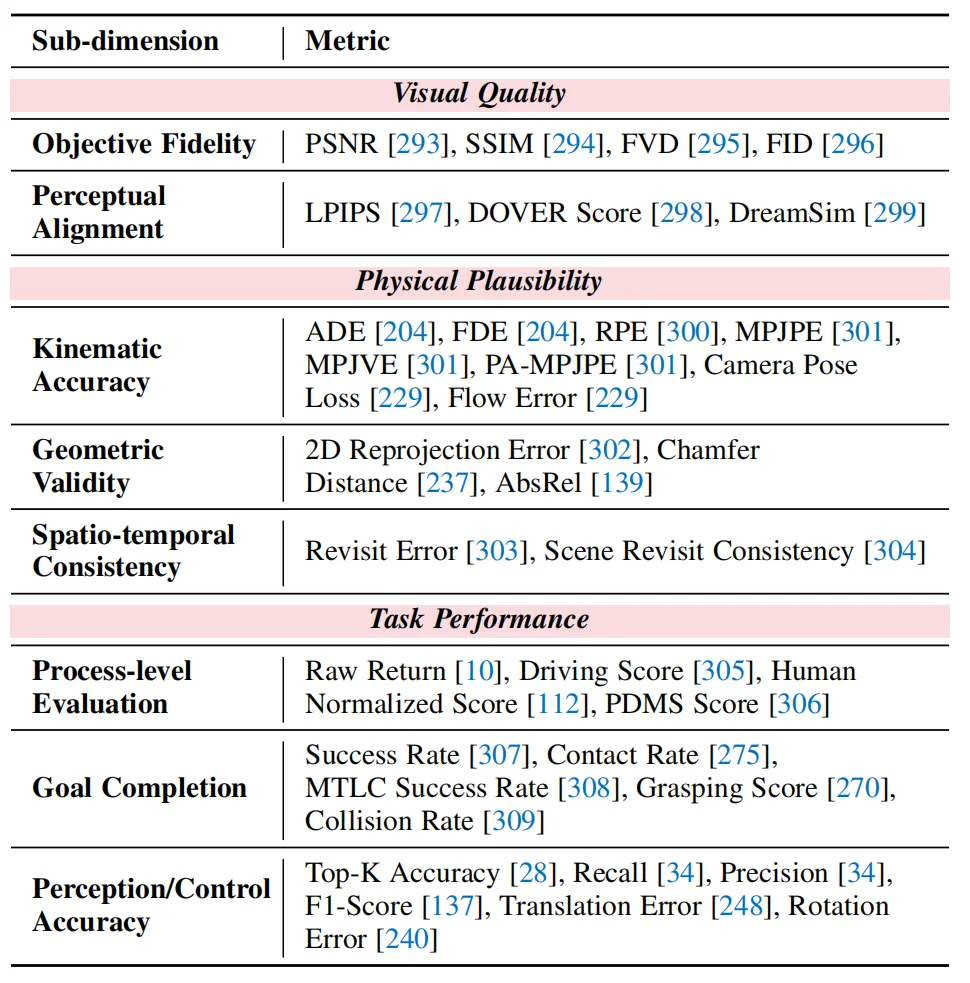
图 8:三类评估指标总览。
接下来是用什么评。如何测试这些能力呢?团队系统梳理了视觉世界模型常用的数据集和基准,并把它们分成两大组:基础世界建模(Foundational World Modeling)和针对特定领域的世界建模(Domain-specific World Modeling)。
基础世界建模旨在考察模型对通用物理世界法则的掌握程度,不局限于特定任务:
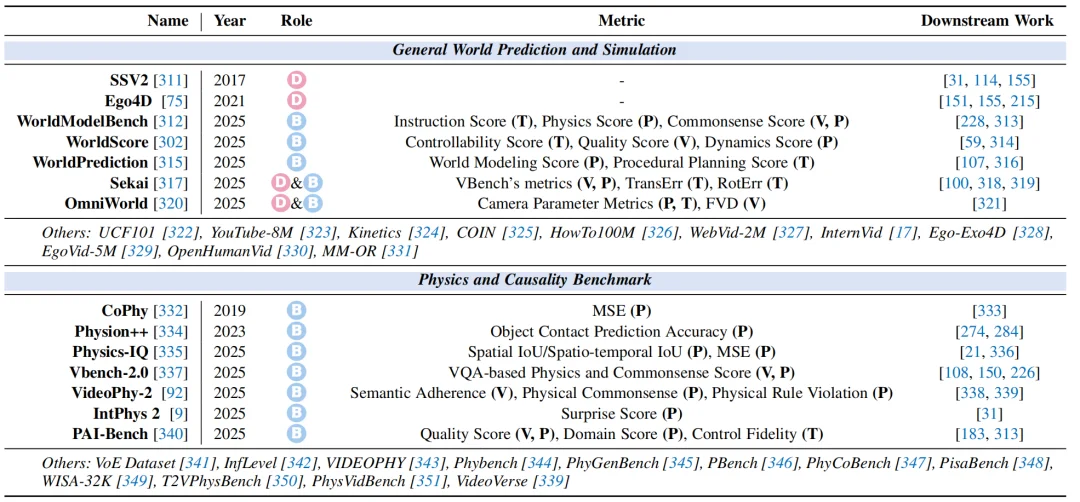
图 9:基础世界建模数据集与基准总览。
针对特定领域的世界建模则关注模型在具体应用场景中的实际表现:
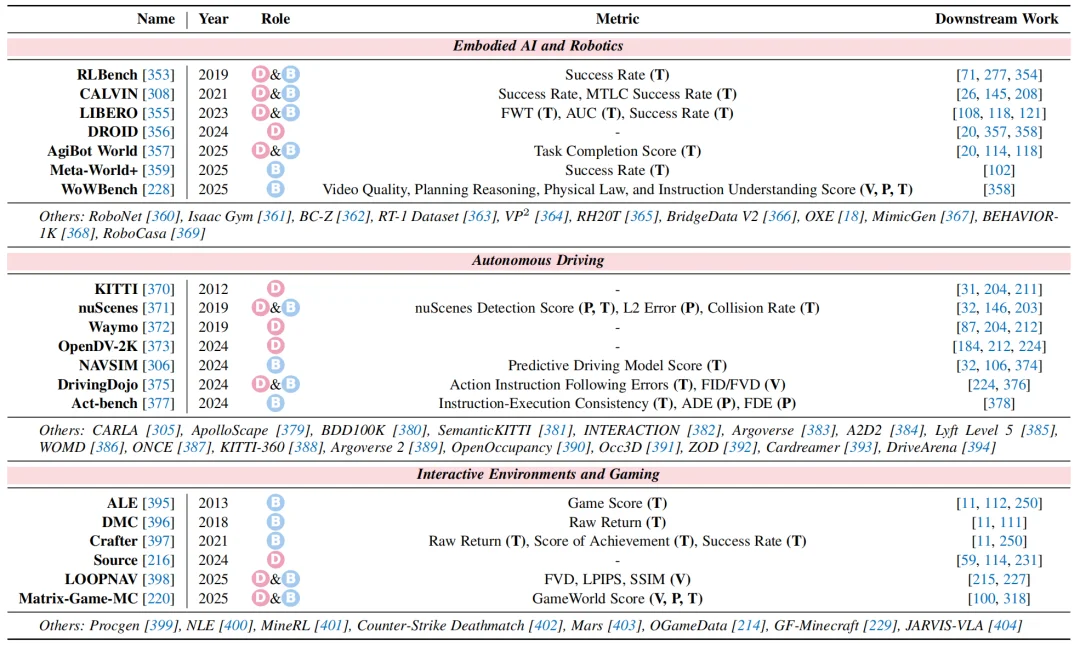
图 10:针对特定领域的世界建模数据集与基准总览。
5. 下一代世界模型,何去何从?
尽管目前的 VWM 已经能生成令人惊艳的视觉画面,但只要遇到复杂的物理交互、罕见的边缘场景或是需要严谨因果推理的任务,它们往往产生违背常理的幻觉。
从 “生成逼真画面” 走向 “支撑 AGI 的基础设施”,下一代世界模型路在何方?团队在综述中指出了三个至关重要的突破口:3R 路线图(Re-grounding, Re-evaluation, Re-scaling)。
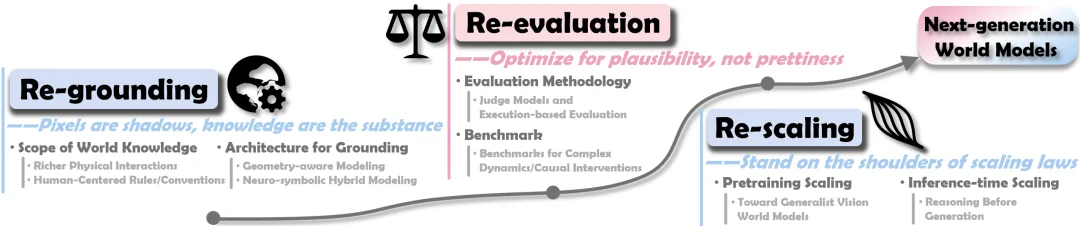
图 11:下一代世界模型核心挑战与未来方向。
1. 夯实知识基础(Re-grounding):走出简单的物理模拟和画面生成,去面对真实世界的复杂性。
2. 重构评估体系(Re-evaluation):用实战和反事实检验真伪。
3. 重塑 Scaling Law(Re-scaling):迈向更通用的世界模型。
写在最后
大语言模型构建的知识,本质上是对人类文本经验的概率总结;而真实世界的运转,遵循的是连续的物理法则与因果链条。视觉世界模型的使命,正是打破符号的局限,直击物理现实的演化规律。
从 “基于语义关联得出结论” 到 “基于世界常识模拟未来”,这不仅是世界模型研究的一次范式推进,也可能是 AI 走向更强预测、交互与决策能力的关键一步。
完整文献整理与归纳、详细架构对比与技术路线图,欢迎前往我们的论文与项目主页详细阅读!
作者介绍
余萧

北京交通大学计算机学院博士生。获得国家奖学金两次,发表 CCF-A 类论文一篇,曾参与 VideoWorld 2 项目。研究方向为视觉世界模型,遵循物理与因果规律的世界模型等。
靳潇杰

北京交通大学计算机学院教授 / 博导,国家高层次青年人才,曾任字节跳动美国研究院创始成员和技术负责人。研究方向为多模态智能、世界模型、高效深度学习等。
文章来自于微信公众号 "机器之心",作者 "机器之心"



