# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
机器人看得见,但不一定看得准。
大量VLA模型仍然主要依赖二维视觉,一旦遇到精定位、细摆放、遮挡判断这类需要空间感知的任务,成功率就会明显下滑。
补空间信息的路有两条,但都有代价。
显式3D路线靠深度传感器和点云重建,硬件链路长、对标定误差敏感;隐式3D路线从RGB学几何,省了硬件,但不少方案依赖较重的基础模型,训练和推理成本偏高。
现在,上海交大MINT团队提出了一条中间路线:
Evo-Depth,约0.9B参数,不额外增加硬件负担,用紧凑的隐式深度编码把空间感写进VLA策略里,仿真与真机同时兼顾性能与部署效率。

仿真端,Meta-World 84.4%、LIBERO 95.4%;真机平均成功率约90%;部署侧约3.2 GB显存、约12.3 Hz推理频率。
代码、权重、训练脚本已全面开源。
直入主题,Evo-Depth的核心思路是:
从多视角RGB提取紧凑的隐式深度表征,再以轻量方式融入视觉-语言通路,最后通过flow-matching动作专家输出连续动作。
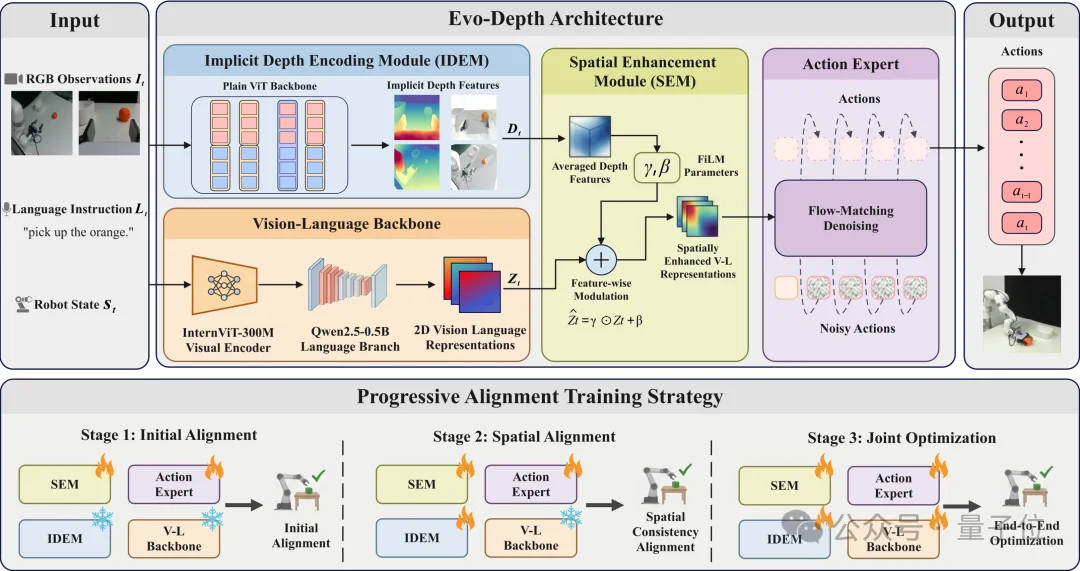
整个系统主要由三部分组成:
1、IDEM:Implicit Depth Encoding Module。
IDEM负责从多视角图像中提取隐式深度特征,强调空间布局与相对几何关系,而不是显式生成高成本的3D中间表示。
论文中,IDEM骨干约0.13B参数,并结合多视角深度预训练初始化,在轻量条件下引入与深度相关的归纳偏置。
2、SEM:Spatial Enhancement Module。
SEM将隐式深度作为一种调制信号,用于增强视觉-语言表征。
相比直接增加独立深度分支,这种融合方式更克制:
3、Progressive Alignment Training。
多模块联合训练通常容易出现优化不稳定的问题。
为此,作者采用Progressive Alignment Training,通过分阶段训练方式逐步完成:深度表征对齐-多模态融合-动作学习。
动作头则采用了当前VLA中较常见的flow-matching路线。
在约0.9B总参数设置下,论文报告的结果如下。
值得注意的是,相比只关注benchmark分数,论文也给出了部署侧开销与实时性指标。
对于需要真正运行在机器人控制回路中的VLA来说,这部分信息往往同样重要。
归根结底,Evo-Depth解决的问题其实就是一句话:
如何在不显著增加系统负担的情况下,提升VLA的空间能力。
结果是——相比纯二维VLA,它补充了空间信息;相比更重的3D路线,它又尽量保留了部署效率。
对于正在做机器人操作、空间智能或VLA系统的团队来说,这类性能-成本-实时性之间的折中方案,可能会越来越重要。
官方仓库:https://github.com/MINT-SJTU/Evo-Depth
模型权重:https://huggingface.co/MINT-SJTU/EVO-Depth-LIBERO
文章来自于"量子位",作者 "上海交大MINT团队"。



