# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
说在前面:这又是一篇讲Harness的Survey,你最近可能已经看过了数篇讲Harness的文章、论文,其中还可能包括我上周解读的《Agent Harness Engineering:Agent的底盘工程综述|CMU、耶鲁、Amazon》。
上周的《Agent Harness Survey》更像是在回答一个系统架构问题:一个真正可用的 Agent,外面应该包哪些东西?
而UIUC、Meta、Stanford这篇最新综述关心的是另一个问题:当Agent被放进长期任务环境里,真正把推理、行动、反馈、验证和协作串起来的操作对象是什么?
他们给出的答案是:代码化的执行过程。

这里的“代码”不是指Agent框架本身由代码写成,这当然是常识。它指的是Agent在执行任务时不断生成、运行、修改、保存和共享的一系列中间物。具象到实际的工程场景中,就是Claude Code生成的Plan.md,或者产出的Skills.md,验证用的Python文件等等。
这篇综述原文长102页,引用Reference有478篇,本文将为您直接抽丝剥茧,用最快的速度看懂这三大顶级机构是如何打通Claude Code到机器人Agent的底层运行逻辑的。
在深入技术细节之前,我们需要先明确几个核心概念。
一个纯粹的大语言模型是无状态的,它本质上只是在预测下一个词。为了让它变成一个能够执行长期任务的“智能体”,我们需要在模型外围包裹一层软件基础设施。这层基础设施包括:
这整套外围系统,就被研究者称为智能体脚手架(Agent Harness)。
研究者指出,代码具备自然语言所不具备的三大核心特质:
基于这三大特质,研究者构建了一个三层架构来系统性地拆解代码在智能体中的作用:脚手架接口层、脚手架机制层以及多智能体扩展层。
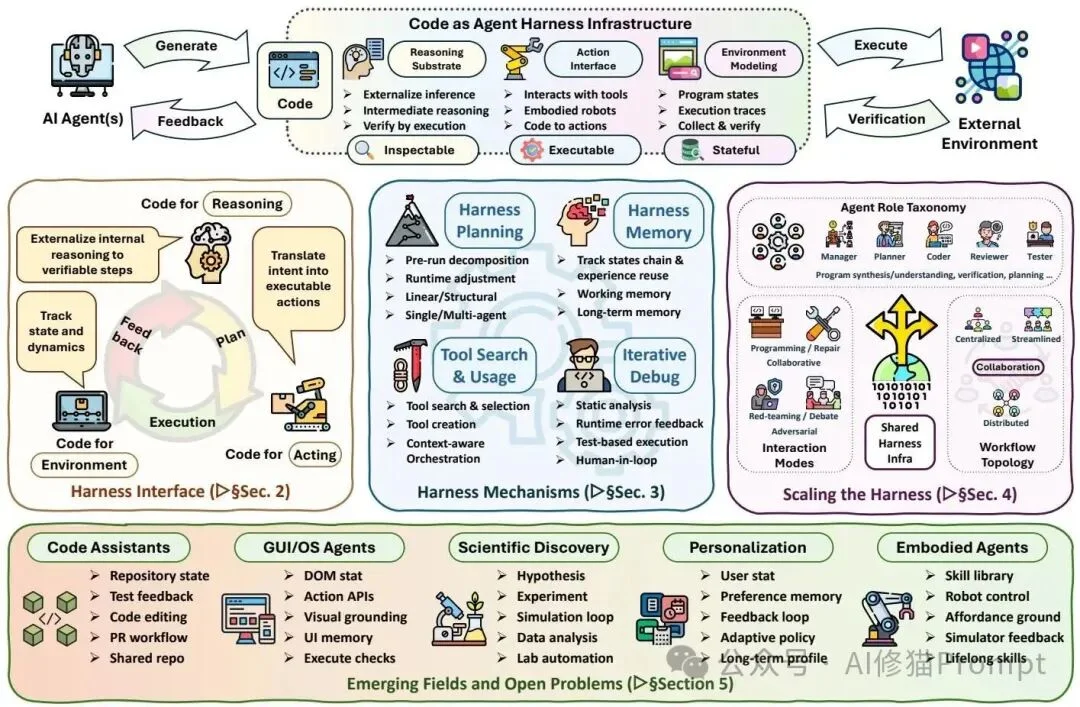
论文将代码作为智能体脚手架拆成三层:接口层让代码承载推理、行动和环境建模,机制层负责规划、记忆、工具、控制与优化,多智能体层则把代码仓库、测试、轨迹和执行状态变成协作基底。
在这一层,代码充当了智能体与现实世界沟通的基础接口。它具体表现在三个方面:用于推理、用于行动、用于环境建模。
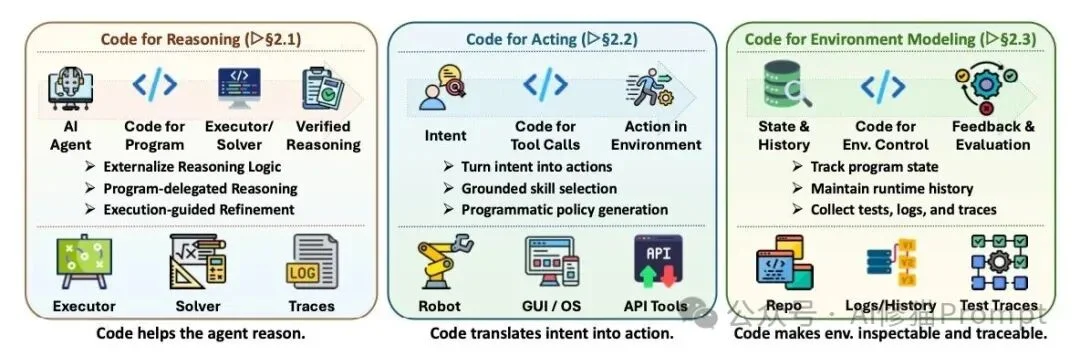
接口层的核心是把模型输出接到可执行程序、工具调用、状态跟踪和反馈轨迹上,使推理可验证、行动可落地、环境变化可观察。
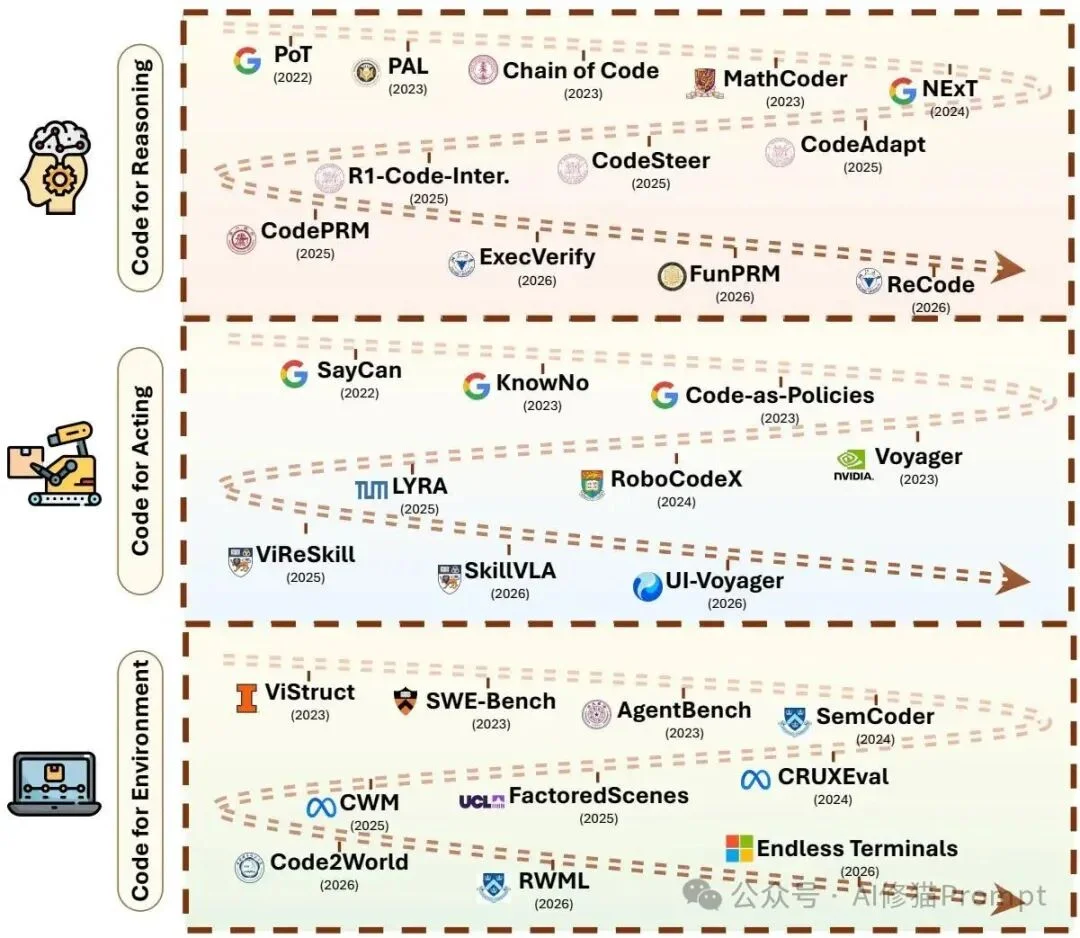
论文按代码在推理、行动和环境建模中的不同角色整理代表工作,展示这一层如何从程序辅助推理扩展到机器人控制、GUI/OS操作和软件工程评测环境。
早期的智能体通常依赖纯文本的“思维链(CoT)”进行推理,但这往往会导致逻辑错误或计算不准确。将推理过程转化为代码,可以让外部解释器或求解器来验证逻辑。
当智能体需要与物理世界(机器人)或数字世界(软件GUI)互动时,代码就成了它的执行载体。
环境的状态往往是复杂且动态的,用纯文本很难精确描述。代码可以将环境具象化为可操作的对象。
有了底层的接口,智能体还需要一套复杂的机制来保证它在长达数小时甚至数天的任务中不崩溃。研究者将这些机制归纳为五大模块。
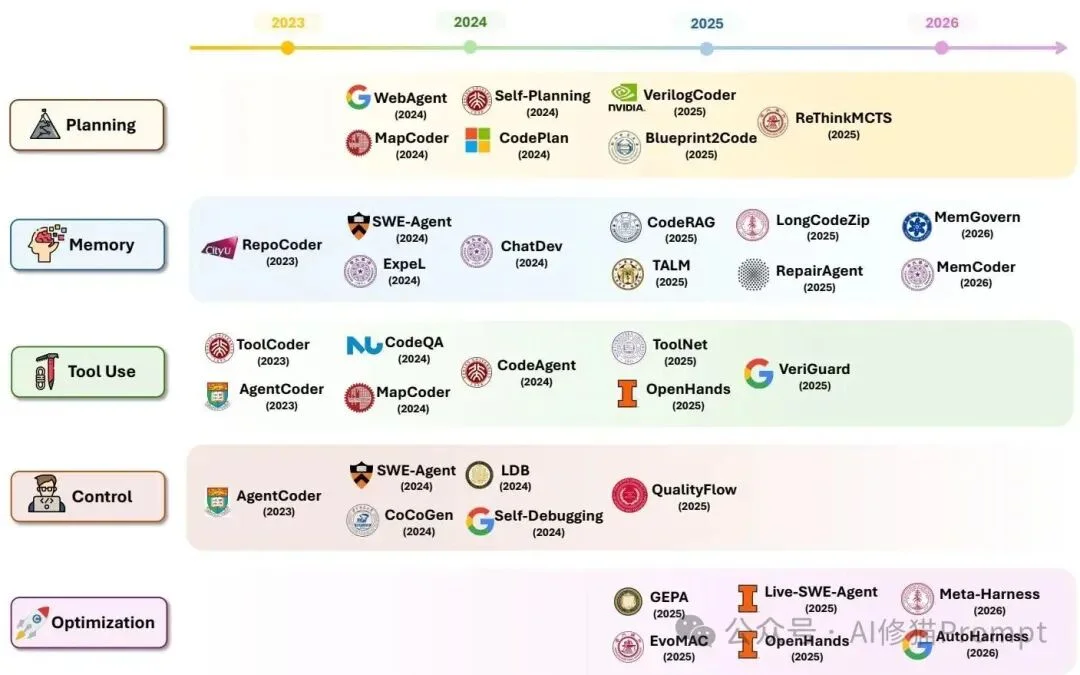
机制层覆盖规划、记忆、工具使用、控制循环和脚手架优化五类问题,强调智能体可靠性来自模型判断、可变任务状态和受治理的运行时基础设施共同作用。
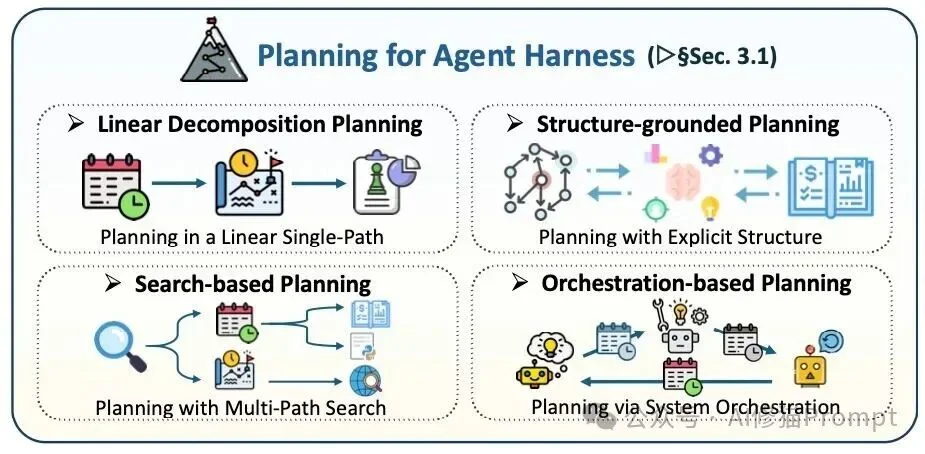
处理复杂的软件工程任务,智能体必须要有清晰的执行路径。规划机制可以是单路径的步骤拆解,也可以利用显式结构、多路径搜索或系统级工作流编排来控制长周期任务的执行轨迹。
PLAN.md 文件),智能体严格按照步骤生成代码。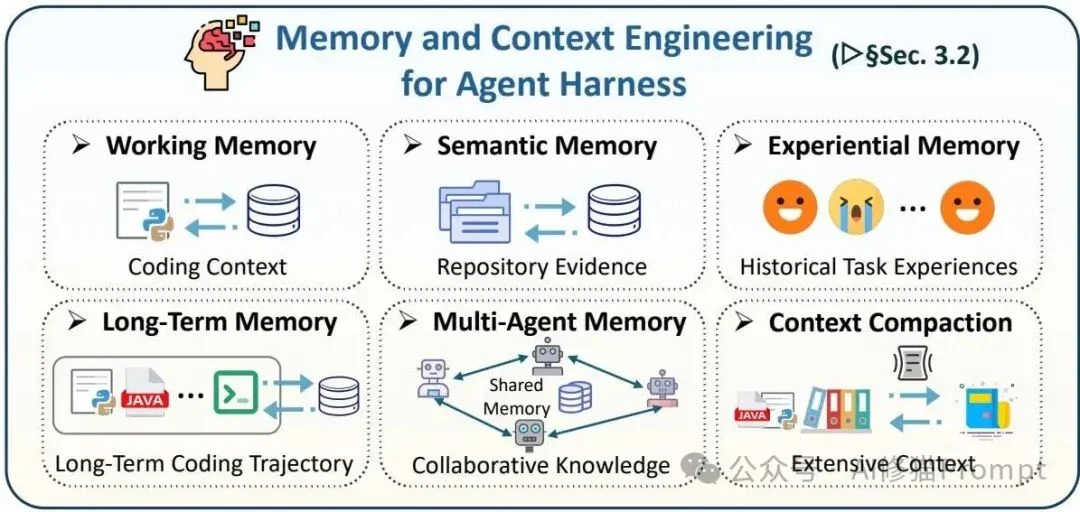
处理百万行级别的代码库,大模型极其容易受困于上下文长度限制,因此需要极强的内存治理方案。记忆层把工作记忆、语义记忆、经验记忆、长期记忆、多智能体记忆以及上下文压缩统一到同一个状态治理问题中,目标是在有限上下文内保留真正影响任务成败的证据。
工具是智能体改变外部世界的手段,但在代码脚手架中,工具的使用必须受到严格的管控。
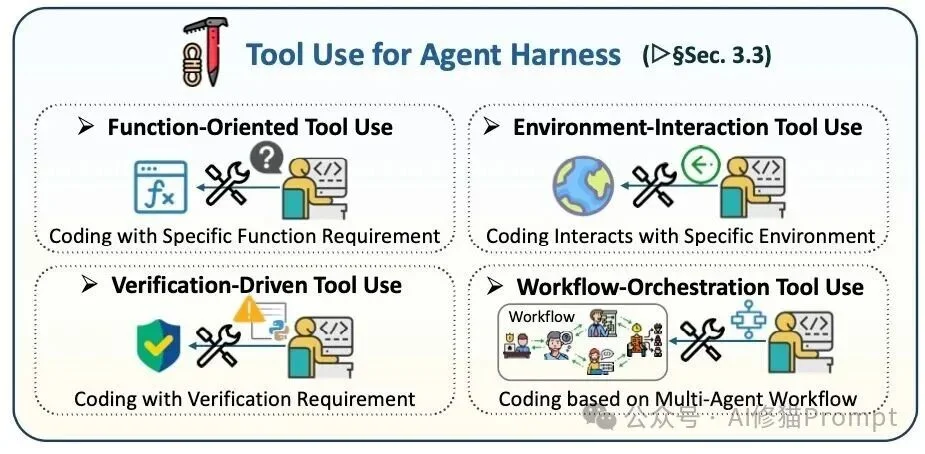
工具层不仅包括函数调用和外部API,也包括终端、仓库、沙盒、验证器和多步骤工作流;关键问题是让工具可发现、可调用、可审计并能在失败时恢复。
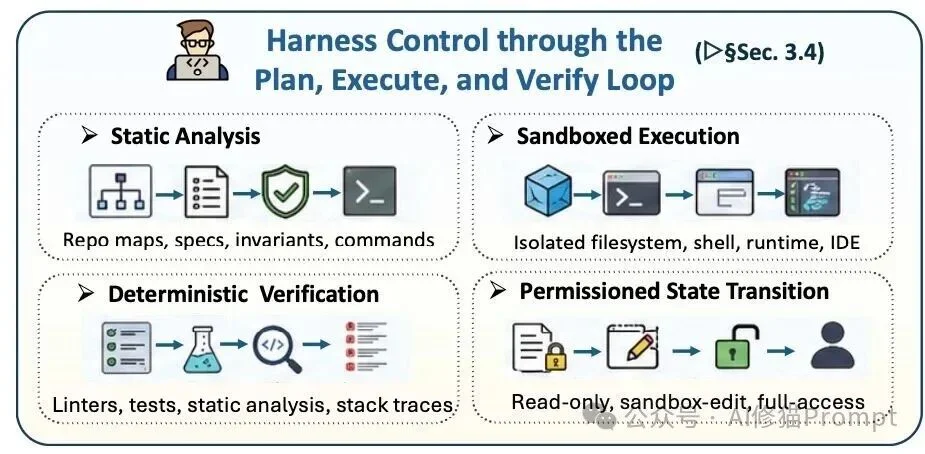
研究者指出,Agent的调试过程本质上是一个控制论问题,应当被框架化为PEV循环(Plan-Execute-Verify)。PEV循环将规划、沙盒执行、静态/动态验证和权限控制组织成可重复的状态转换流程,使智能体的每次修改都能被观测、判断和必要时回滚或升级给人类。
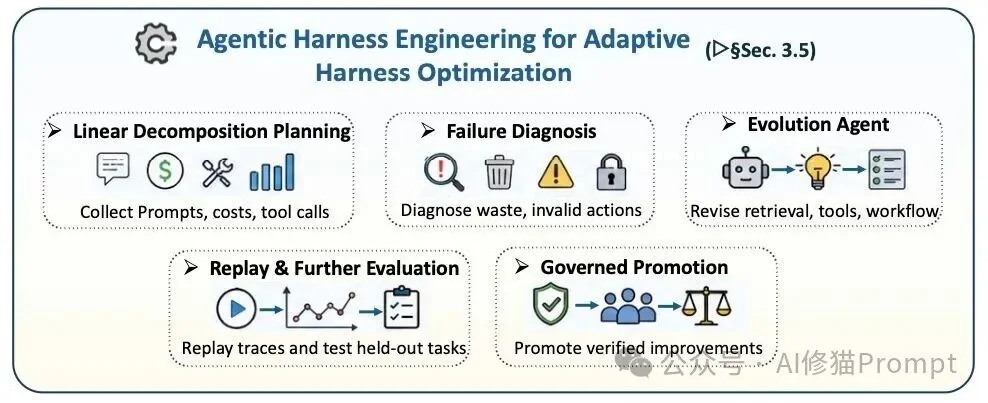
这是该论文提出的一个极其前沿的概念。系统不应该仅仅停留在修复代码本身,还应该能够自动优化包围在模型外围的“脚手架”。自适应脚手架工程把提示词、检索策略、工具描述、验证器、权限规则和工作流本身都视为可优化对象;但这些修改必须经过轨迹回放、保留任务评测和治理规则约束。
面对真实的、极度复杂的企业级需求,单智能体的上下文和能力很容易达到瓶颈。引入多智能体协同(MAS)是必然趋势。在这个阶段,代码正式成为了各个智能体之间沟通、协同与达成共识的“共享基底”。
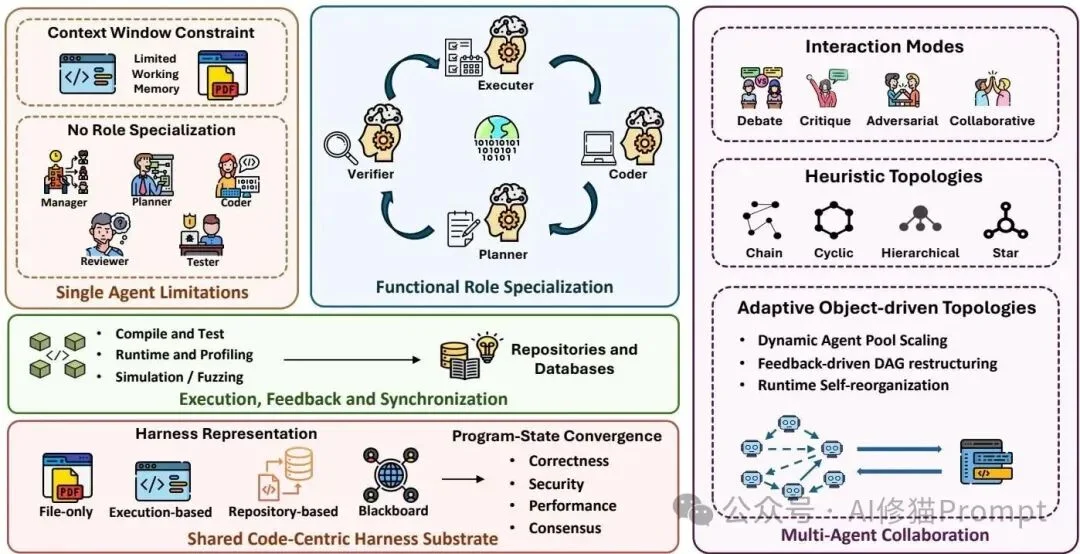
多智能体扩展层通过角色专业化、共享代码基底、执行反馈和自适应协作拓扑,缓解单智能体在上下文、专业能力和自我纠错上的瓶颈。
系统会模仿人类的软件开发团队,拆分出高度专业化的角色:
研究者严厉指出,目前许多多智能体系统仅仅依靠“聊天记录”来传递信息,这会导致严重的“状态发散”,不同智能体对代码当前到底是什么样产生了认知错位。
未来的多智能体系统必须建立基于代码的客观全局共享状态:
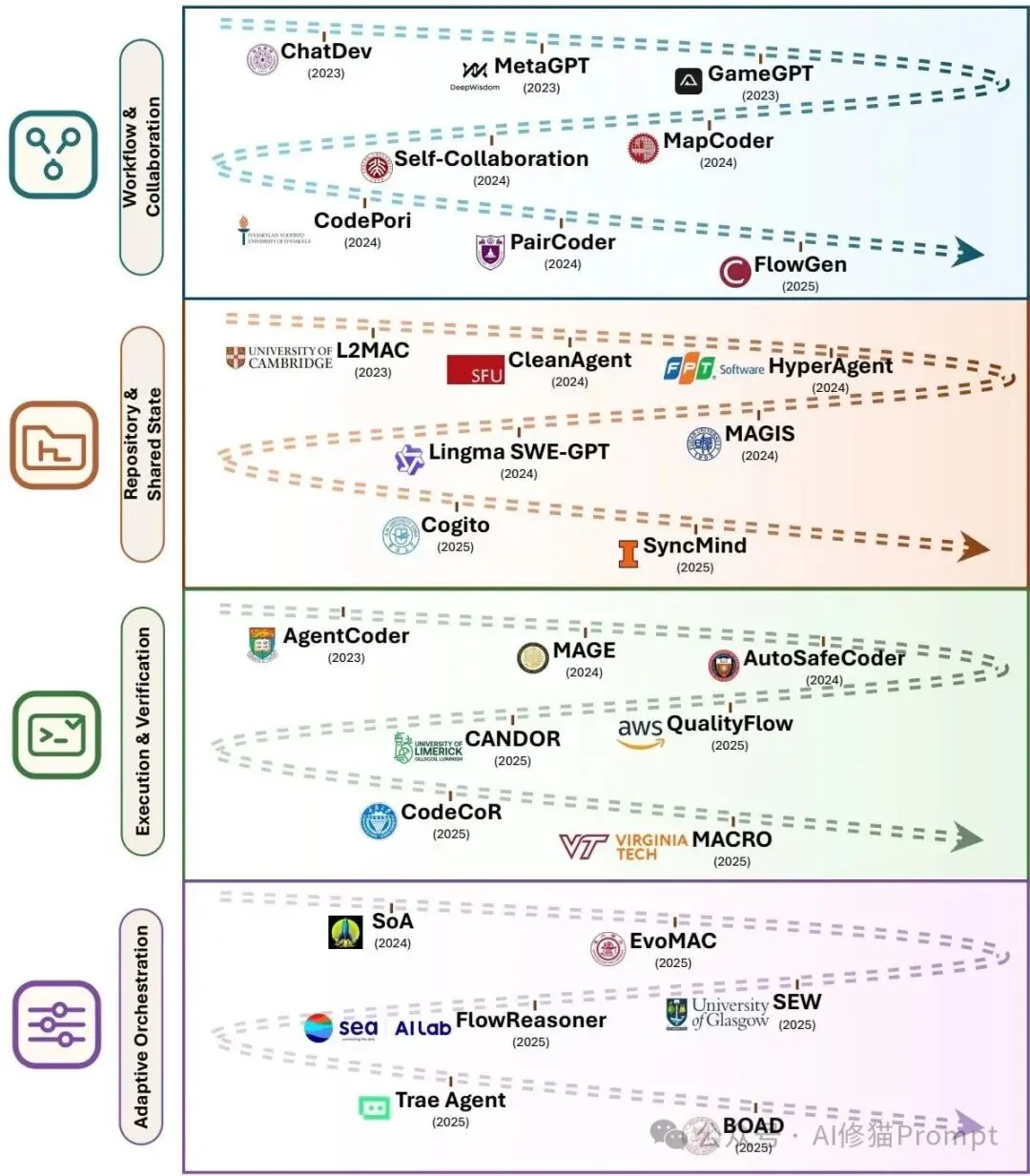
论文进一步把多智能体协同拆为工作流协作、共享仓库状态、执行验证和自适应协调四类问题,强调协作必须落在可检查的程序状态上,而不是只停留在对话记录中。
“代码作为智能体脚手架”的理念,目前已经在以下五个真实应用场景中落地开花:
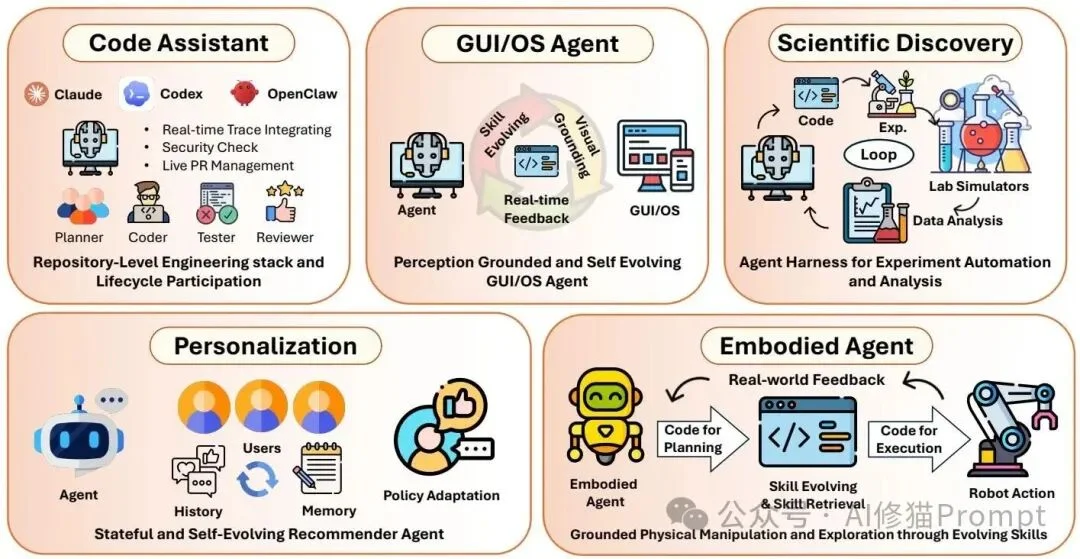
论文将落地场景概括为代码助手、GUI/OS智能体、科学发现、个性化推荐和具身智能体,说明代码脚手架正在从软件工程扩展到数字界面、科研流水线和物理世界控制。
从早期的单纯代码补全(如早期的Copilot),进化为能够处理GitHub Issue的“自动化研发员工”(如SWE-agent、OpenHands)。它们能够自主拉取代码、阅读报错、在本地沙盒中不断试错并最终提交Pull Request。在这个过程中,沙盒、测试框架和Git版本控制就是它们的脚手架。
桌面或手机屏幕上的点击操作,正在被转化为可执行的代码脚本(如Playwright脚本或DOM树操作)。智能体通过阅读屏幕的HTML结构或无障碍树(Accessibility Tree)来感知环境,输出Python代码来执行点击和滑动。UI界面变成了被代码操控的世界。
在自动化实验室中,科研流程被整合成了一条无缝衔接的“代码流水线”。从文献检索、提出假设,到编写Python仿真程序、控制真实的液体处理机器人进行化学合成,再到处理实验数据,代码贯穿了科研的每一个环节(如AI Scientist系统)。
智能体能够根据用户的实时反馈,自动编写和修改推荐系统的策略代码,并将用户的偏好沉淀为可被程序读取的持久化状态对象。
在机器人领域,抽象的行动意图被转化为带有运动学参数的可执行控制代码。代码充当了安全边界,确保机器人的动作(如机械臂抓取)符合物理定律,并在进入真实物理世界前在仿真器代码中完成排雷。
尽管前景广阔,研究者也清醒地指出了该领域目前面临的几大核心挑战:
这篇论文为AI领域提供了一张极其清晰且具有历史意义的“智能体系统工程蓝图”。
想要让AI真正走向复杂的真实世界,绝不能仅仅依靠大模型自身算力的提升。必须将“代码”作为系统的骨架、神经和肌肉。 大模型提供了强大的“大脑”,而基于代码构建的智能体脚手架(Agent Harness),则赋予了这颗大脑以稳固的沙盒、真实的物理反馈、可靠的记忆机制以及多角色协同的组织法则。只有深深植根于这套“可执行、可检查、状态化”的代码基底之中,AI智能体才能真正从演示级的玩具,蜕变为工业级的可靠生产力。
文章来自于"AI修猫Prompt",作者 "AI修猫Prompt"。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
