# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大模型开始进入理论计算机科学最核心的问题之一:算法设计。
北大港大团队提出LegoNE框架,结合LLM与自动数学证明系统,在近似纳什均衡ANE领域,首次发现了超越人类已知设计范式的新算法。

1951年John Nash提出纳什均衡,用来描述一种稳定状态:任何玩家单独改变策略,都无法获得更好的收益。
但寻找精确纳什均衡极其困难。目前已知算法在最坏情况下都需要指数级时间。所以通常不得不退而求其次,寻找“近似纳什均衡”。
跟微积分思想类似,离不开ε-δ。笔者当年大一学“数学分析A”时,就常被这两个符号折磨。
如果一个玩家最多只能通过改变策略获得ε的额外收益,那么这个解就称为 ε-近似纳什均衡。ε越小,解越接近真正的纳什均衡。
过去二十年,研究一直在追求一个目标,在多项式时间里,把ε做到尽可能小。
对于双人博弈,研究不断改进算法,ε = 0.75 → 0.5 → 0.3393 → 1/3。
不过从2007年到2022年,整整15年没再有突破。
三人博弈情况更糟。研究几乎都依赖一种扩展的方法,把双人算法逐步推广到多人情形。
这种方法的天然缺陷是,参与者越多,近似误差越大。三人博弈中,最好的结果只能达到:ε = 0.6 + δ。
所以很多人认为,这可能已经接近当前理论框架下的极限。
大模型可以生成大量算法。但算法研究不同于写代码,真正困难的是证明。
一个候选算法仅在几个测试样例上表现良好远远不够,必须对所有可能的博弈实例都成立。
过去没有一个自动系统,可以验证近似纳什均衡算法的最坏情况保证。
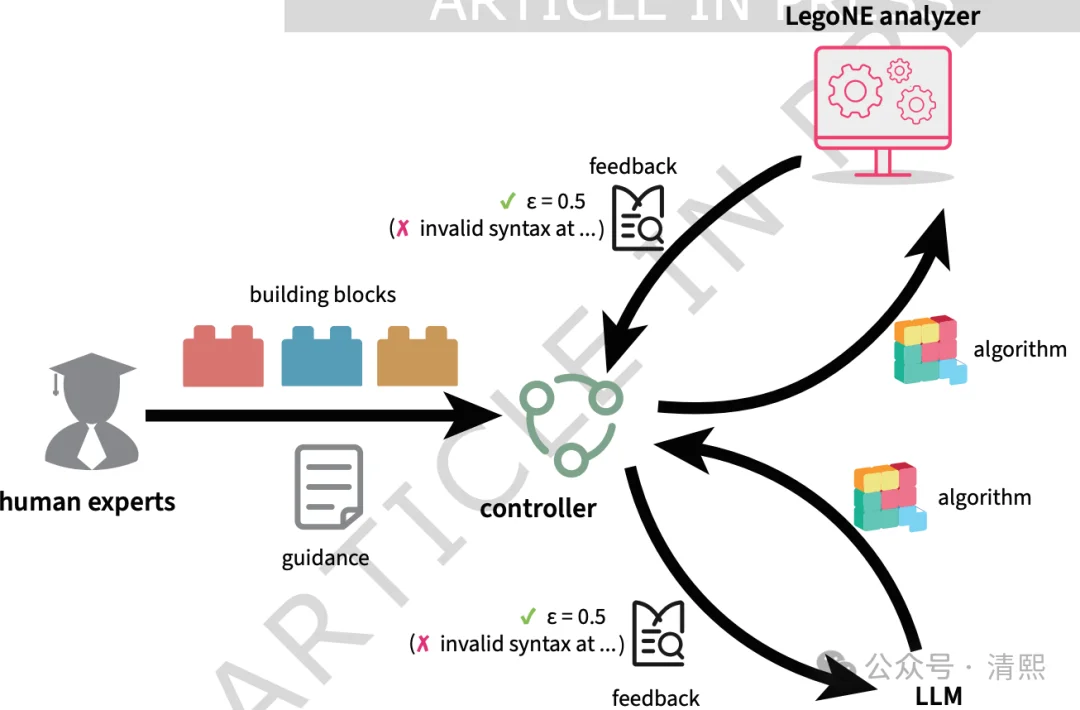
论文提出LegoNE就是为了解决这个问题。
论文把二十多年博弈论研究中的证明技巧抽象成了一组“乐高积木”。
例如BestResponse(最佳响应),EqMix(等概率混合),OptimalMixing(最优混合),StationaryPoint(驻点搜索)等等。
研究通过组合这些积木来构造复杂算法,通过LegoNE自动分析这些组合。核心步骤:
这样,证明问题就变成了一个有限规模优化问题。求出的最优值,就是算法能够保证的最坏情况ε。
计算保证值的过程,同时就是证明过程。
研究首先进行了验证实验:
只给大模型提供2007年前已知的算法模块,仅经过两轮迭代,模型就重新发现了一种双人博弈算法。
虽然结构与文献中的最佳算法不同,理论保证却完全一致 ε = 1/3 + δ。
Back test 相当于让AI在几轮搜索中,重走了人类十五年的研究路径。
三人博弈,LegoNE与DeepSeek-R1组成的系统,在11轮搜索后发现了一种完全不同的结构。
其理论保证达到 ε = 0.5 + δ,相比原纪录 0.6 + δ,显著提升。
这个结果无法通过扩展技术得到。因为扩展技术满足:ϵ₃ = 1/(2−ϵ₂)。要要达到0.5,必须ϵ₂=0,也就是能够求解精确纳什均衡,这个做不到。
论文等于证明了,多人近似纳什均衡存在一条独立于扩展技术的新路线。
很多AI4S科学发现工作,是在已有验证器上搜索答案。
AlphaGeometry 使用成熟几何证明器,FunSearch 在具体实例上测试程序效果,etc。
而这篇论文创新发明了近似纳什均衡验证器,大模型只是负责搜索。
这可能是未来AI与人类协作科研或生产的主要模式:
人类负责定义理论语言和证明规则,AI负责在这个空间中进行组合探索。
创造力来自搜索,可靠性来自验证。
宇宙就是这么使用人类的,细思恐极。
以重整化的视角来看,LegoNE做的事情很有意思。
研究把二十多年积累的证明技巧压缩成少量积木。这些积木类似于经过粗粒化后的有效自由度。
LLM只需在一个由专家知识构成的低维有效理论空间中探索,无需在指数级组合空间中盲目搜索。
LegoNE相当于一个RG流验证器,不断评估候选结构在最坏情况下的稳定性。
这或许预示了一种新的研究范式:
把领域知识转化为可计算的形式语言,再让大模型在这个语言空间中进行组合创新。
未来能类似处理的,不仅是博弈论,可能还包括近似算法、组合优化、数学证明,以至理论物理中的许多问题。
数学变成跟物理一样的“某实验学科”。
文献1,Discovering expert-level Nash equilibrium algorithms with large language models,https://www.nature.com/articles/s41467-026-74003-1
文章来自于"清熙",作者 "王庆法"。



