# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

AI 的能力边界正在不断被刷新。从数学推理到代码生成,再到数字化白领,语言模型和语言智能体在诸多基准测试中已展现出超越人类专家的表现。一个看似顺理成章的判断早已成为共识:语言模型已经具备了扎实的语言理解和语义推理能力。然而,ACL 2026 Oral 的一项研究工作从一个更基础的层面重新审视了这个问题:语言模型真的理解(短语)语义吗?
问题的起点,是一类经典的语言现象。「Kick the Bucket」不是「踢桶」,「Rocket Science」并非「火箭科学」,「Alarm Clock Rings」也远不止字面意义上的「闹铃」。这类多词表达(Multiword Expressions,简称为 MWE)在自然语言中无处不在,它们的含义往往无法从各个组成词语中直接推导,需要结合语境、惯例乃至世界知识才能准确理解。长期以来,这被视为自然语言处理的经典难题,如鲠在喉(A Pain in the Neck for NLP)[1] 。
时至今日,这道难题依旧摆在了前沿模型面前。
来自北京通用人工智能研究院与北京科技大学的研究者提出了一个分析框架 SemanticQA,系统评估了模型在短语语义理解上的真实水平。
不同于以往孤立考察单一任务的做法,SemanticQA 将语义理解拆解为三种原子操作:分类(Categorization)、抽取(Extraction)与 释义(Interpretation),并在此基础上覆盖了四类典型短语现象:惯用表达、固定搭配、复合名词与动词多词表达,形成了一个结构严谨、覆盖广泛的诊断性测试基准。
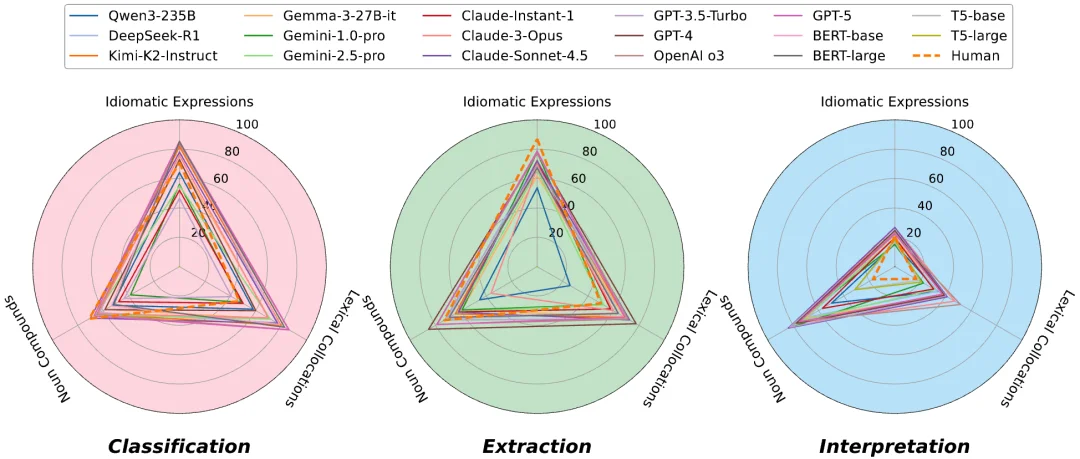
评估对象横跨十余个模型,从 BERT 和 T5 等经典架构模型,到 GPT-5、Claude Sonnet、DeepSeek-R1 和 Gemini 2.5 Pro 等近期前沿模型,几乎涵盖了主流的开源与闭源系统。
反直觉的结论:即便是最先进的大模型,在处理短语层面的语义时仍存在系统性缺陷。没有任何一个模型能够在所有任务上保持稳定的高水准表现,不同操作类型之间的性能落差显著:模型或许能够流畅地解释一个惯用语,却在精确抽取相同表达时屡屡失手;分类任务随着语义类别数量的增加急剧退化,而在需要多步骤串联的组合任务中,上游的抽取错误更会如滚雪球般放大下游的解释偏差。更值得警惕的是,那些在语义相似度指标(如 BERTScore)下表现亮眼的模型,未必真正掌握了结构性的语义推理能力。高分背后,可能只是对示例模式的精巧模仿。
这些发现提醒我们:在为语言模型的惊人能力欢呼之前,或许值得在更基础的地方多停留片刻。短语,是语言理解扎根的地方。
当前主流的推理评测基准大多聚焦于数学求解、代码生成与逻辑推断。它们考察的是模型在显式符号规则下的运算能力,却鲜少触及语言最基本的构成单元 —— 短语 [2][10]。事实上,大量日常表达的含义并非来自词语的简单叠加,而是涌现于词汇之间的约定俗成、语境线索与世界知识的交织之中。现有评测的盲区,恰恰就藏在这里。
与现有基准不同,SemanticQA 没有简单堆砌任务规模,而是先做了一步简洁的抽象:将「短语语义理解」拆解为三个可操作的基本能力环节:
这三步分别对应结构识别、语义判断和生成表达,共同构成对短语语义的完整检验。它们的输出形式各异,抽取要求精准的字面匹配,分类依赖有限选项内的判断,释义则是开放式的语言生成 —— 这种结构差异本身,也成为诊断模型能力边界的有效手段。
其核心设计思想是「操作对齐」(Operation-Aligned):同一个短语实例在不同任务中被统一建模,采用固定的提示模板加以呈现,从而有效压制提示诱导带来的噪声,使不同模型之间的横向比较更加公平可靠。这一设计也直接回应了传统评测中长期存在的混淆:任务表现不等于能力水平,一个模型或许凭借格式敏感性在释义任务中得高分,却在抽取同一短语时茫然失措。
换句话说,如果模型真的理解了某个短语,它应当在这三类任务上表现出稳定的跨操作一致性,而非只在某一类上擅长。正是这种一致性,才是 SemanticQA 所定义的(短语)语义推理能力。
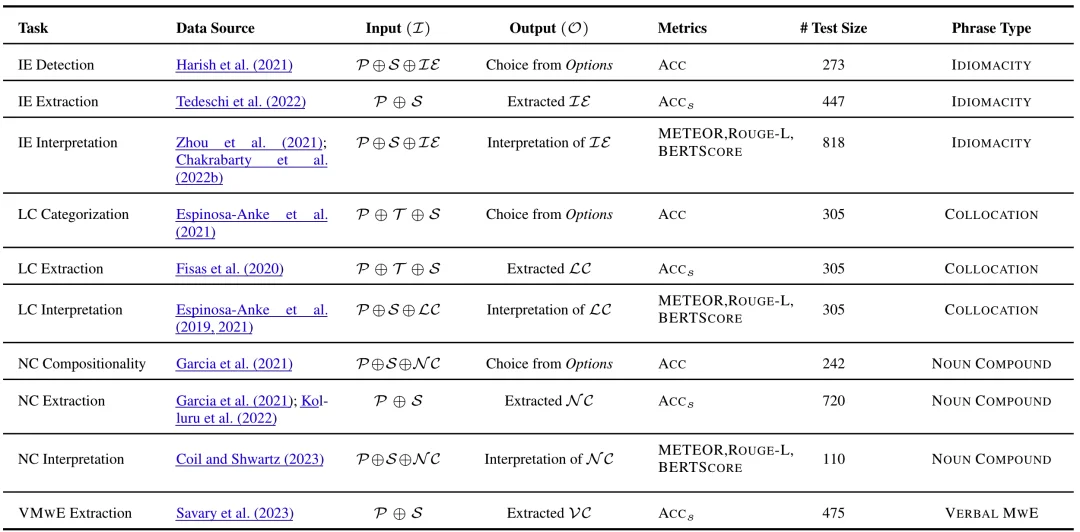
在数据层面,SemanticQA 涵盖了四类最典型、也最让语言处理系统头疼的短语现象:习语(Idiomatic Expressions)、固定搭配(Lexical Collocations)、名词复合结构(Noun Compounds)和动词多词表达(Verbal MWEs)[3][8]。这些表达广泛存在于自然语言中,且其含义往往无法通过简单的词义组合规则推导,正是检验模型「真理解」还是「假套路」的试金石 [4][5]。
SemanticQA 基于现有多个语义标注资源构建,这些资源在标注协议、难度分布及语义粒度上存在显著差异。该基准汇总了各任务来源的数据集、输入输出结构、测试样本数量及所涵盖的短语类型,从而展现了其规模与多样性:上千条的测试样本,覆盖检测、抽取与释义三类语义任务,且每个任务均采用统一的提示模板、句子上下文及输出格式。这种标准化却非同质化的设计旨在反映真实语义标注场景中固有的自然变异性,而非强行要求不同来源之间保持难度或标注一致性。因此,SemanticQA 适于展现这种异质性,但不适用于对短语类型进行绝对化的横向比较。
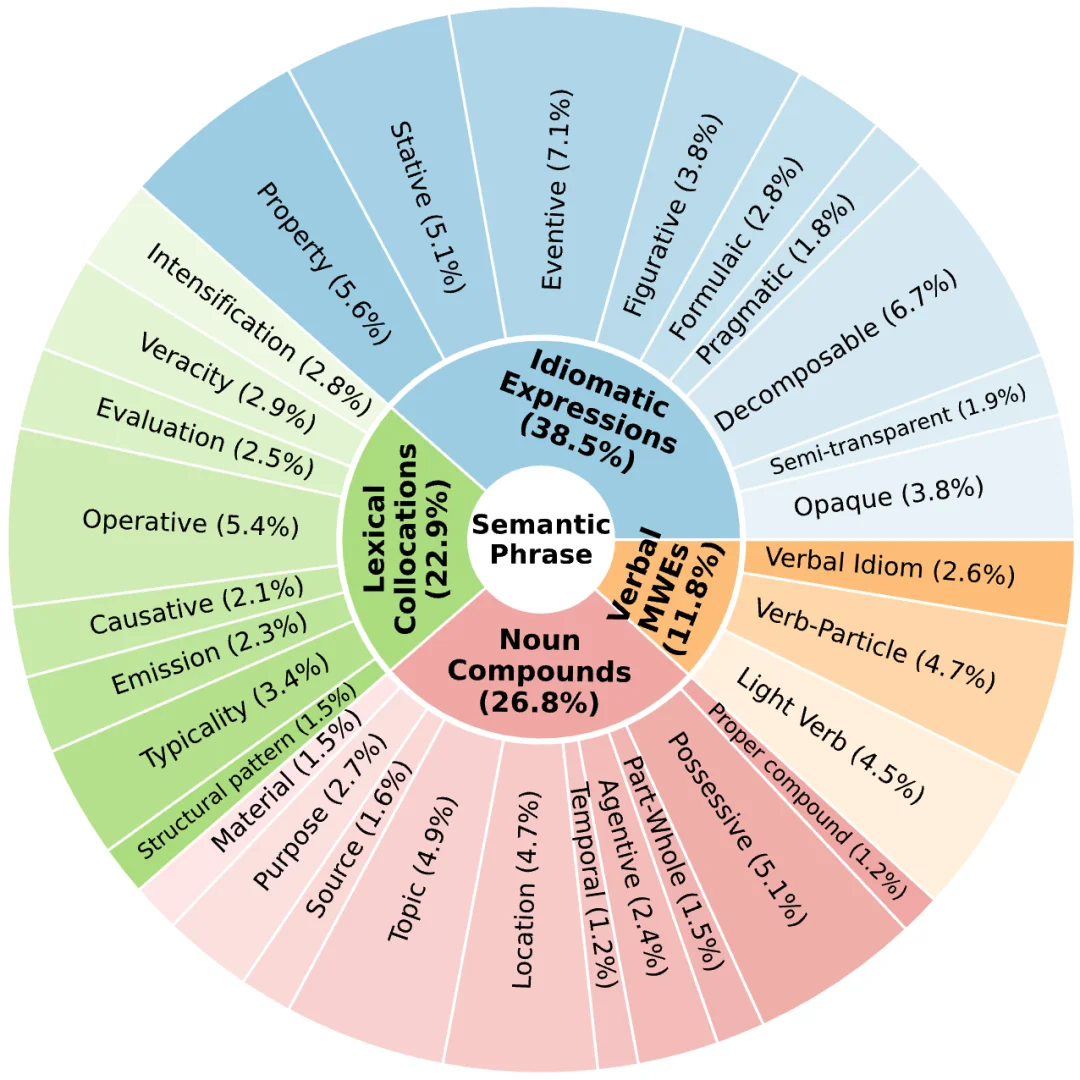
短语现象具有高度多样性,不同文献中使用的术语亦不统一。为保障基准的可复现性,SemanticQA 通过显式列出细粒度的子类别,避免将短语简单二分为「习语 vs. 非习语」的粗放式分类,从而支持研究者深入分析模型在特定语义子类上的性能表现。例如,模型可能对非组合习语完全失效,却在可分解习语上表现良好,这一差异有助于揭示模型究竟是依赖局部词义线索,还是基于整体的短语模式进行语义判断 [6][7]。
SemanticQA 不只看模型会不会做,而是看它在抽取、分类和释义三种不同约束下是否一致。
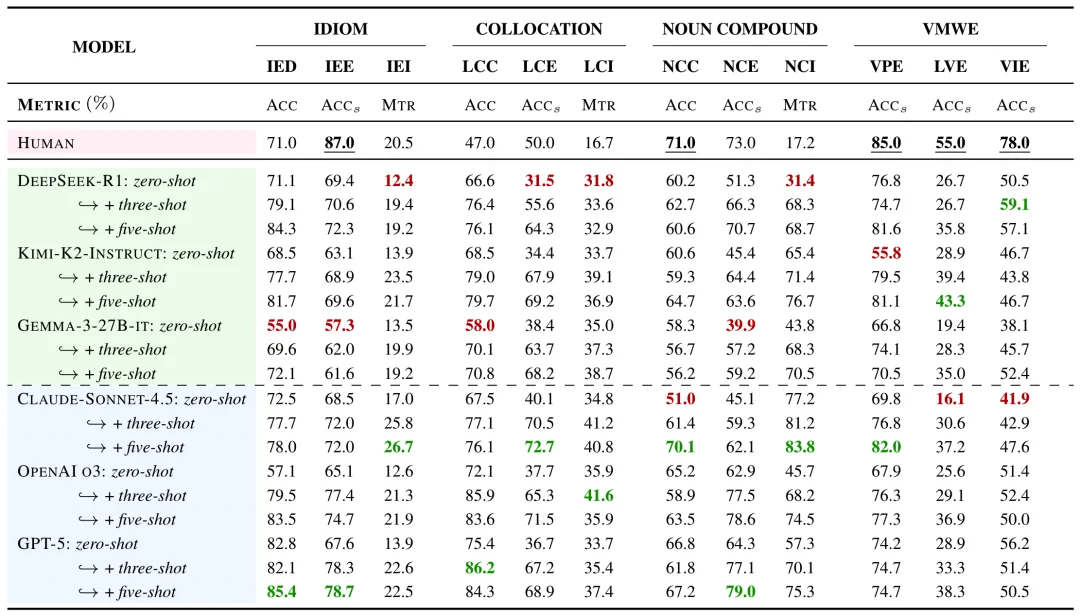
研究发现,即便是当前的前沿模型,在这三项核心能力上也远未均衡发展:
以 GPT-5 为例:在习语分类(IED)五样本提示(5-Shot)设定下达到 85.4% 的分类准确率,但对应的习语抽取(IEE)仅为 78.7% 的精确匹配率,而习语释义(IEI)则只有 22.5% 的表面相似度(Meteor)。 这种落差意味着:模型可以「猜对类别」,甚至「生成合理的解释」,但并不具备跨任务一致的语义表示。
更典型的是抽取任务。研究指出,抽取是最能暴露模型是否能看到「短语边界」的操作。多个模型在释义任务上取得较高的语义相似度(BERTScore),却在严格按照精确匹配的抽取任务中明显失效。例如:GPT-5 在名词复合词释义(NCI)中的语义相似度(BERTScore)可达到 96.8%,但同一模型在对应的 NCE 上的抽取准确率仅 79.0%。这说明当前模型更擅长生成语义上相似的话语,但无法以同样的熟练度实现稳定的短语抽取。
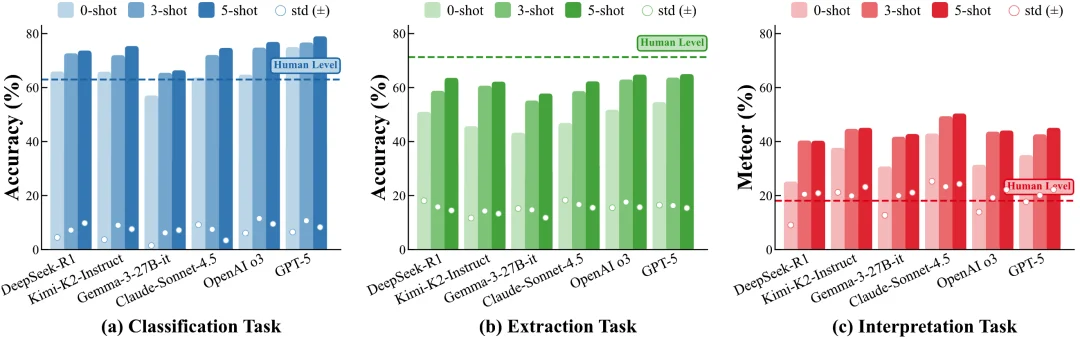
三项任务之间的不一致,正是语义理解能力欠缺的直接证据。一个真正理解短语语义的模型,应当在结构化输出(抽取)、离散决策(分类)和自由生成(释义)上保持行为兼容,而非只在某一种任务上取巧。
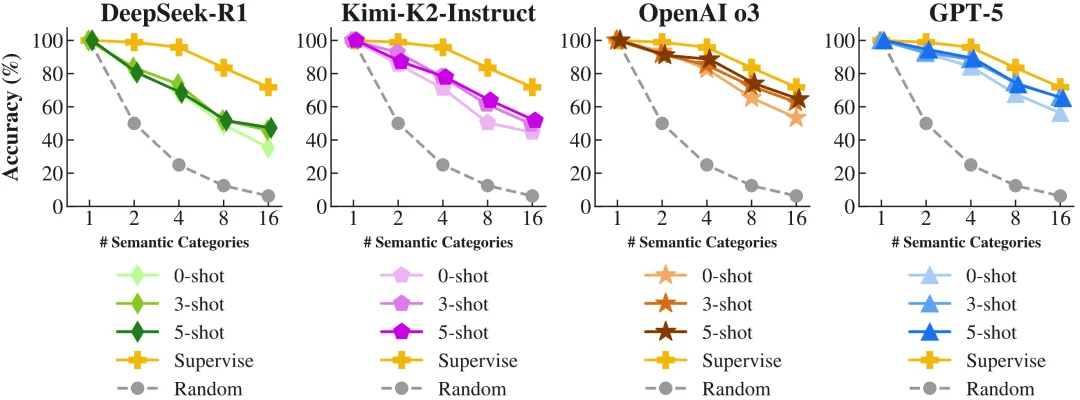
现实世界中的语义关系呈现出丰富且细粒度的特性,然而现有大多数基准仅测试粗粒度的语义分类(例如 2 至 4 个类别)。为考察模型是否具备真正的语义归纳能力,即:随着类别数增加,任务表现能否保持稳定,抑或出现急剧退化,相关实验结果极具启发性:前沿语言模型擅长在粗粒度、高频的语义区分任务上表现出较高的表面准确率,但一旦需要精细区分十多个细粒度语义类别,其归纳能力显著不足。特别指出:DeepSeek-R1 的分类准确率从 81.7% 下降到 35.4%,跌幅达到 46.3 个百分点;GPT-5 虽然更稳定,但在 16 分类的条件下仍明显退化。这一现象表明,现有模型更多依赖表层的统计共现信息,而非具备真正的语义推理能力 [9]。
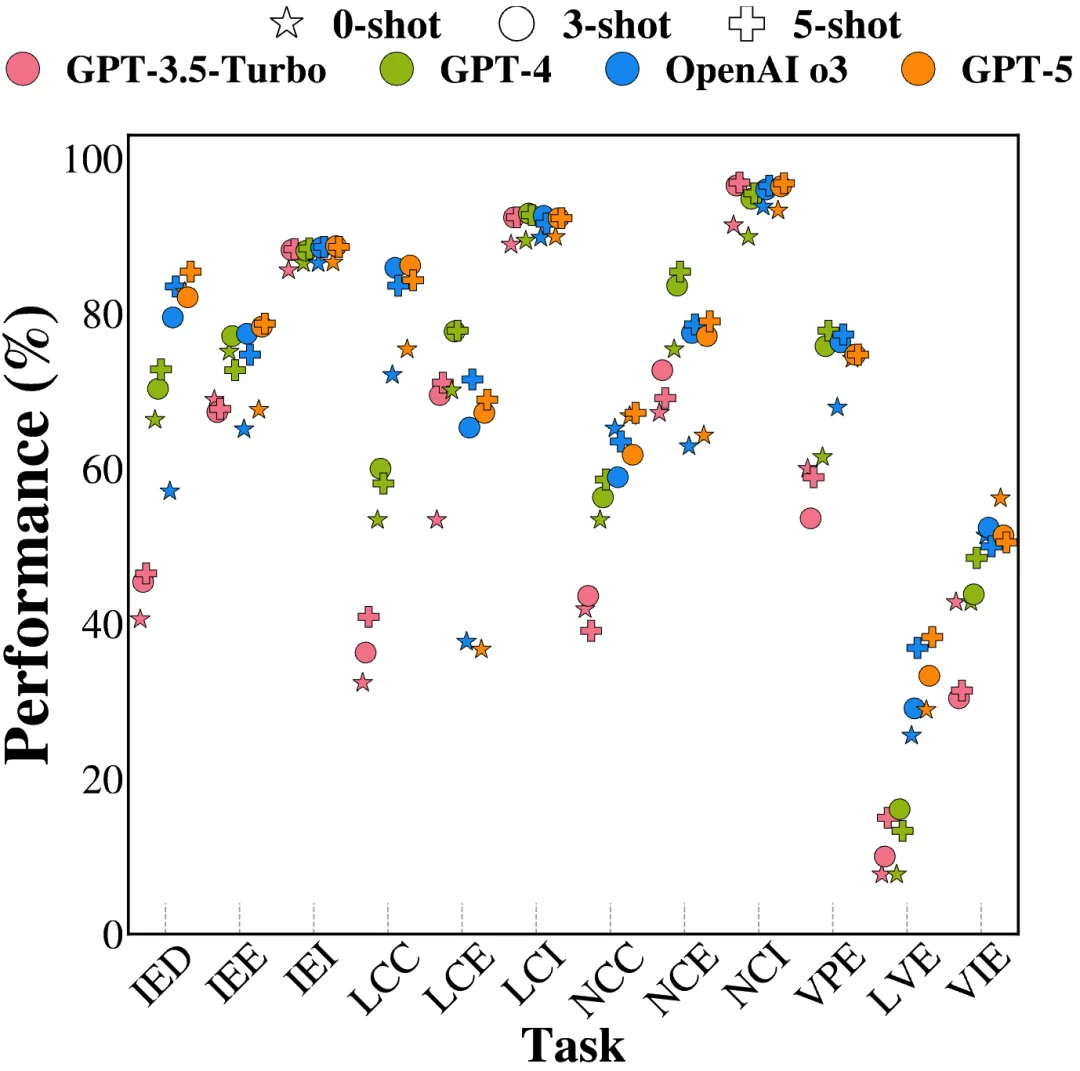
由于本工作的研究跨度较长,我们还特地对 OpenAI 的四款代表性模型(GPT-3.5-Turbo、GPT-4、o3 和 GPT-5)进行了跨越三年的历时分析。结果显示,多数任务表现出了显著的偏序和排名一致性,例如在 LCI、NCI 和 IEI 等任务中,模型性能随代际更迭呈现出稳步递增的趋势(GPT-5 ≥ o3 > GPT-4 > GPT-3.5-Turbo),且 Few-Shot 提示普遍优于 Zero-Shot。
现实应用中的语义处理往往是多步流程,例如先抽取短语,再对其进行释义或分类。SemanticQA 专门设计了组合推理任务来模拟这一场景。结果显示:

组合推理实验进一步揭示了「上游一步错,下游步步错」的问题。在「先抽取 + 后释义」的顺序任务中:GPT-5 在词汇搭配的组合任务中,5-Shot 条件下抽取准确率为 41.3%, 条件释义(即抽对后再解释)的 Meteor 相似度可达到 41.8%, 但整体的 Meteor 相似度最终仅为 17.3%。
这些结果揭示了一个被原子任务评测长期掩盖的事实:语言模型在单点任务上也许能产生高光表现,但同时也很容易在多步的级联任务中土崩瓦解。语义推理,必须经得起流程化检验。
SemanticQA 的设计思路给当前的语言模型评估带来五点重要启示:
本工作完稿于 2023 年,并于 2025 年进行修订和投稿录用。该诊断性评测基于单轮静态设计,在当时是合理的,但放到 2026 年的 Agent 语境下,它测的东西已经不够用了。Agent 不再是单轮推理,而是在长时运行:一步走偏,后面全部走偏,工具调用失败或推理错误被带入下一步、链路越长偏差越大导致掉入前缀陷阱,如蝴蝶效应般不可逆地叠加。因此,如何针对语言智能体进行动态自适应的评估,成为了当今更有价值的科学与实践问题。
静态 Evals 在 Agent 时代的根本性失效问题:
语义推理不是黑盒系统里的灵光一现,而是可分解、可检验以及可追溯的系统能力。SemanticQA 通过操作对齐的设计,将(短语)语义理解这一古早难题重新带回研究前沿,并给出了一个清醒的判断:语言模型远未真正「懂语言」,至少在短语层面,它们有了很大的改进,但仍在摸索前行。 这项工作的意义不仅在于指出不足,更在于提供了一套可操作、可复现的诊断工具,帮助社区朝着更稳健、更结构化的短语处理前沿迈进。
参考文献
[1] Shwartz and Dagan. Still a Pain in the Neck: Evaluating Text Representations on Lexical Composition. TACL 2019.
[2] Wei et al. Chain of Thought Prompting Elicits Reasoning in Large Language Models. NeurIPS 2022.
[3] Constant et al. Multiword Expression Processing: A Survey. Computational Linguistics 2017.
[4] Coil and Shwartz. From Chocolate Bunny to Chocolate Crocodile: Do Language Models Understand Noun Compounds? ACL Findings 2023.
[5] Espinosa-Anke et al. Evaluating Language Models for the Retrieval and Categorization of Lexical Collocations. EACL 2021.
[6] Chakrabarty et al. It’s Not Rocket Science: Interpreting Figurative Language in Narratives. TACL 2022.
[7] Pham et al. PiC: A Phrase-in-Context Dataset for Phrase Understanding and Semantic Search. EACL 2023.
[8] Ramisch et al. A Survey of MWE Identification Experiments: The Devil is in the Details. MWE Workshop 2023.
[9] Miletic and Schulte im Walde. Semantics of Multiword Expressions in Transformer-based Models: A Survey. TACL 2024.
[10] Zeng and Bhat. Getting BART to Ride the Idiomatic Train: Learning to Represent Idiomatic Expressions. TACL 2022.
文章来自于"机器之心",作者 "刘洋和李鸿铭"。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
