# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
当视频生成模型走出娱乐创作的舒适区,进入科学、医疗、教育等知识密集场景,它们是否还能生成事实准确、清晰可用的视频?

任务对比 —— 传统视觉质量导向 vs KIVI 知识密集型导向
针对这一挑战,研究者首次定义了 「知识密集型视频生成」(KIVI)新任务 —— 要求模型从简短提示词出发,生成事实准确、用户能照着做的视频。团队配套构建了 1080 条提示词的 KIVI-Bench 评测集,提出 FactP 与 HelpS 两个自动指标,并在 7 款主流模型上揭示了实体误描、操作错误、组件错位三类系统性短板。

过去两年,从 Sora 到 Seedance,视频生成模型在画面质量、运动流畅度和时空一致性等方面取得了显著进展。然而,现有研究与评测仍主要围绕「视频是否好看」展开,较少关注生成内容是否事实准确、过程是否合理、信息是否真正有用。
随着视频生成技术逐渐走出娱乐创作场景,它正在进入医疗、教育、科学传播、操作指导等知识密集领域。在这些场景中,用户关心的不只是画面是否逼真,而是模型能否准确表达知识、清晰展示过程,并帮助用户理解或完成具体任务。也就是说,视频生成模型面临的核心问题正在发生变化:从「能否生成自然流畅的视频」,转向「能否生成知识可靠且有实际价值的视频」。
这种变化也暴露出现有视频生成范式与真实用户需求之间的错位。比如,当用户搜索「如何更换汽车轮胎」时,他们期待的不是一段视觉效果华丽但步骤含糊的视频,也不是先由自己写出完整分镜脚本,再交给模型逐段生成,更合理的方式应该是,模型能够直接理解用户意图,并生成一段步骤正确、过程清晰、可操作的视频。因此,我们提出 KIVI,将视频生成的评测目标从视觉质量导向,推进到知识可靠性与用户实用性导向。
18 个类别涵盖汽车维护、健康医疗、电子设备等,经 LLM 扩充与人工去重后保留 1080 条提示词。
提示词的构造遵循五个标准。视频优越性:比文字更直观(如空间操作、界面导航);事实正确且可核验:提示词事实正确,实体有公开文档可核验;专有名词有知识挑战性:使用具体产品实名(如 Bosticht 卷笔刀),而非泛指实体;超越常识:需要真正掌握特定知识(如 Omron BP5450 血压计的操作步骤),不能仅凭日常经验作答。贴近真实:表述简短自然,符合用户实际提问方式。
传统视觉指标(Imaging Quality, Motion Smoothness 等)与人类对内容准确性和帮助性的判断几乎无关,为此,KIVI 设计了两个互补的自动评估标准:
FactP(事实精度)回答「说没说对」。它的思路是先抽取、再验证 ——LLM 从视频中提取原子化声明,逐条判定正误,按正确比例计分。
HelpS(帮助性评分)回答「能不能照着做」。LLM 从相关性、完整性、清晰度三个维度打分,核心追问:用户能否仅凭这段视频完成所提任务?两者互补,形成完整评价体系。
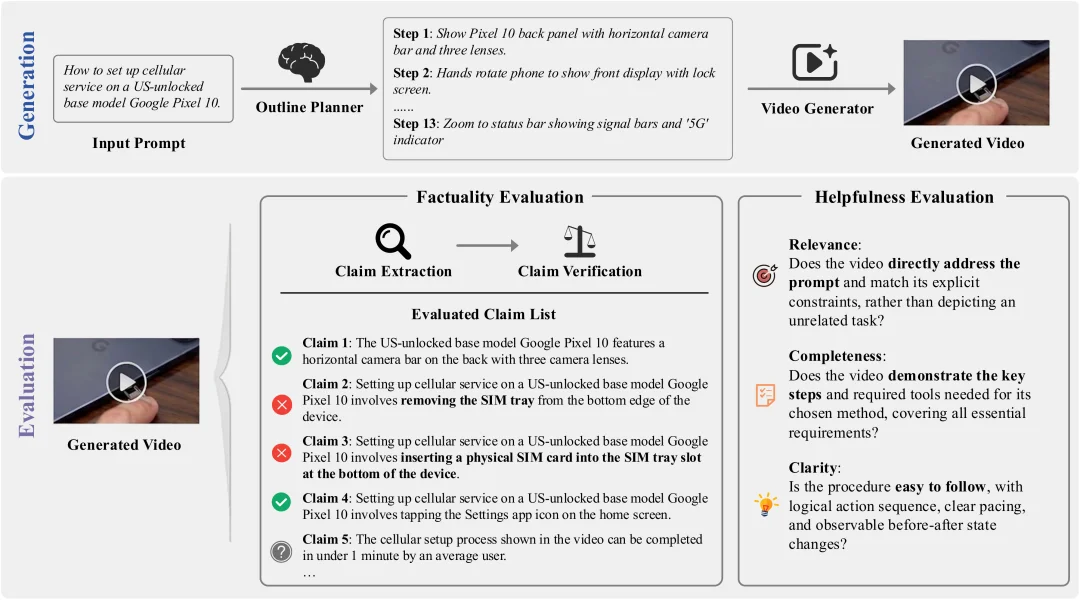
KIVI 多阶段评测管线
团队评测了 7 款主流系统,涵盖闭源 API(Seedance 2.0、HappyHorse 1.0)、开源短视频生成模型(Wan 2.2、HunyuanVideo 1.5)和开源长视频模型(Helios-Base、LongCat-Video、LongLive 1.0)。
人工制作视频的 FactP 和 HelpS 分别达到 97.8% 和 81.9%,远超当前视频生成模型。在模型结果中,闭源短视频模型 HappyHorse 1.0 获得最高 FactP(83.2%),Seedance 2.0 获得最高 HelpS(66.6%)。最佳开源短视频模型 Wan 2.2 的 FactP 和 HelpS 分别为 73.1% 和 48.4%,与闭源模型仍存在明显差距。总体来看,短视频生成模型虽然尚未达到人工制作水平,但在事实准确性和帮助性上均显著优于长视频生成模型。
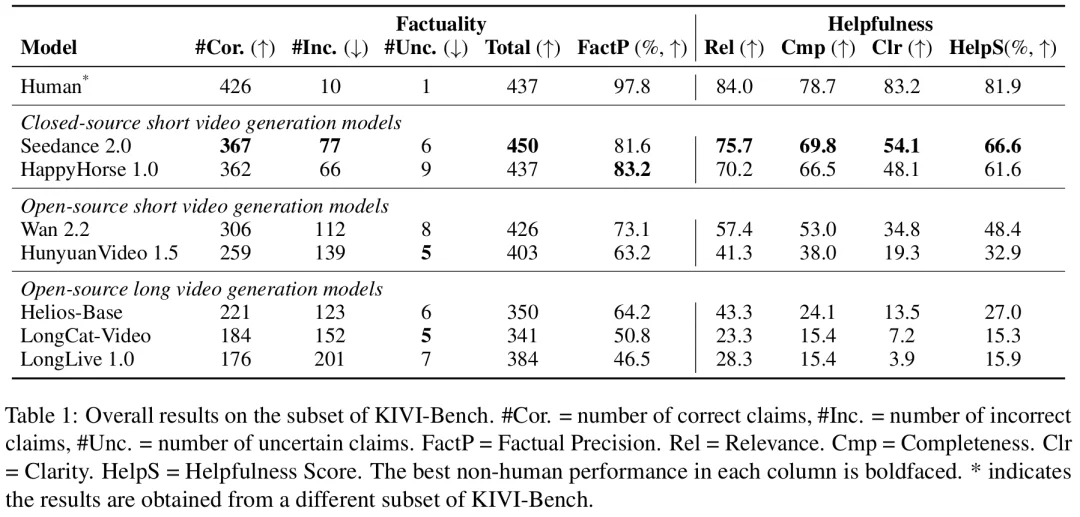
KIVI-Bench 评测结果(基于 54 条均匀采样子集)
人类评估:在 108 组两两对比中,FactP 与人工事实判断一致性达 70.8%,显著优于现有的视频质量自动评估标准 VBench-Long 最优维度(56.5%),HelpS 与人工帮助性判断一致性达 69.0%。而传统指标如 Imaging Quality(38.9%)几乎与人类判断无关。
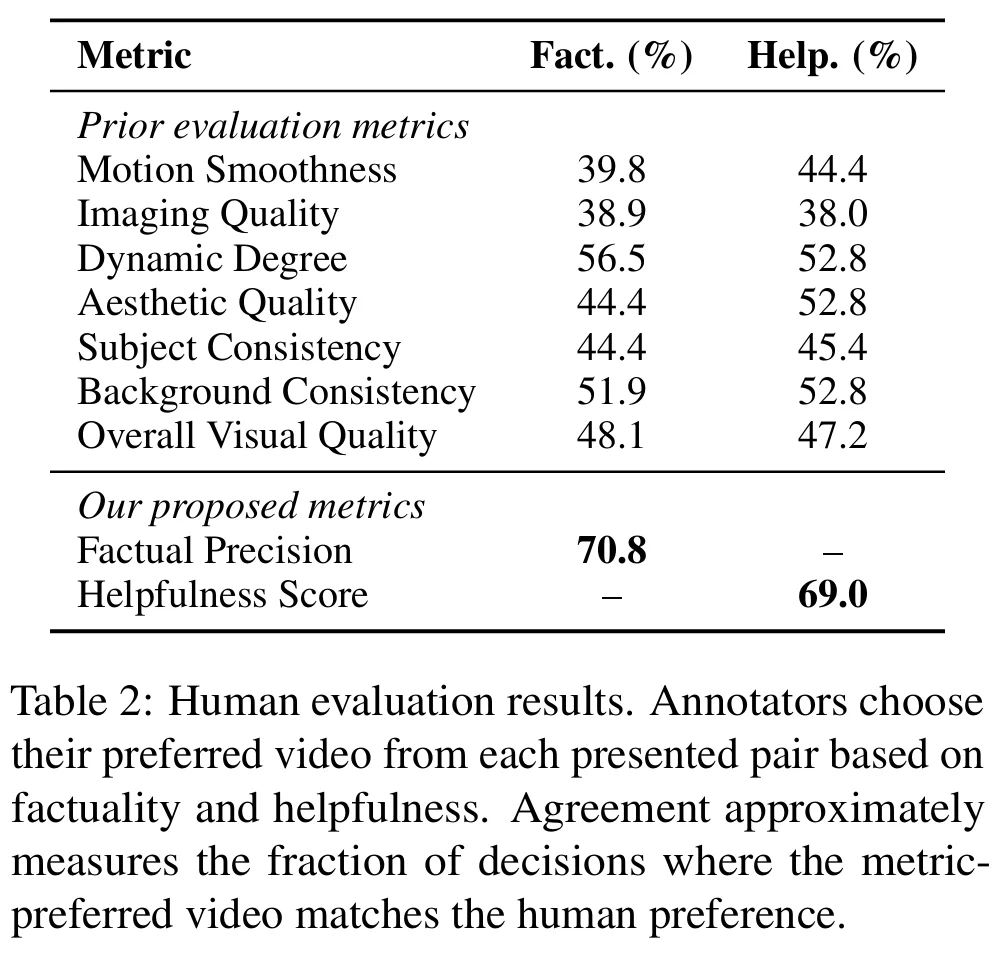
人类评估结果
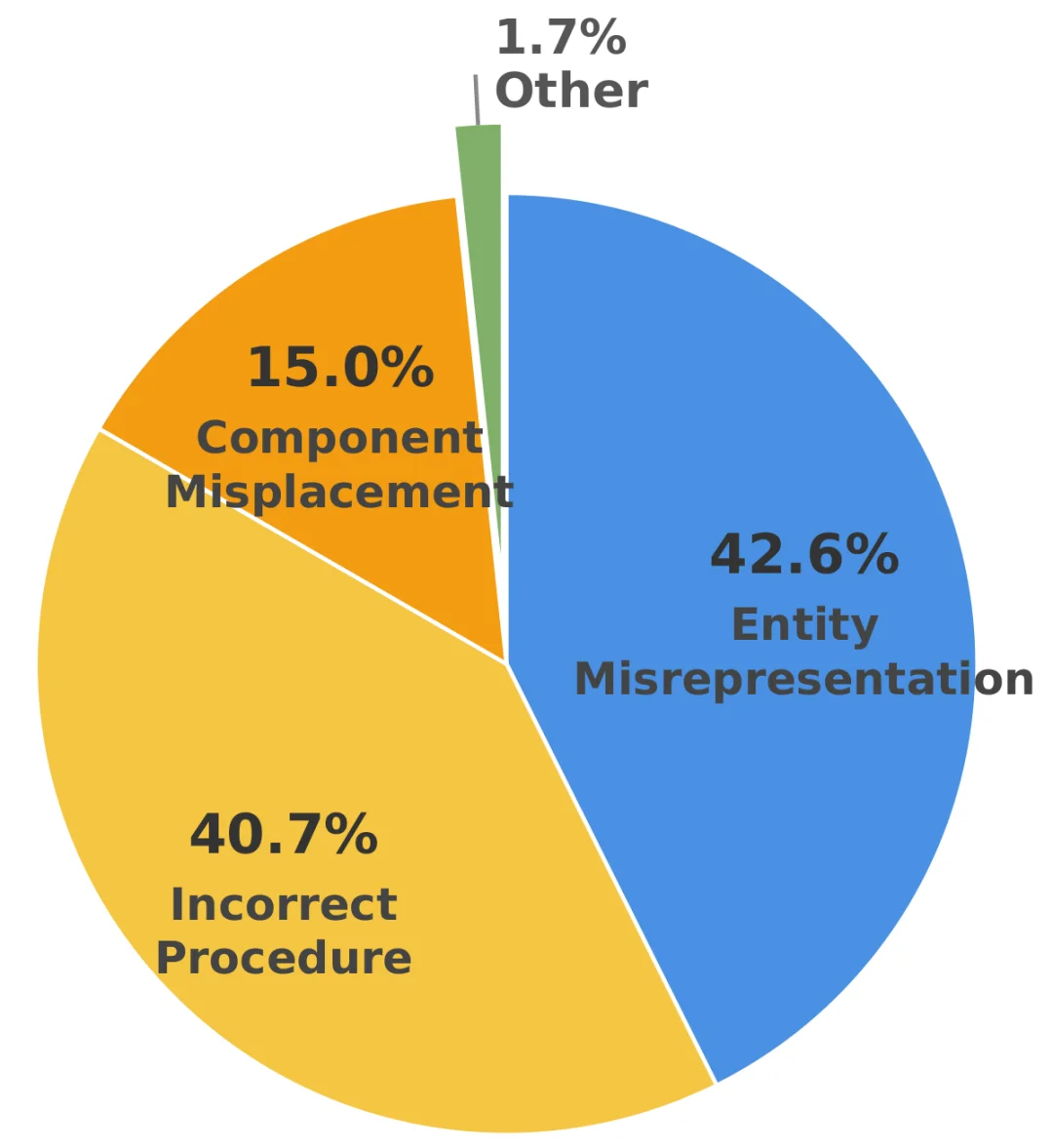
错误类型占比
对 870 条错误声明的分类揭示三类短板:
实体误描占比最高,达 42.6%。模型经常 "发明" 不存在的外观特征,涉及特定产品型号时幻觉率急剧攀升 —— 比如将 Bostitch 电动卷笔刀画成了盒状插孔,而真机是弧形机身。
操作错误紧随其后,占 40.7%,这类错误更隐蔽:外观画对了,步骤却错了。模型能还原 BP5450 血压计的外形,却把袖带绑在了前臂,而这台设备专为上臂设计,暴露了程序性知识的系统性缺失。
组件错位占比 15.0%,虽然比例最低,但机油和漏斗出现在中央扶手箱而非发动机舱这类错误,同样意味着视频对用户毫无帮助。

三类主要事实性错误示例
KIVI 系统定义了视频生成中一个长期被忽视的任务方向:视频不应只服务于娱乐创作,也应能够在知识密集场景 中准确传达信息、清晰展示过程,并真正帮助用户理解或完成任务。
当目标从「还原画面描述」转向「传达可靠知识」,视频生成的评测标准也需要随之改变。传统评测中表现最好的模型,未必能够在事实性、过程合理性和实用性上保持优势;而从简短文本需求直接生成知识型视觉内容,也对模型的理解、规划和生成能力提出了更高要求。
因此,KIVI 不只是一个新的基准,更是在重新定义视频生成的下一阶段目标:从「画面是否自然」走向「内容是否可靠」,从「娱乐创作工具」走向「知识获取媒介」。这也指向了视频生成从像素空间走向实用空间的下一个前沿方向。
文章来自于"机器之心",作者 "机器之心"。



【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
