1080条提示词、7款模型大比拼:视频生成离「好看、好用又准确」还差多少?
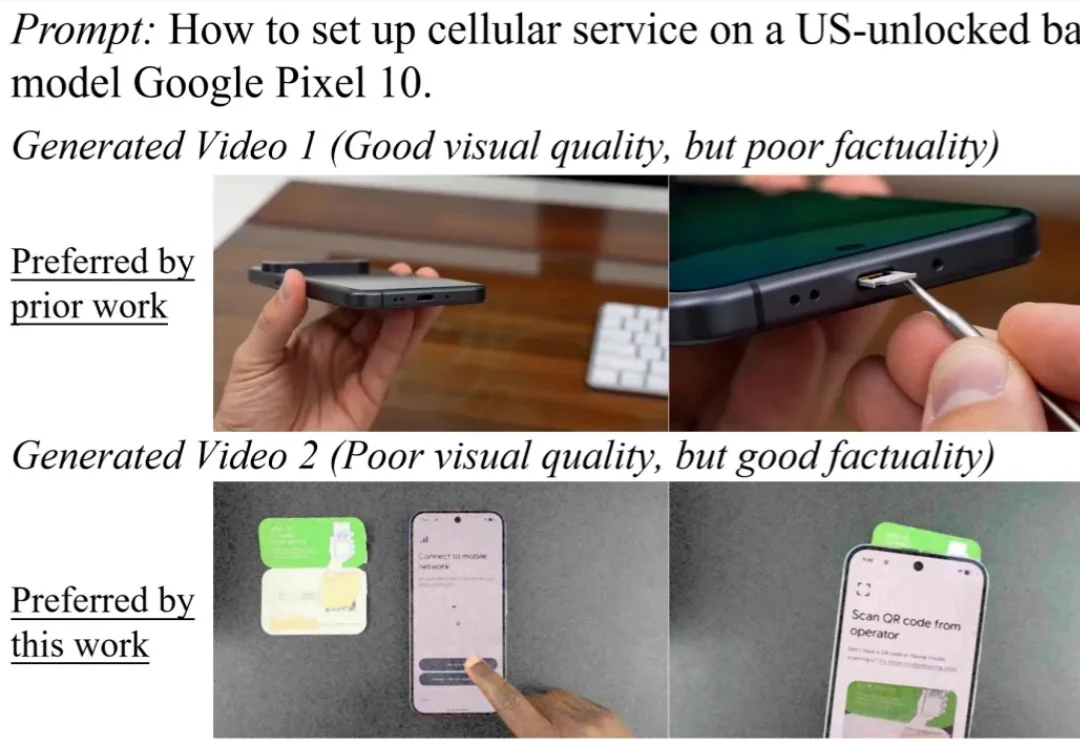
1080条提示词、7款模型大比拼:视频生成离「好看、好用又准确」还差多少?当视频生成模型走出娱乐创作的舒适区,进入科学、医疗、教育等知识密集场景,它们是否还能生成事实准确、清晰可用的视频?
来自主题: AI技术研报
9392 点击 2026-06-16 09:53
 搜索
搜索
当视频生成模型走出娱乐创作的舒适区,进入科学、医疗、教育等知识密集场景,它们是否还能生成事实准确、清晰可用的视频?

作者测试了智谱GLM-4.5V(开启/关闭推理)、豆包、Kimi、元宝和ChatGPT-5在识别十张奇葩卫生间标识上的表现。评测模拟紧急如厕场景,按识别正确性评分。结果智谱普通模式得分最高(86分),ChatGPT-5和智谱推理模式次之(78分),豆包和元宝70分,Kimi垫底(38分),揭示了各AI视觉能力的差异及局限性。