# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大语言模型的RL技术已日趋成熟,多模态生成模型的强化学习训练却仍在“各自为战”——图像扩散模型一套流程、视频生成另一套标准、VLM和LLM又有不同的技术栈。
这种技术栈的碎片化严重制约了AIGC模型的能力上限。
针对这个问题,腾讯混元庞天宇团队正式开源UniRL:一个面向统一多模态生成的分布式RL后训练框架。
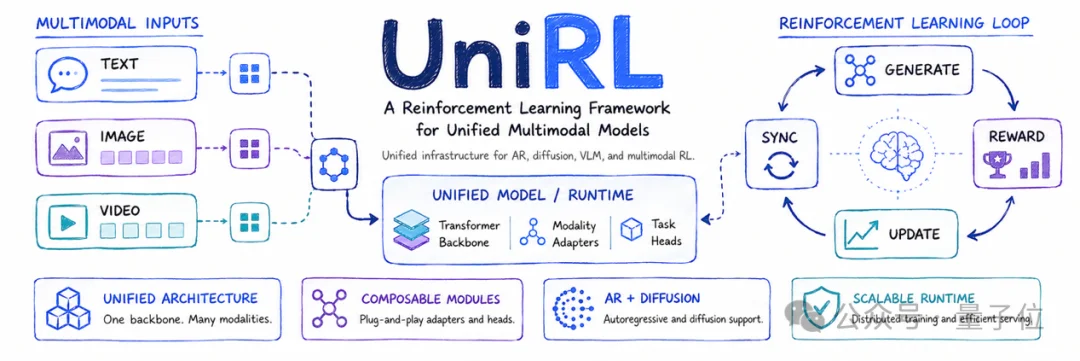
该框架首次将扩散模型、自回归模型与生成理解统一模型的强化学习训练纳入同一套完整流程,为多模态模型强化学习迭代铺平了道路。
近年来,AIGC领域取得了巨大的发展,从Stable Diffusion到FLUX,从Wan到HunyuanVideo,生成模型的能力边界不断拓展。
然而,在模型能力快速迭代的背后,AIGC强化学习训练基础设施的缺失却成为了整个行业的痛点。与LLM的RL训练相比,多模态生成RL面临着四大难以逾越的技术挑战:
这些挑战导致了行业内“一个模型一套训练代码”的现状,开发者则不得不花费大量时间在重复的工程实现上,而无法专注于算法创新和模型效果提升。
针对上述行业痛点,腾讯混元团队打造了UniRL:一个面向多模态生成模型的通用RL后训练框架。
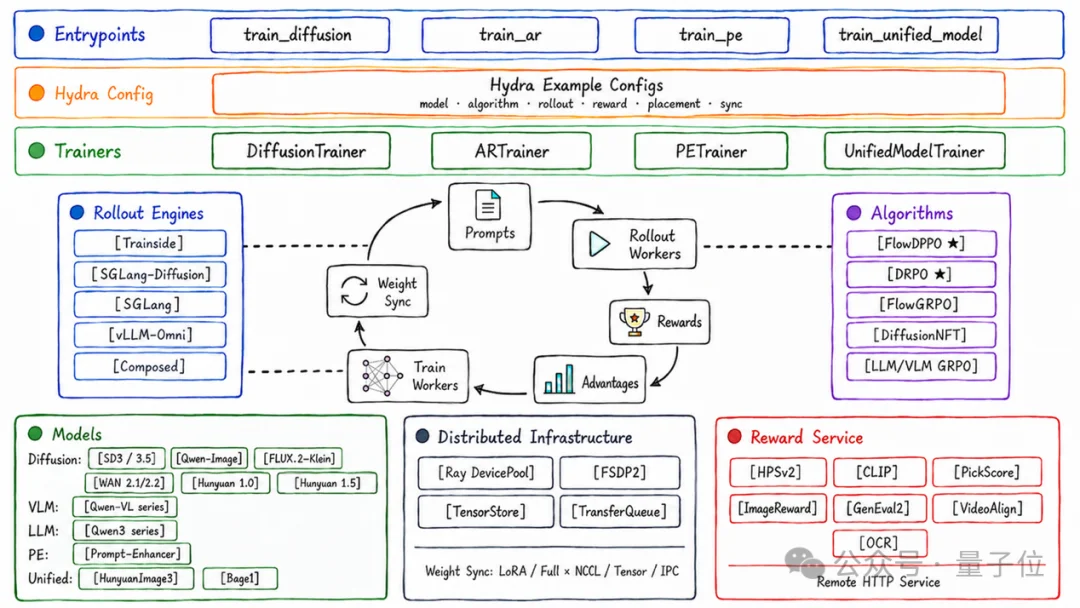
UniRL不绑定单一模型族、单一算法或单一训练栈,而是以Ray worker group、Hydra flat recipe、可组合训练后端和可插拔rollout engine为核心骨架,抽象出一套多模态RL闭环契约:rollout → reward → advantage → train → weight-sync。
借助这套抽象和类型化rollout数据模型,UniRL可覆盖diffusion / flow、LLM / VLM、prompt-enhancement以及unified model四类训练场景。
不同domain可以保留各自的训练逻辑,同时复用统一的调度、数据传输、reward、advantage和权重同步边界。
对开发者来说,UniRL在解决什么?
UniRL的目标不是提供又一个算法库,而是把多模态RL训练中所有重复、易错、极难复用的系统工程问题全部沉到框架底层。
让开发者不必反复重写rollout、reward、轨迹传输和训练对齐逻辑,而是把更多精力放回模型、reward和算法本身。
在diffusion / video RL中,rollout和trainer之间传递的不再只是轻量token,而是高维latent轨迹、时间步、条件状态和log-prob replay所需信息。
UniRL将这些中间状态的存储、传输和显存控制纳入框架设计,避免大张量汇聚到driver,并结合分批forward、稀疏轨迹、offload、sleep / wake等机制降低峰值压力。
UniRL用轨迹 (track) 表示承载不同阶段的生成轨迹:AR阶段是TextSegment,图像生成阶段则是LatentSegment,不同track之间通过parent-child关系连接。
这使得Bagel、HunyuanImage 3.0这类统一多模态模型,先AR文本思考、再DiT图像生成的链式流程可以被自然表示,并为后续的reward回传、advantage计算和分track训练提供统一的数据基础。
UniRL提供了业界最广泛的模型支持,几乎涵盖了当前所有主流的多模态生成模型:
除了统一训练框架,UniRL也内置了多类多模态AIGC RL算法和奖励组件,方便研究者与开发者快速启动实验,并在同一套接口下比较不同算法与模型配置。
在算法侧,UniRL支持多种典型RL后训练路线:
在奖励侧,UniRL集成了多类常用reward与judge组件,覆盖图像、视频和文本相关的多模态评估需求:
这些算法与reward组件都可以接入UniRL的统一训练闭环,使用户不必为每个模型、每个reward、每个rollout engine重新搭建一套训练脚本。
UniRL目前提供了完善的examples,方便大家体验和复现算法。
UniRL的目标不是提供某一个模型或某一个算法的单点实现,而是为多模态生成RL提供一套可复用、可扩展的基础设施。
通过统一rollout、reward、advantage、train与weight-sync的系统边界,UniRL希望降低多模态RL的工程门槛,让研究者把更多精力放在算法设计、reward设计和模型能力提升上。
目前,UniRL仍处于活跃迭代阶段。后续将继续完善核心训练闭环,扩展rollout engine支持,优化大规模训练性能,并探索更多硬件和部署环境下的适配能力。
GitHub代码库:https://github.com/Tencent-Hunyuan/UniRL
官方文档:https://unirl-project.github.io/unirl/
文章来自于"量子位",作者 "腾讯混元团队"。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
