# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
NANO滤波器是一种新的非线性贝叶斯状态估计方法,它不依赖线性化模型,而是将预测和更新步骤转化为优化问题。这种方法在高斯分布空间中使用自然梯度,更精确地逼近最优后验,同时利用Stein引理避免显式求导,提升鲁棒性。
卡尔曼滤波是现代工程系统的「隐形基础设施」,从航天导航、自动驾驶到机器人定位,几乎所有需要在噪声中追踪「真实」状态的任务,都离不开它。
但是物理世界很少满足线性假设:车辆运动学、激光雷达观测、机器人位姿变换、航天器轨道动力学,都可能把状态估计推向强非线性场景。
传统扩展卡尔曼滤波(EKF)、无迹卡尔曼滤波(UKF)等方法通常先把非线性模型近似成线性模型,再执行卡尔曼更新。这条路线高效、成熟,但在强非线性和异常观测下会引入不可忽略的近似误差。
近期,清华大学李升波教授、丘成栋教授的联合研究团队提出的NANO滤波器,给出了另一条路径:面向非线性对象,不再把解决思路的核心放在「如何线性化模型」上,而是把贝叶斯滤波的预测步和更新步重新表述为高斯分布空间中的优化问题,再用自然梯度在高斯流形上直接逼近最优高斯后验。

论文链接:https://ieeexplore.ieee.org/document/11434934/
实验显示,NANO滤波器于非线性滤波任务显著优于EKF、UKF、IEKF、PLF等经典方法。
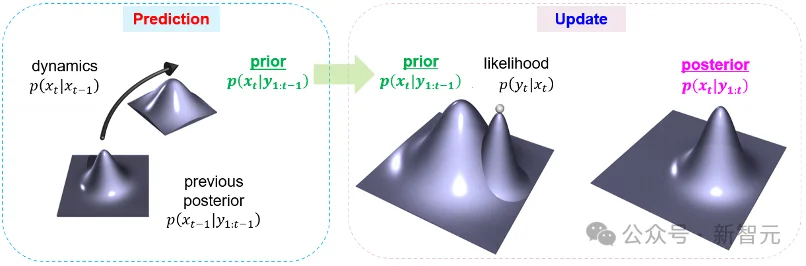
图1:贝叶斯滤波的两大阶段——预测和更新
滤波问题可以概括为一句话:如何在噪声和不确定性中,递归估计一个动态系统的真实状态。1960 年,Rudolf E. Kálmán 提出了今天所谓的卡尔曼滤波。该滤波器的思想极其简洁:先用系统模型预测下一时刻状态,再用传感器观测修正预测结果,如此循环。
在理论上,卡尔曼滤波可以看作贝叶斯滤波在线性—高斯条件下的解析特例。也就是说,当系统动力学是线性的、噪声服从高斯分布时,状态后验分布仍然是高斯分布,并且可以通过均值和协方差递推精确计算。但问题在于:真实世界很少具有满足完全线性的动力学系统。
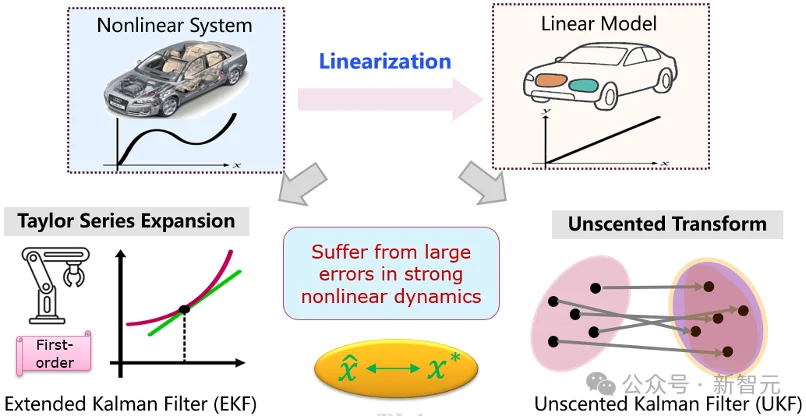
图2:EKF与UKF处理非线性的典型思路
现实的动力学系统往往具有强非线性。例如,自动驾驶车辆的三自由度模型、激光雷达观测模型、机器人位姿变换和航天器轨道动力学,都会引入复杂的非线性关系。此时,标准卡尔曼滤波赖以成立的线性—高斯解析结构不再存在。
工程界长期使用两类经典方法处理这一困难。第一类是扩展卡尔曼滤波(EKF):在当前估计点附近对非线性函数做一阶泰勒展开,把非线性系统局部近似为线性系统,再继续执行卡尔曼滤波。第二类是无迹卡尔曼滤波(UKF):不直接求雅可比矩阵,而是在当前高斯分布中选取一组代表性Sigma点,将这些点通过非线性函数传播,再重新估计传播后的均值和协方差。
从高斯滤波的统一视角看,这两类方法虽然技术路径不同,但大多遵循同一个基本范式:先构造一个可处理的线性—高斯近似,再执行线性版本的卡尔曼更新。这个范式的应用非常广泛,却也带来一个根本问题:它的滤波结果是「便于计算的近似值」,还是「高斯分布族」的最优解呢?
清华团队提出的核心问题:对于非线性贝叶斯滤波,传统「先线性化对象、再卡尔曼滤波」的框架,是否真能得到高斯分布最优解?
NANO滤波器的回答是:预测步可以由矩匹配给出最优高斯近似;但更新步一般不能靠一次线性化得到真正的最优高斯后验。
贝叶斯滤波有两个基本环节。预测步使用全概率公式,把上一时刻后验通过系统动力学传播到当前时刻,得到当前时刻的先验分布;更新步使用贝叶斯公式,把新观测并入先验,得到后验。传统表述强调「函数积分」和「条件概率」;NANO则从优化角度重新理解这两个公式。
贝叶斯滤波的经典递推公式
预测
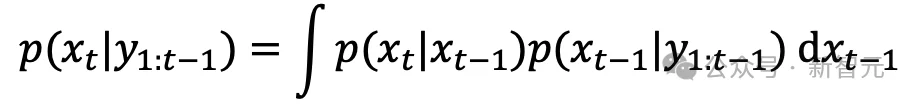
更新
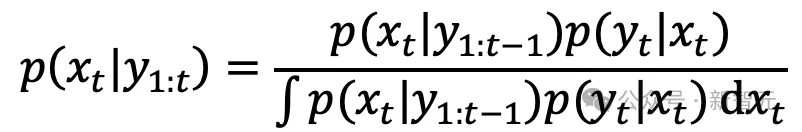
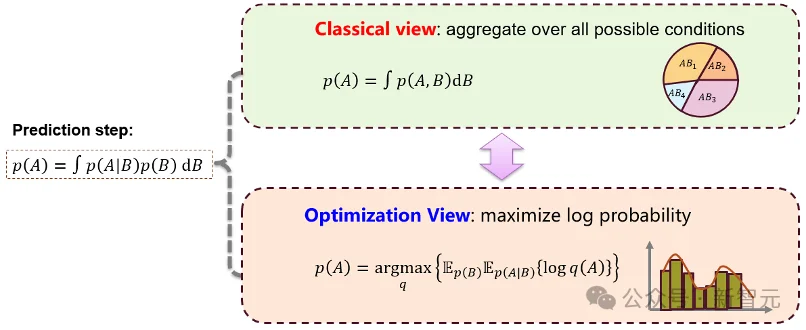
图3:全概率公式的优化视角
对于预测步,传统视角是对所有可能的上一时刻状态和状态转移进行积分;优化视角则是:在候选分布q中,以最大似然的方式选择最合适的q;更具体地说,就是使密度函数对数的期望最大。直观地说,预测步不是随意使用一个高斯分布进行拟合,而是在候选分布族中寻找最能解释状态传播结果的分布。
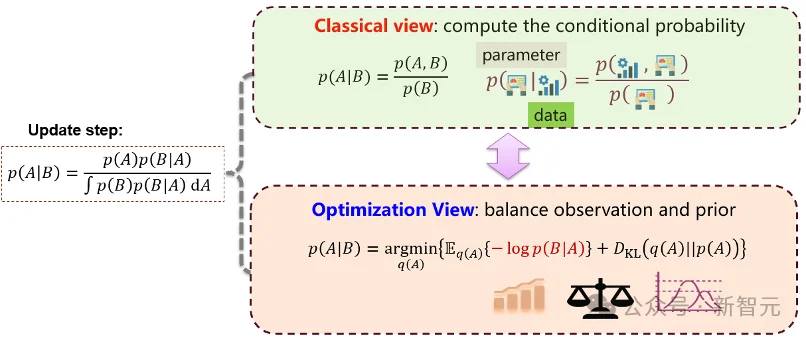
图4:贝叶斯推断的优化视角
对于更新步,传统视角是直接计算条件概率;优化视角则是:在候选分布q中同时平衡两件事:一方面状态估计值要解释当前观测的结果,另一方面不能偏离预测先验太远。前者对应观测拟合项,后者对应KL正则项。这一表述把贝叶斯更新变成了一个明确的变分优化问题。
两个变分优化问题

图5:贝叶斯滤波预测步与更新步的变分表述
这一步是NANO与传统线性化滤波的根本分野。传统方法先近似模型,再套用卡尔曼更新;NANO先将贝叶斯滤波等价为两个变分优化问题,再设计迭代优化算法去逼近它的最优解。
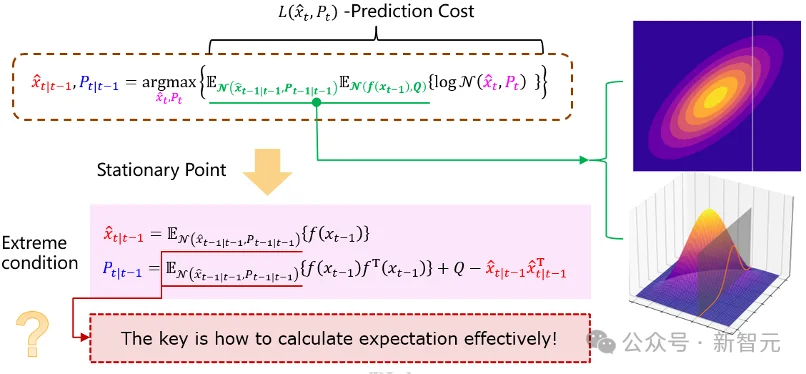
图6:预测步的极值条件与矩匹配

这说明,NANO并不是要「推翻」UKF、GHKF、CKF等矩匹配方法在预测步中的作用。
相反,NANO给出了它们在预测步中的优化视角解释:这些方法本质上是在用Unscented Transform、Gauss-Hermite求积或球面Cubature等数值积分方法,计算最优高斯预测所需的期望。

在线性—高斯系统中,这两个方程会解耦,并自然退化为标准卡尔曼滤波,这是为什么卡尔曼滤波的更新步仅需要一步迭代的原因。但在一般非线性系统中,它们没有解析解,因此不可能一步迭代就得到最优解。
对于这一更新步,已有的EKF、UKF等方法正是选择线性化或统计线性回归等手段近似极值点,这使得它们并不是非线性对象的真实最优解。
NANO的选择则是:不再绕开这个非线性优化问题,而是采用梯度下降法直接求解它。
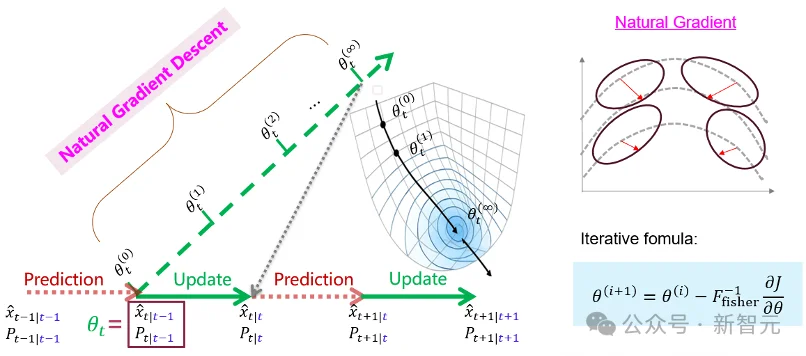
图7:NANO滤波器的自然梯度迭代流程
普通梯度下降默认参数空间是欧氏空间。但高斯分布的参数并不是普通向量:均值和协方差共同决定一个高斯分布;所有高斯分布构成的空间,本身是一个具有几何结构的流形。自然梯度的作用,就是利用Fisher信息矩阵修正梯度方向,使迭代方向对应高斯流形上的最陡下降方向。
NANO的自然梯度形式
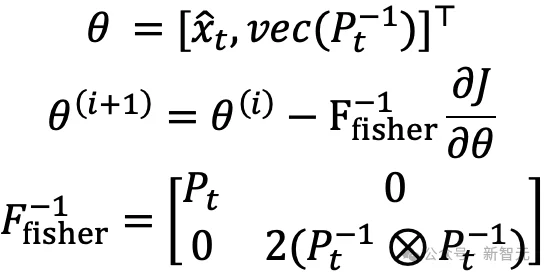
将上述自然梯度展开,可以得到NANO更新步的第一类显式迭代公式:
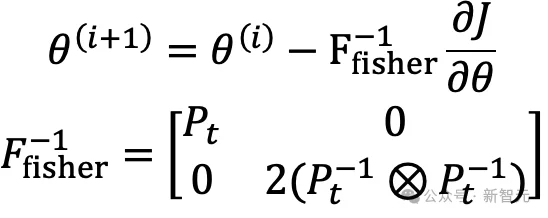
NANO更新步的显式迭代
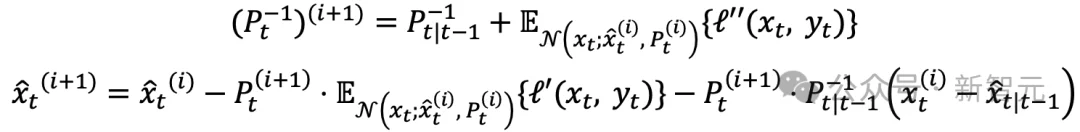
这组公式的含义很直接:每次迭代都在当前高斯后验附近重新计算观测损失的一阶导数期望和二阶导数期望,再更新均值和精度矩阵(即协方差矩阵的逆矩阵)。
相比直接更新协方差,精度矩阵形式更贴近贝叶斯更新中的信息累积结构,也更便于刻画自然梯度的几何意义。
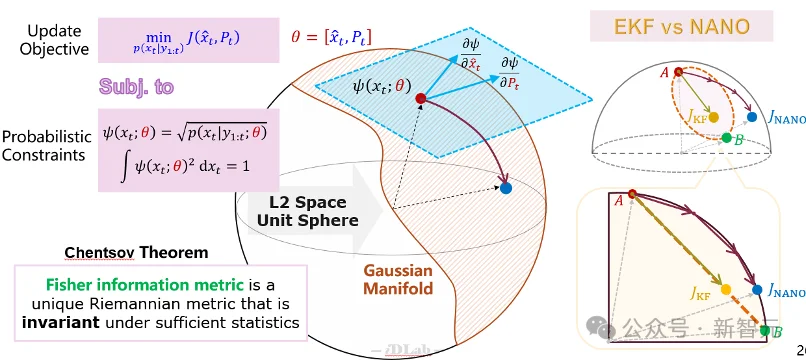
图8:信息几何视角下的自然梯度更新
从信息几何角度看,NANO不是沿着参数坐标系中「看起来下降最快」的方向走,而是沿着概率分布流形上真正的最陡下降方向走。Fisher信息度量在这里扮演了「几何尺子」的角色:它把均值、协方差变化对分布本身的影响纳入同一尺度。
对于工程系统而言,一个关键障碍是观测函数h(x)可能非常复杂。它可能来自激光雷达几何匹配、机器人运动学、甚至偏微分方程数值求解。若算法必须显式计算h(x)的一阶、二阶导数,落地难度会显著增加。NANO的一个重要设计,是利用Stein引理把「损失函数导数的期望」转化为「损失函数本身的加权期望」。

图9:Stein引理下的无梯度迭代形式
真实传感器数据经常包含异常值。标准贝叶斯更新默认似然模型准确,一旦观测噪声出现重尾或离群点,滤波器容易被异常观测牵引。
NANO的优化表述天然支持把负对数似然替换为更一般的观测损失函数,从而得到Gibbs后验形式。在这一框架下,Huber loss、加权log-likelihood、β-cross entropy等鲁棒损失都可以进入同一个滤波器设计。
更重要的是,由于NANO可以通过Stein引理采用零阶损失函数评估形式,鲁棒损失不必总是满足光滑且易求导的苛刻条件。这使NANO可以自然扩展出Huber-NANO、Weight-NANO、β-NANO等鲁棒版本。
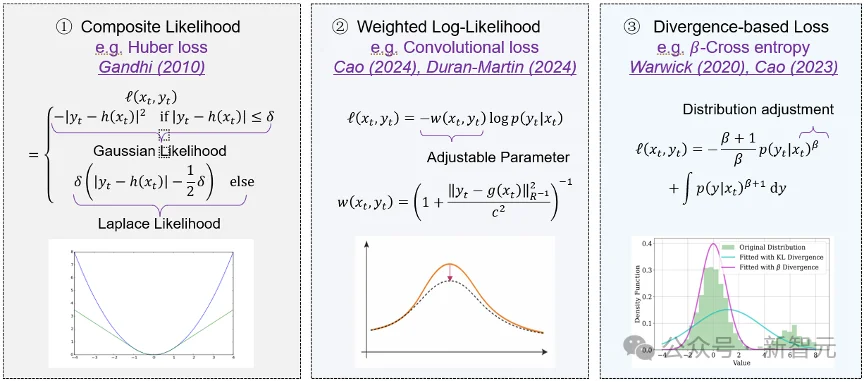
图10:Gibbs后验的三类设计形式
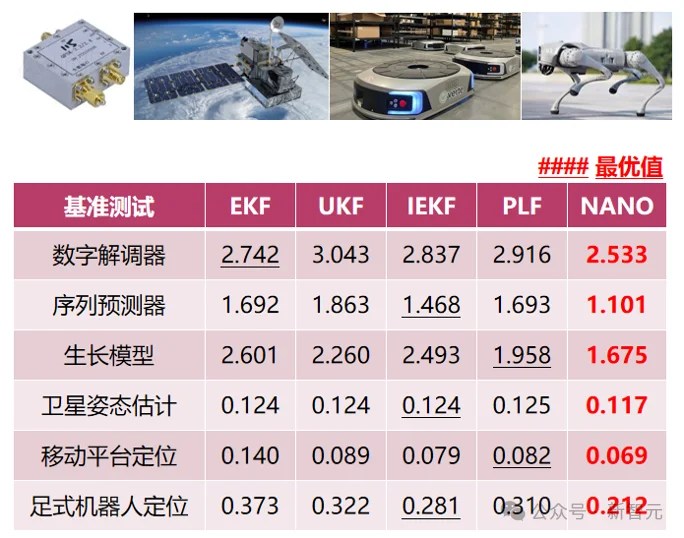
图11:基准测试任务的性能对比
典型非线性滤波任务,NANO都表现出稳定的性能优势。测试任务覆盖数字解调器、序列预测器、生长模型、卫星姿态估计、移动平台定位和四足机器人定位等非线性对象。相比EKF、UKF、IEKF、PLF等经典基线,NANO均取得了最低的均方根误差。
过去几十年,非线性高斯滤波的主线基本围绕「如何更好地线性化模型」展开。NANO把问题推进到另一个层面:既然滤波的目标是获得后验分布,就应该直接在分布空间中定义最优性,并设计算法逼近这个最优分布。
因此,NANO的意义在于重新组织了非线性贝叶斯滤波的理论结构:预测步对应最优高斯矩匹配,更新步对应高斯流形上的自然梯度优化,复杂观测可通过Stein引理规避显式求导,异常观测可通过Gibbs后验自然处理。
开放性问题
这一优化框架也留下了若干开放性问题:
其一,预测变分问题的目标函数是否仍有进一步修正或推广的空间;
其二,更新变分问题中的KL散度是否可以替换为其他分布度量,比如说Wasserstein度量;
其三,先验与后验分布是否可以由高斯分布族扩展到指数分布族,甚至更一般的概率分布族;
其四,对于预测与更新两个变分问题得到的近似解,是否可解释为真实状态的「无偏估计」,或者说目标函数满足什么条件时,这两个变分优化问题的解仍然是真实状态的「无偏估计」。
参考资料:
[1] Cao, W., Zhang, T., Sun, Z., Liu, C., Yau, S. S.-T., & Li, S. E. (2026). Nonlinear Bayesian filtering with natural gradient Gaussian approximation. IEEE Transactions on Pattern Analysis and Machine Intelligence. https://doi.org/10.1109/TPAMI.2026.3674120
[2] Zhang, T., Cao, W., Liu, C., Zhang, F., Wu, W., & Li, S. E. (2025). NANO-SLAM: Natural gradient Gaussian approximation for vehicle SLAM. In Proceedings of the 28th IEEE International Conference on Intelligent Transportation Systems (ITSC), Gold Coast, Australia
[3] Zhang, T., Cao, W., & Li, S. E. (2026). Natural gradient Gaussian approximation filter with positive definiteness guarantee. In Proceedings of the American Control Conference (ACC), New Orleans, Louisiana, USA
[4] Cao, W., Zhang, T., and Li, S. E. (2025). Algorithm Design and Comparative Test of Natural Gradient Gaussian Approximation Filter. IFAC Modeling Estimation and Control Conference (MECC), Pittsburgh, USA
[5] NANO滤波器的代码链接:https://github.com/wenhancao/NANO-idlab
文章来自于"新智元",作者 "LRST"。



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
