# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
今天几乎所有主流视觉语言模型(VLM)—— 无论是 Qwen-VL、InternVL,还是 LLaVA 系列 —— 都遵循着同一套经典架构:先用预训练视觉编码器(如 CLIP、SigLIP)将图像压缩为特征,再通过投影层把这些特征送入大语言模型。
这套「视觉编码器 + 投影层 + 大模型」的模块化范式非常成功,但也有一个天然前提:视觉信息在进入推理之前,就已经被压缩和过滤,一部分细节不可避免地丢失了。
NEO-ov 想挑战的正是这一假设:如果直接抛开视觉编码器,让模型从原始像素一路学到语言,会怎么样?
答案是:不仅可行,而且效果出色。在细粒度感知和空间理解等任务上,NEO-ov 甚至超过了不少依赖视觉编码器的强模型,展现出端到端视觉语言建模的潜力。

论文将传统「视觉编码器 + 大模型」范式的局限概括为三个方面:
更深层的问题在于,现有视觉编码器(如 CLIP)主要为图文对齐而设计,更关注高层语义,却往往会丢失纹理、局部几何以及精细空间结构等信息。结果是,语言模型实际上是在一套「被语义过滤过」的视觉表征上进行推理,而不是真正面对原始视觉信号。这种信息损失在依赖跨视角、跨帧理解的空间智能任务中尤为明显,也正是 NEO-ov 希望突破的核心瓶颈。

NEO-ov 的核心理念可以浓缩成一句话:没有外部编码器、没有适配器、没有事后融合 —— 视觉感知、时序建模和跨模态对齐,全部在同一个统一骨架中端到端学习。它建立在前作 NEO 的基础上,将原生视觉语言建模从单图扩展到单图、多图、视频乃至空间智能任务,形成了一套统一框架。其中有几个关键设计值得关注。
用两层卷积当「像素入口」,不再过厚重的编码器
与主流 VLM 依赖 CLIP 等视觉编码器不同,NEO-ov 直接从原始像素出发,仅用两层卷积和 GELU 构成轻量级视觉入口。经过两次下采样后,每个 32×32 图像区域都会被映射为一个视觉 token。
随后,这些视觉 token 被 <img>和</img>标记包裹,与文本 token 一起组成统一序列,送入同一个 Transformer。视觉理解、语言建模和跨模态对齐不再由不同模块分工完成,而是在统一骨架中端到端学习。
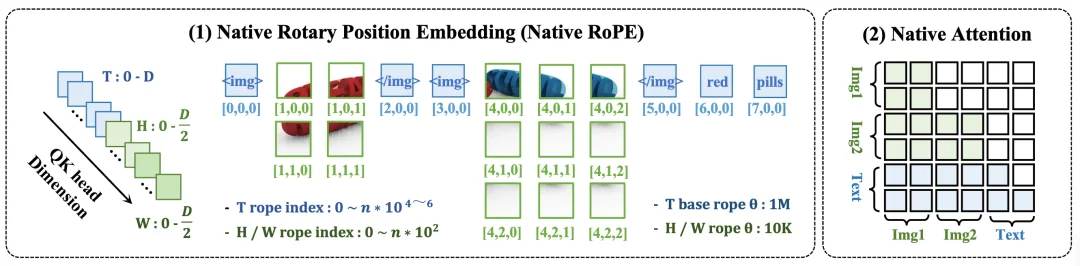
「时间 + 高 + 宽」解耦,同时建模时序和空间
这是模型能够「统一时空」的关键。它将注意力头的维度显式拆分为三部分:
配套的 Native-RoPE 位置编码进一步将时间和空间解耦建模:文本 token 仅保留时间索引;图像 token 在同一张图像内共享时间索引,并通过 H/W 索引编码其空间位置。
单图、多图、视频,统统排成同一条序列
单图:在<img>位置插入视觉 token。每张图都会按照原始分辨率独立编码,token 数量随图像尺寸自适应变化,而不是被压缩到固定预算中。模型能够保留更多局部细节,对细粒度比较、目标定位和空间敏感任务尤其有利。
多图:每张图都被视为序列中的一个独立视觉单元,与文本一样按照输入顺序排列。模型无需额外设计跨图模块,就能直接利用统一注意力机制建立图像之间的关联。
视频:将视频采样为若干帧,每一帧都作为一个带时间戳的图像单元插入序列,并在开头添加一个全局前缀,用于记录视频时长、采样帧数和采样率等信息。这样一来,视频本质上被表示为「按时间排列的多张图像」,视频理解与多图理解自然统一到同一套框架之中。
图片内部「互相看」,图片和文字之间「往前看」
每张图像或视频帧都会被视为一个独立的「视觉单元」:
这样一来,跨图比较和时序推理从最底层的 patch 级 token 就已经开始,并随着网络层数加深不断细化,而不是像传统模块化 VLM 那样,只能在视觉编码器压缩后的表征上进行推理。

NEO-ov 采用循序渐进的三阶段训练方案,数据规模、分辨率和任务复杂度逐步提升:
模型规模方面,团队基于 Qwen3-1.7B 和 Qwen3-8B 分别训练了 NEO-ov 2B 和 NEO-ov 9B 两个版本。
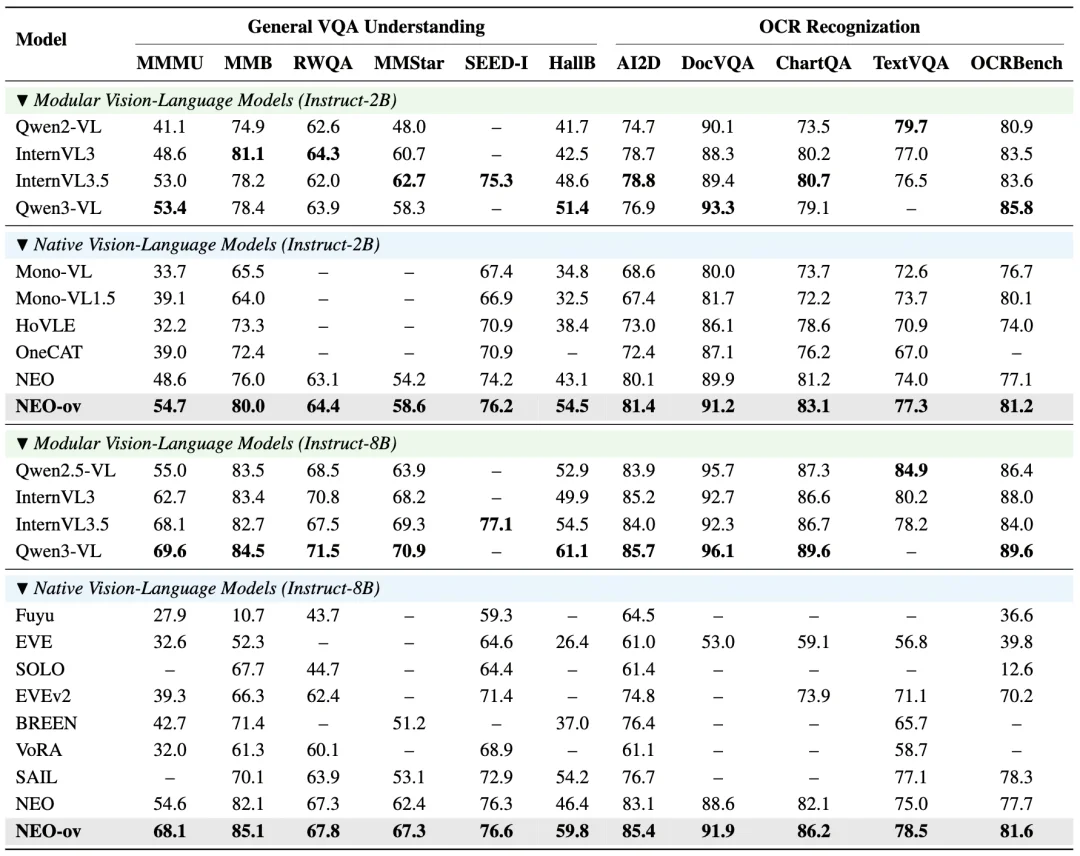
图像理解:原生 VLM 的新 SOTA。在 2B 和 9B 两个规模上,NEO-ov 都刷新了原生 VLM 的性能上限,全面超过 EVE、Mono-InternVL、OneCAT、SAIL 等同类工作,在 MMMU、HallusionBench、InfoVQA 等强调推理能力和抗幻觉能力的基准上优势尤为明显。更值得关注的是,在完全不依赖预训练视觉编码器的情况下,NEO-ov 依然能够在多个感知与推理基准上追平甚至超过 InternVL3.5、Qwen3-VL 等顶尖模块化模型,证明了端到端原生架构同样具备竞争最强 VLM 的潜力。
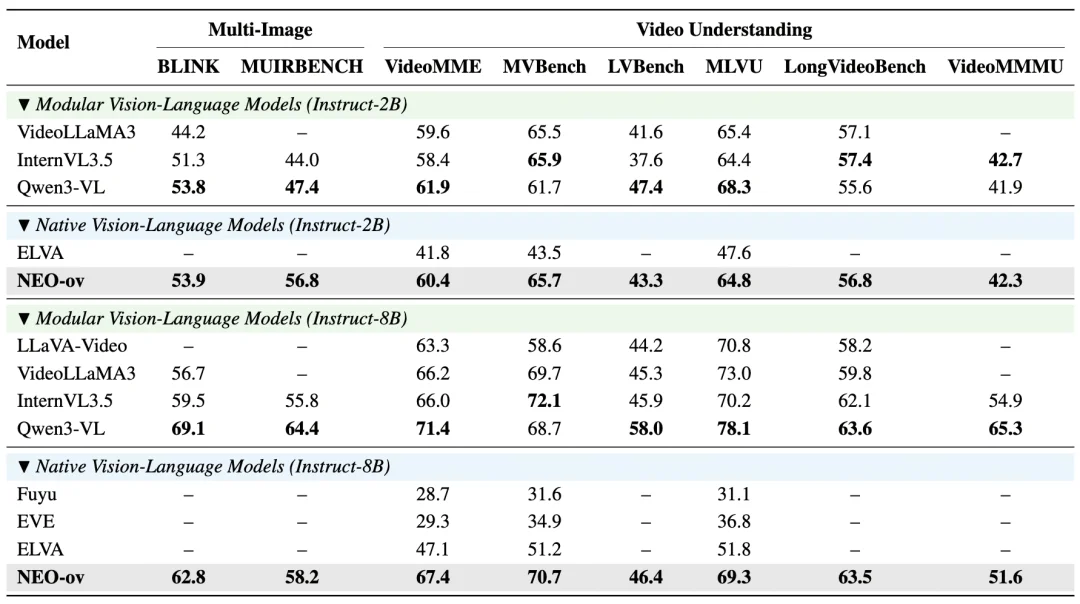
多图与视频理解:原生架构首次具备与主流 VLM 正面竞争的实力。相比 Fuyu、EVE、ELVA 等此前的原生模型,NEO-ov 在 VideoMME、MVBench、MLVU 等视频基准上实现了大幅领先,展现出强劲的时序推理和长上下文理解能力。更重要的是,在 BLINK、MUIRBench、LongVideoBench 等多图与长视频任务上,NEO-ov 已经能够与 VideoLLaMA3、InternVL3.5 等顶尖模块化模型正面竞争。这表明原生架构不仅能做好单图理解,也具备了处理复杂时空信息的能力。
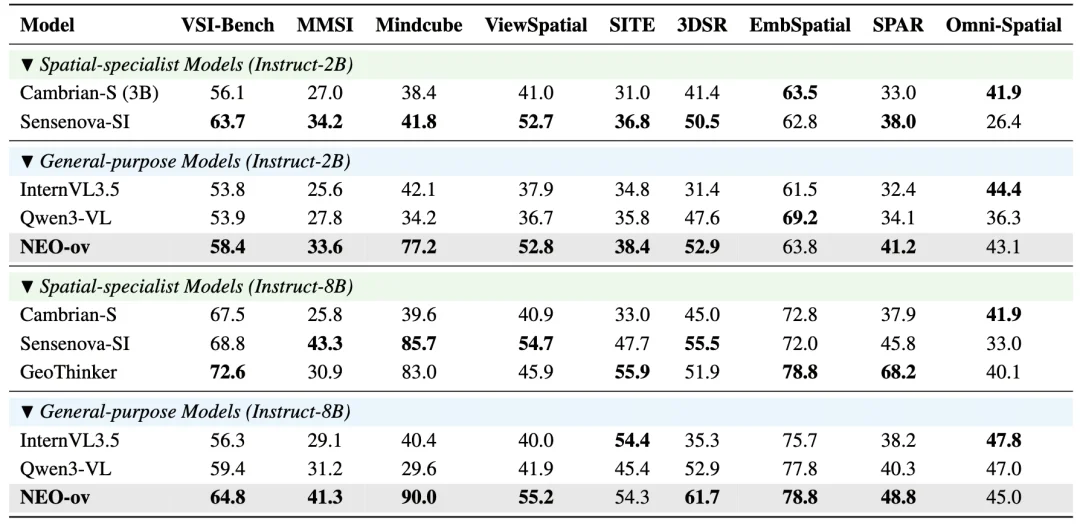
空间智能:NEO-ov 最亮眼的突破。作为一个通用原生模型,NEO-ov 在几何推理、空间感知和具身理解等空间智能任务上,已经达到甚至超过 Cambrian-S、Sensenova-SI、GeoThinker 等专门设计的模型。在 ViewSpatial、3DSR、SPAR 等基准上,它相较其他通用 VLM 也展现出明显优势。这表明 NEO-ov 的优势不仅体现在感知和推理能力上,更体现在对空间关系和三维结构的理解能力上。
拆开看:为什么原生架构在空间任务上更占便宜
论文也没有回避短板: NEO-ov 目前在部分单图和视频基准上,它与 Qwen3-VL 等模型仍有差距,这可能与训练数据的规模和质量有关。OCR 和文档理解也是一个相对明显的短板:相比模块化模型,NEO-ov 缺少专门针对 OCR 的预训练,因此在这类任务上表现不够突出。换句话说,原生多模态建模的优势已经开始显现,但远没有到达上限。后续如果能继续扩大模型规模、丰富训练数据,并加强长上下文训练,这一路线仍有很大的提升空间。
NEO-ov 想传达的,其实是一个关于多模态智能来源的判断:多模态智能未必只能来自精心设计的视觉编码器、适配器和融合模块,也可能从一个原生、统一、端到端的架构中自然涌现。
实验表明,完全摆脱视觉编码器的原生视觉语言模型不仅可行,而且在规模化之后已经具备与顶尖模块化系统竞争的实力。对这条技术路线而言,NEO-ov 或许还不是终点,但无疑是一块重要的进展。它让「原生统一的视觉基础模型」从一个理想,变成了一条正在被验证的现实路径。
文章来自于"机器之心",作者 "刁海文"。



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
