# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
让我们想象一个场景:
机械臂夹起桌上的杯子,正准备把它放进盘子。下一秒,抓取失败,杯子重新掉回桌面。
从时间上看,后一幅画面发生得更晚;但从任务目标来看,机器人不仅没有取得进展,反而退回了原点。人类很容易看出这种变化,视觉语言模型却可能给出相反答案。
原因并不难理解。大量机器人视频都按正常时间顺序记录:先接近物体,再抓取,最后完成放置。在这样的数据里,「后面的画面更接近任务完成」往往成立。模型训练得越久,就越可能记住这条省力的捷径。它能认出杯子、盘子和机械臂,也能描述画面中的动作,却未必真正理解:这些动作究竟有没有推动任务向前。
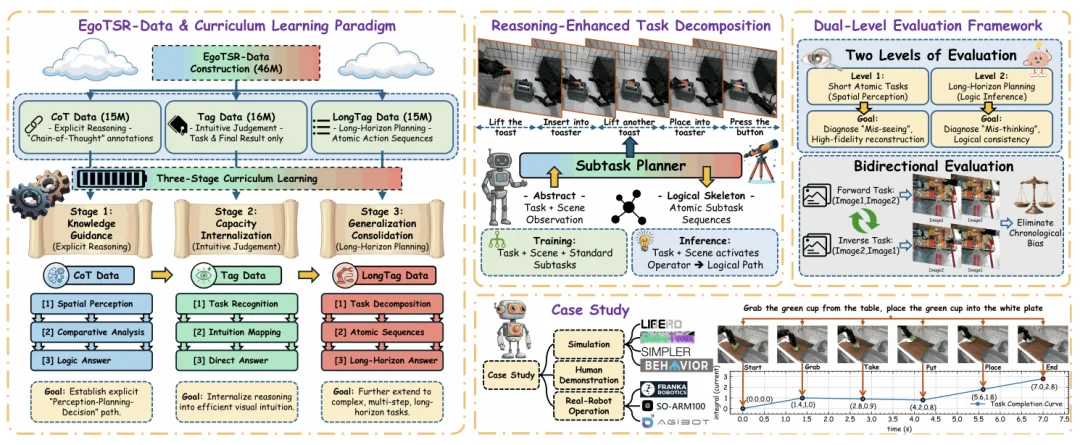
针对这一问题,浙江大学等五所高校的研究团队提出 EgoTSR。研究从第一人称机器人视角出发,希望让 VLM 学会判断任务状态,并把这种能力进一步扩展到长程规划。团队构建了包含 4600 万条样本的 EgoTSR-Data,并设计了三阶段课程学习流程。

时间偏置:后出现的画面,真的更接近任务完成吗?
EgoTSR 关注的并不是传统动作识别,而是一个更具体的问题:给定两张来自同一任务视频的图像,哪一个状态更接近任务目标?
例如:
把绿色杯子从桌上拿起来,放进白色盘子中。
模型不能只判断图中是否出现杯子和盘子,还要看杯子是否被抓住、是否正在移动、是否真正进入目标区域。
如果任务是「打开冰箱门」,门打开的状态更接近完成;如果任务是「关闭冰箱门」,判断恰好相反。同一幅图的任务意义,会随着目标发生变化。
真正可靠的模型还必须处理现实中的动作失败和状态回退:机械臂可能已经抓住物体,却在移动过程中将其掉落;抽屉可能被拉开,随后又因碰撞重新关闭;物体可能短暂到达目标区域,之后再次被移走。
因此,时间更晚并不意味着任务完成度一定更高。
研究团队将模型依赖输入顺序进行判断的现象称为「时间顺序偏差」,即 chronological bias。为了直接暴露这种捷径,EgoTSR 采用了一个简单但有效的办法:把同一对图像分别按照正向和反向顺序交给模型。
假设图像 B 比图像 A 更接近任务完成。
第一次输入为:
图像 A,图像 B。
正确答案是第二张图。
随后交换顺序:
图像 B,图像 A。
正确答案必须随之变成第一张图。
如果模型始终选择第二张图,那么它可能并没有分析物体状态,而是在根据图片位置猜测答案。
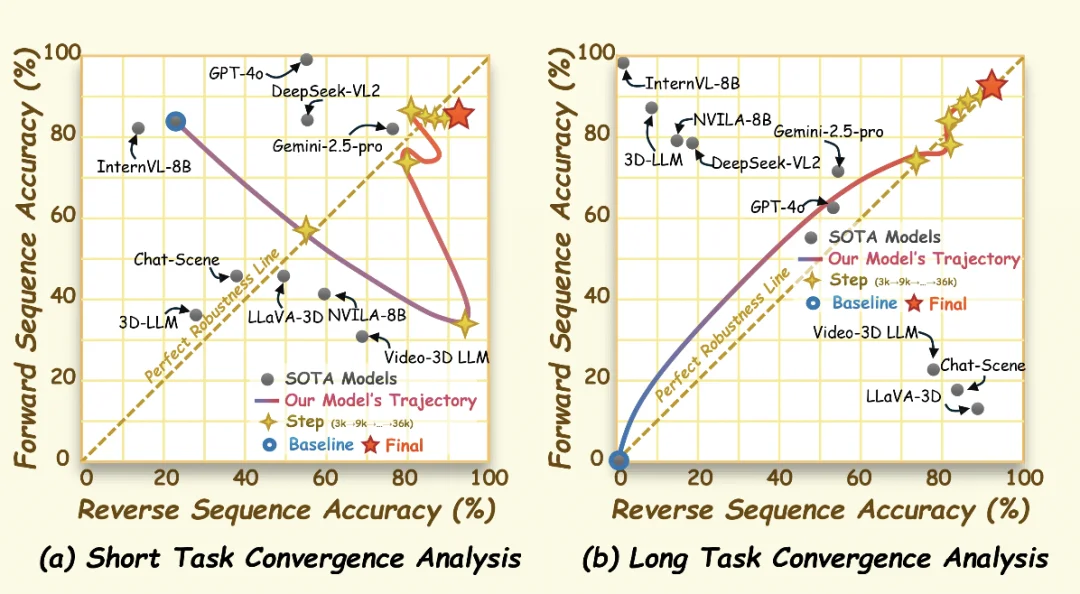
实验中,这种现象非常明显。以部分长任务评测为例,InternVL-8B 在正向输入下的准确率接近 99%,但交换图像顺序后,准确率降至约 2%。表面上接近满分的结果,经过反向测试后,暴露出严重的顺序依赖。
三阶段课程:先解释,再内化,最后规划
EgoTSR 没有把全部数据直接混合训练,而是按能力发展顺序分成三个阶段。
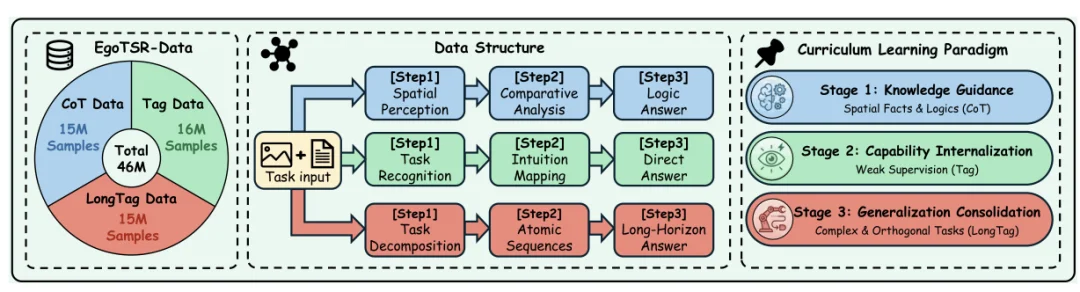
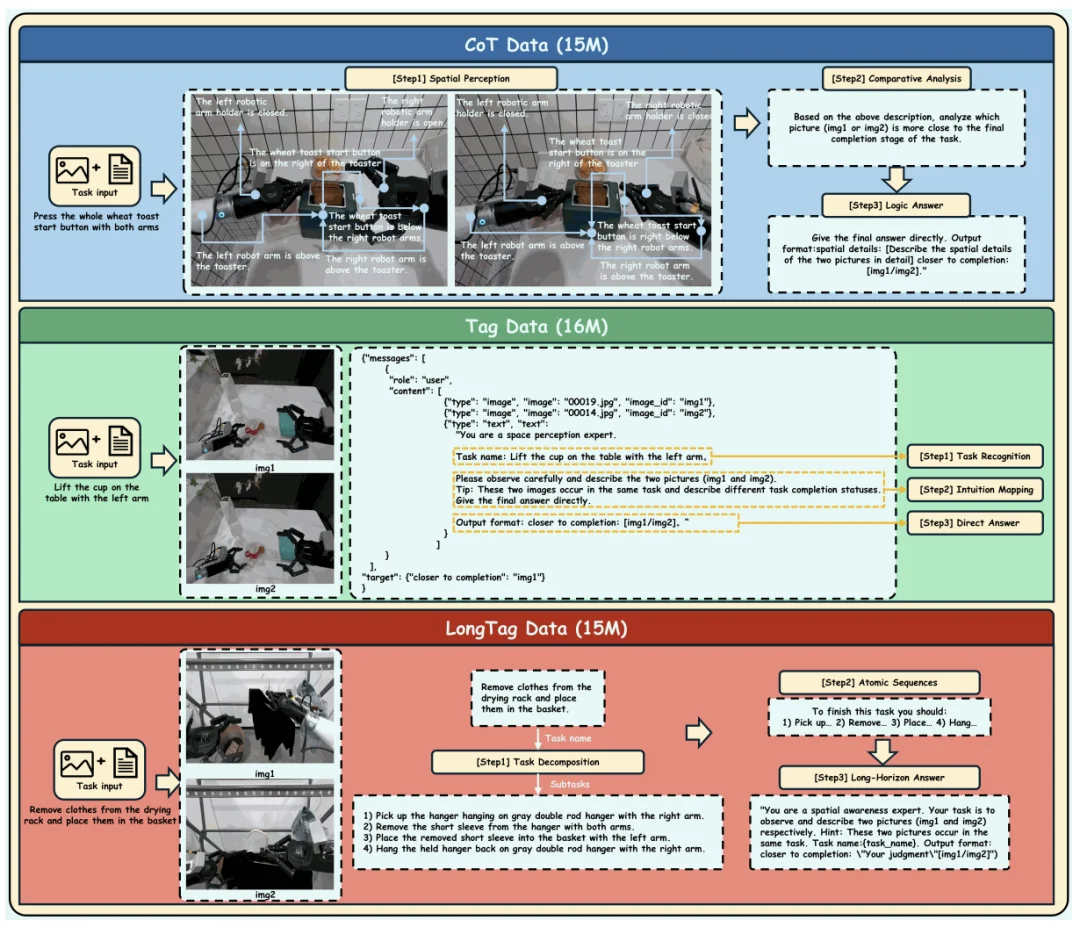
第一阶段使用约 1500 万条 CoT 数据:模型需要先描述两张图中的空间状态,再比较哪张图完成了更多必要动作,最后给出答案。这个阶段的重点,是建立视觉状态、任务目标和最终判断之间的联系。
第二阶段使用约 1600 万条 Tag 数据:详细推理文本被移除,只保留图像、任务和正确标签。模型需要直接判断哪张图更接近完成。作者希望将第一阶段形成的显式推理,逐渐转化为更快速的任务状态判断。
第三阶段加入约 1500 万条 LongTag 数据:把能力从单个动作扩展到长程任务。至此,三类数据合计 4600 万条。
子任务规划器:高层语义任务分解为多个细粒度子任务
「拿起杯子」是一个相对明确的原子任务,但真实机器人通常需要完成更复杂的目标。
例如:
打开冰箱,取出饮料,把饮料放到桌面,并重新关上冰箱门。
如果模型只看到「饮料已经被拿起」,可能会认为任务已经接近结束。但从完整目标来看,机器人还需要把饮料放到桌面,并关闭冰箱门。
为此,EgoTSR 引入了一个 Subtask Planner,也就是子任务规划器。它根据初始场景和高层任务描述,生成一组具有明确顺序的原子子任务。
上面的任务可以被拆解为:
这组子任务构成了整个任务的「逻辑骨架」。
模型看到两张图后,不再只比较局部物体位置,而是进一步判断:每张图分别位于任务链的哪个阶段,已经完成了多少必要步骤,后续还剩下哪些动作。
论文将长任务图像对分为三个层次:同一子任务内部、相邻子任务之间,以及跨越多个子任务的状态比较。随着跨度增加,模型需要利用的就不再只是局部视觉变化,而是整个任务的因果和顺序结构。
值得注意的是,这里的「规划」主要指高层任务分解和任务进度推理。EgoTSR 并不直接输出机械臂的关节角、力矩或运动轨迹,而是为机器人提供「任务进行到哪里」和「后续还需要完成什么」的认知基础。
双层评测:既看是否「看清除」,也看是否「想明白」
研究团队构建了 Dual-Level Evaluation Framework。
第一层是短程原子任务,考察模型能否捕捉细粒度空间变化,例如夹爪是否闭合、按钮是否按下、物体是否进入容器。这一层主要诊断模型是否「看错了」。
第二层是长程任务,要求模型结合子任务序列,判断两张图在完整任务中的相对进度。这一层主要诊断模型是否「想错了」。
两个层级都加入了正向和反向输入测试,用来检查模型是否依赖图像顺序。
最终,EgoTSR 在长程任务上取得 92.4% 的平均准确率,短程任务表现约为 88%。在长程双向评测中,正向准确率约 92.4%,反向约 92.3%,差距仅 0.1 个百分点。
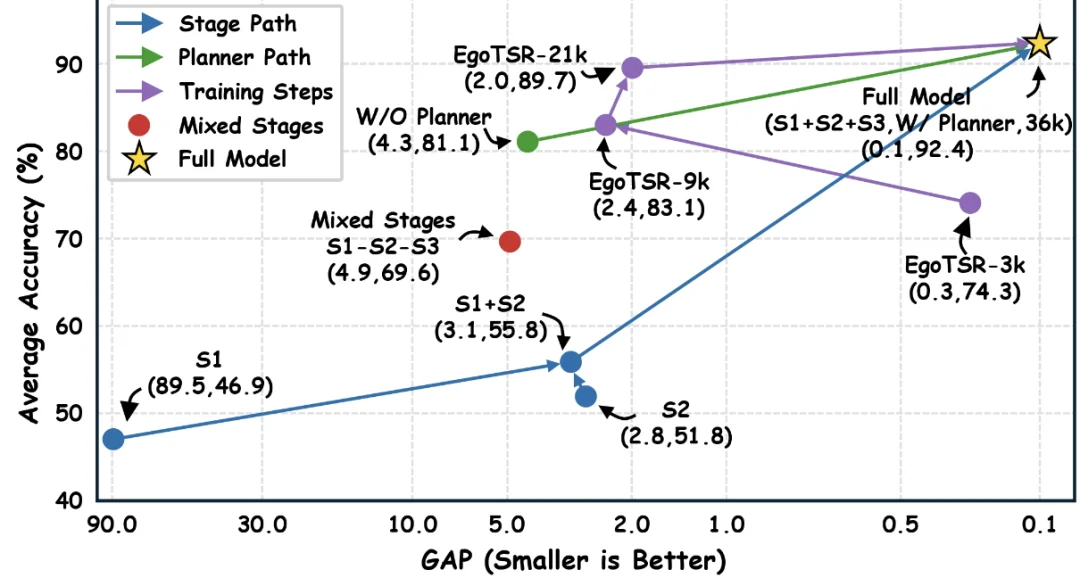
消融实验也说明了训练顺序的重要性。将 CoT、Tag 和 LongTag 混合训练时,长任务准确率只有 69.6%;按「显式推理 — 能力内化 — 长程规划」的顺序训练后,准确率提升到 92.4%。去掉 Subtask Planner 后,准确率则下降到 81.1%。
从任务判断走向任务完成度监测
除了定量评测,研究团队还在人类操作视频、模拟环境和真实机器人平台上进行了案例验证,涉及 LIBERO、SIMPLER、RoboTwin,以及 Franka、Agibot 和 So-100 等机器人平台。
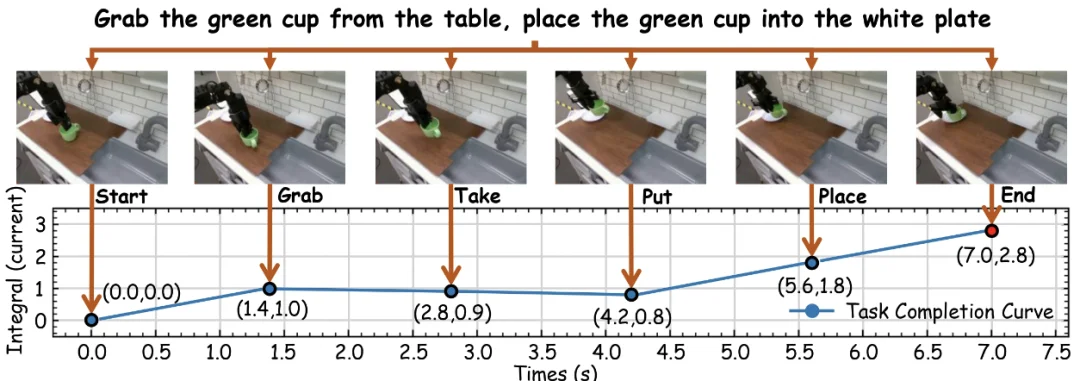
在「把绿色杯子放进白色盘子」的案例中,模型持续处理未经切分的完整视频,并输出一条任务完成度曲线。
当机械臂接近杯子时,曲线缓慢变化;完成抓取和放置等关键子任务时,完成度出现明显上升;中间的搬运过程则保持相对稳定。
这意味着 EgoTSR 不仅可以比较两张静态图,还具备用于长视频任务监测的潜力,例如判断机器人当前处于哪个阶段、是否发生了动作回退,以及任务是否正在按照预期推进。
机器人需要的不只是「看见」
从静态图像识别走向真实机器人,模型面对的问题发生了根本变化。
在图像问答中,识别出杯子、盘子和机械臂可能已经足够;但在具身任务中,模型还需要理解这些物体之间的变化是否服务于当前目标。
机械臂动了,不代表任务取得了进展;视频继续播放,也不代表机器人越来越接近成功。
EgoTSR 的价值,一方面在于提供了一种从显式推理逐步过渡到长程规划的训练路径;另一方面,它通过正向和反向图像对,为具身模型设计了一把更加严格的「尺子」。
当然,这项工作距离完整的通用机器人系统仍有明显距离,但它至少揭示了一个容易被高准确率掩盖的问题:
当一个模型声称自己理解了机器人视频时,它究竟是在分析物体、动作和任务之间的因果关系,还是只是在重复「后一张图通常更接近完成」这一数据规律?
对于希望进入真实世界的具身智能而言,回答这个问题,或许比单纯提高几个百分点的准确率更加重要。
文章来自于微信公众号 “机器之心”,作者 “机器之心”


