# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
所有人都在等下一个 SOTA 模型的诞生,但你不知道的变化,正悄悄发生在模型前侧。
在过去一年里,router 已经从 “把请求分给哪个模型” 的转发代理,演变成了模型推理的核心 “总指挥”。
它的目标扩展为:
上面这些都是 router 从传统的路由转发,演进出来的 “系统智能”。
vLLM 社区推出的 Semantic Router 除了专注上面三个方向,正在更进一步:
我们认为:router 不只是选择模型,还可以提升模型能力。
用户不用改权重,也不用让每个 Agent 团队都自己搭一套 Graph,而是在一次普通 Model API 调用的内部,组织出一支有边界、有预算、有验证、有回退的 “小队”。
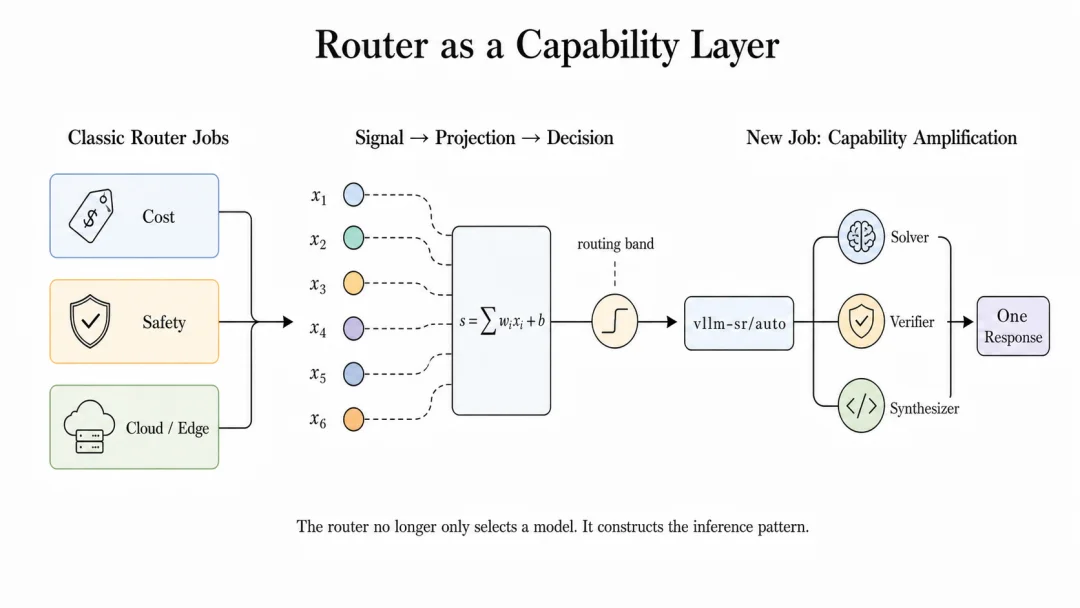
图 1:router 正在从 “模型选择层” 变成 “能力构造层”。
最近日本的 AI 公司 Sakana Fugu 热度很高,也引发了众多的讨论,他们推出的 Fugu 模型,是这个想法的商业化的版本:用户看到的是一个虚拟模型,但实际背后却是一组模型的动态协作。
而 vLLM Semantic Router 团队从 2025 年的年初就开始专注智能路由领域,并在开源的方式构建和协作,推出了 Micro-Agent 来解决这个问题。
用户仍然只调用一个模型:
{
"model":"vllm-sr/auto",
"messages":[{"role":"user","content":"..."}]
}
但在这个稳定的 model 后面,router 可以根据意图,智能的选择路由配方,fan out 到多个 worker,收集 quorum,判断分歧,合成答案,修复输出格式,最后返回一个普通的 OpenAI-compatible response。
整个协作的过程,像调用一个普通模型一样简单。
Looper:把 Micro-Agent
放入到 Serving Runtime
在 vLLM Semantic Router 处理请求的过程中,looper 是 micro-agents 的运行时。
当一次请求进入 router 时,它仍然是一条普通 chat completion。router 会通过不同角度,先抽取异构的语义 signals,再把离散的 signals 投影成 task shape、difficulty、risk、contract pressure 等可用于策略判断的低维向量,然后基于命中 decision,最后到不同的路由算法。
这个算法可以是匹配最适合这个任务的单模型,也可以是一个多模型协作的 Loop。
当前的 looper patterns 有五类:
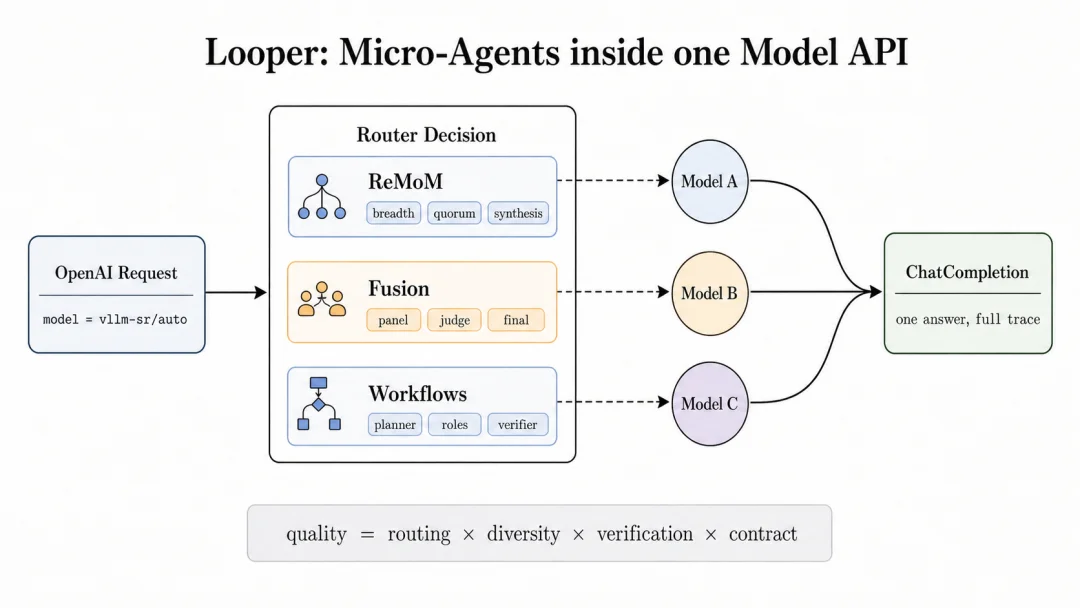
图 2:looper 在 router 内部运行 micro-agents,同时保持外部 Model API 不变。
我们的设计里,做了克制的工程化实现,不同的 looper 算法需要综合控制预算、拓扑、并发、timeout、retry、fallback 和 output contract 以及可观测性,确保它在 routing 过程中的可靠性以及稳定性。
同时我们认为不同的 looper 算法适用于不同的场景,也有不同的收益:
Confidence:只把升级花在
难解决的问题上
Confidence 是 cost-aware loop。它先用较小或较便宜的 candidate 生成答案,再判断这个答案是否足够可信。confidence signal 可以是 token-level log probability、logprob margin、hybrid score、self-verification 生成的,也可以是 AutoMix-style entailment verifier 生成的。
但是如果分数超过阈值,router 直接返回。如果分数不够,route 才会升级到下一个 candidate。
这让 “是否升级” 从应用层的隐式逻辑,变成 router 的显式策略:threshold、failure behavior、stopping condition 都可以被配置、观察和复现。
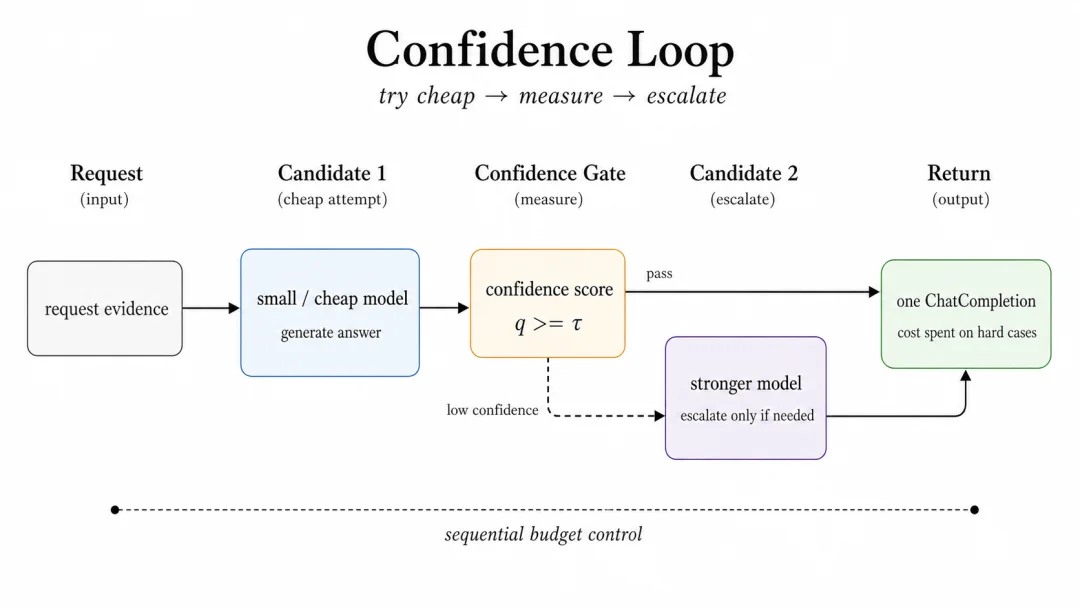
图 3:Confidence 把模型升级变成可度量的 stopping policy。
Ratings:硬上限约束下的
并行质量控制
Ratings 是 controlled ensemble loop。它会并行启动多个 candidate,但只到配置里的 max_concurrent 上限为止。这样一个 route 可以吸收多个模型视角,又不会把每个请求都变成无边界 fan-out。
router 收集成功的返回,按 rating-aware 聚合结果,并按预定义策略去处理失败。它适合 A/B-style evaluation、ensemble strategies,以及 operator 已经有 candidate quality signal 的场景。
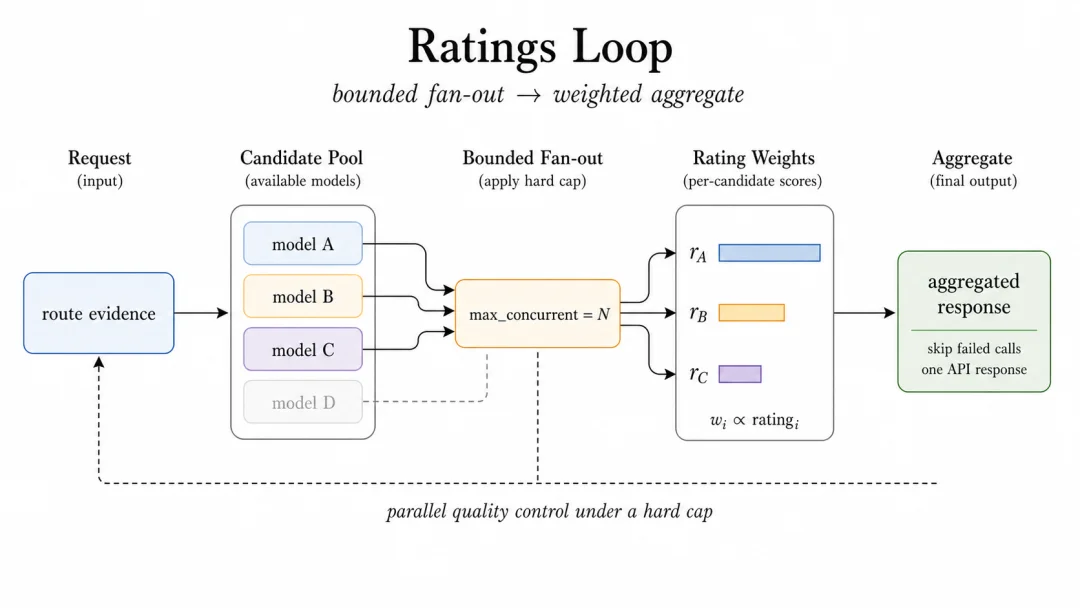
图 4:Ratings 让多候选执行保持有界,并把评分信号纳入聚合。
ReMoM:有契约的 Breadth
ReMoM 适合高推理方差任务模式。它先展开 breadth samples,让多个 worker 独立产生证据;然后通过 minimum-success quorum 判断是否有足够有效材料;最后由 synthesis model 合并证据,并修复成目标输出格式。
它不是 “三个模型投票”。更准确地说,它是一条有 quorum、有 synthesis、有 fallback 的服务路径。
如果 synthesis round 失败,但如果前面已经有了有效证据,router 就不需要直接返回失败。它可以回退到 best valid evidence,仍然返回一个正常 API response。
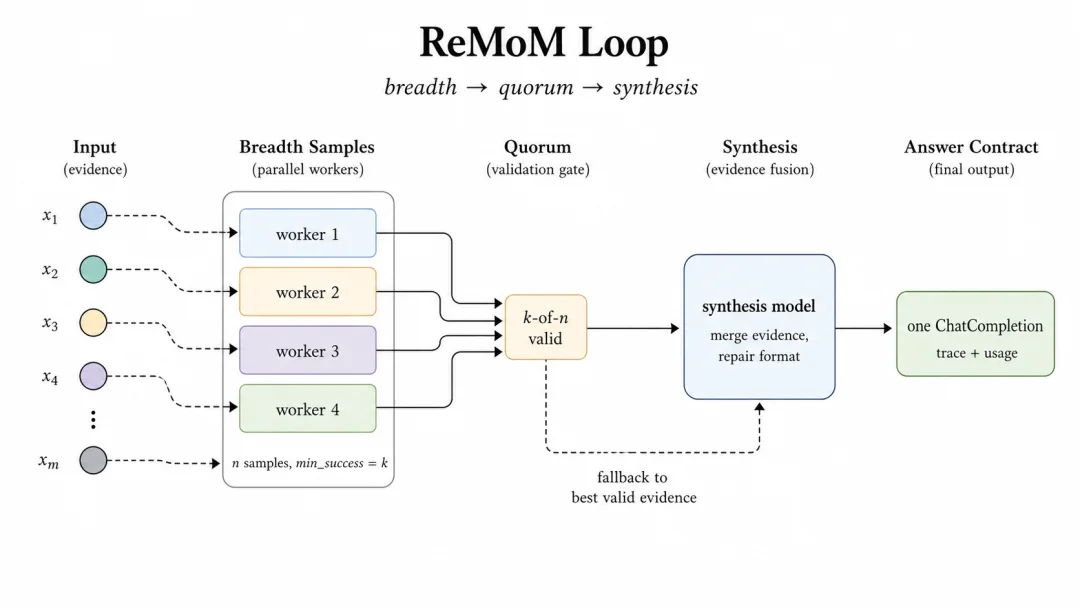
图 5:ReMoM 把 breadth、quorum、synthesis 和 fallback 都变成 serving-time controls。
Fusion:把分歧变成信号的模式
Fusion 的假设更加微妙:有时候最有价值的不是平均答案,而是分歧结构。
多个 panel answer 会被整理成证据图。哪些地方一致,哪些地方冲突,哪些回答提供了独特 insight,都会交给 judge 和 finalizer。最终用户仍然只看到一个答案,但 router 内部已经用分歧做了一次质量增强。
这类 loop 处理 hard reasoning、expert judgment、exact-answer 任务时尤其有用。因为最危险的失败不是模型犹豫,而是模型非常自信地出错。
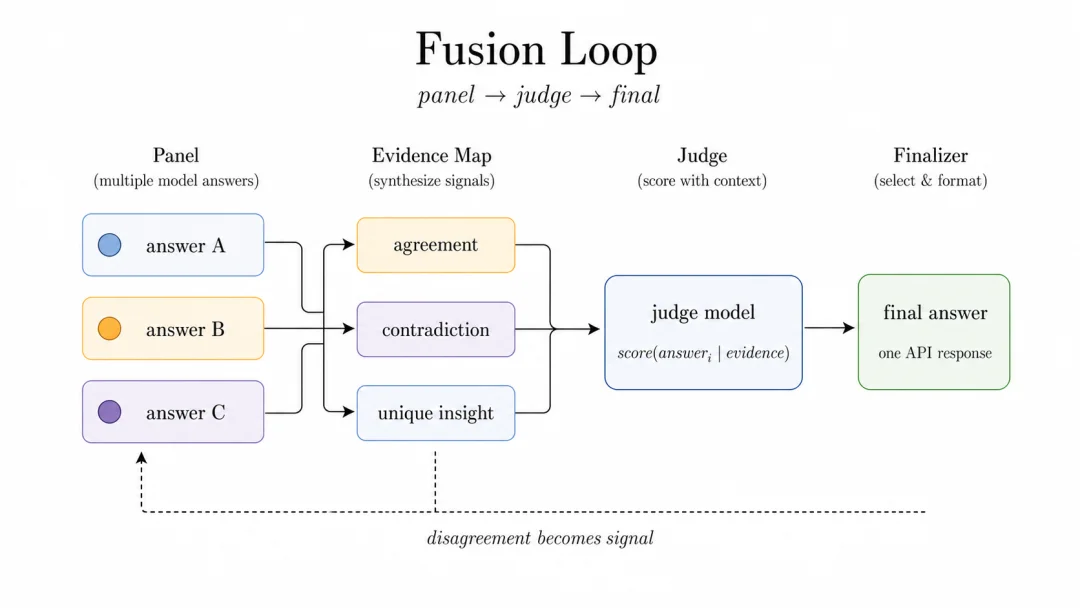
图 6:Fusion 不隐藏分歧,而是把分歧转化成证据。
Workflows:
有边界的 Micro Agent 模式
Workflows 是最接近 agent 的形态,也是最需要边界的。
planner 可以制定计划,但只能选择已经允许过的 worker models。plan 必须能能够被校验。每一步都必须有 max steps、max parallel、timeout 和 error policy。finalizer 必须把结果收敛到 output contract 里。
这意味着 router 可以表达 planner、patcher、verifier、finalizer,而不要求应用层必须自己维护一套 fragile 的 agent stack。
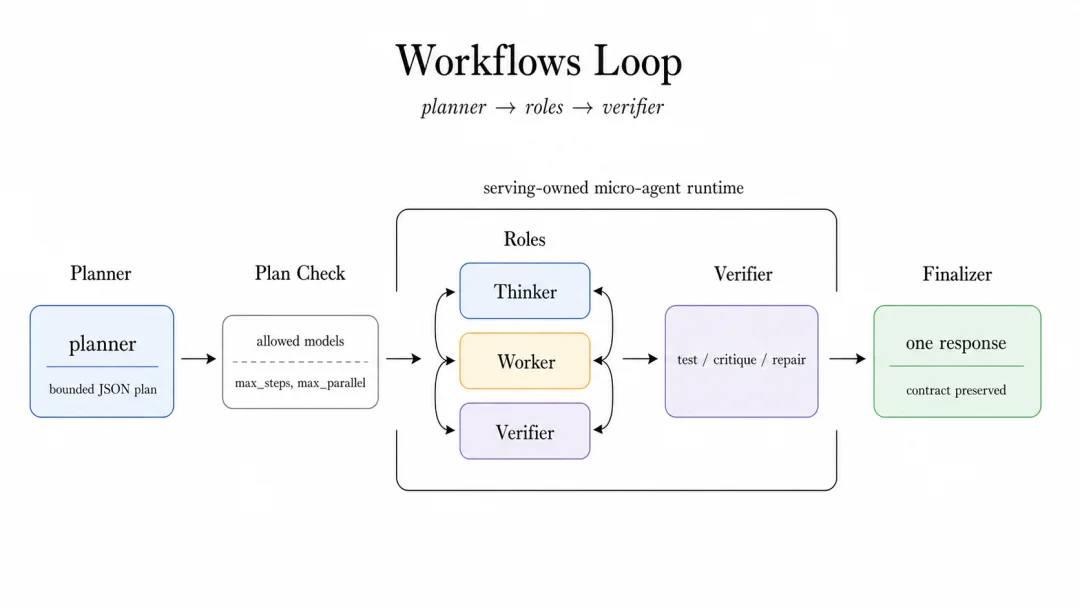
图 7:Workflows 给 router 一个受约束的角色系统,而不是一个无边界的 autonomous agent。
Auto Recipe:一个 Model Name,
多种 Loop
vllm-sr/auto 的设计,不是让用户 “永远跑最强的 loop”,而应该是:router 根据语义和上下文,选择对当前请求来说最合适的协作模式。
difficulty、risk、format pressure、latency、cost 不是 prompt 里的注释,而是 routing facts。它们可以决定这次请求应该走 Confidence、Ratings、ReMoM、Fusion、Workflows,还是 fallback path。
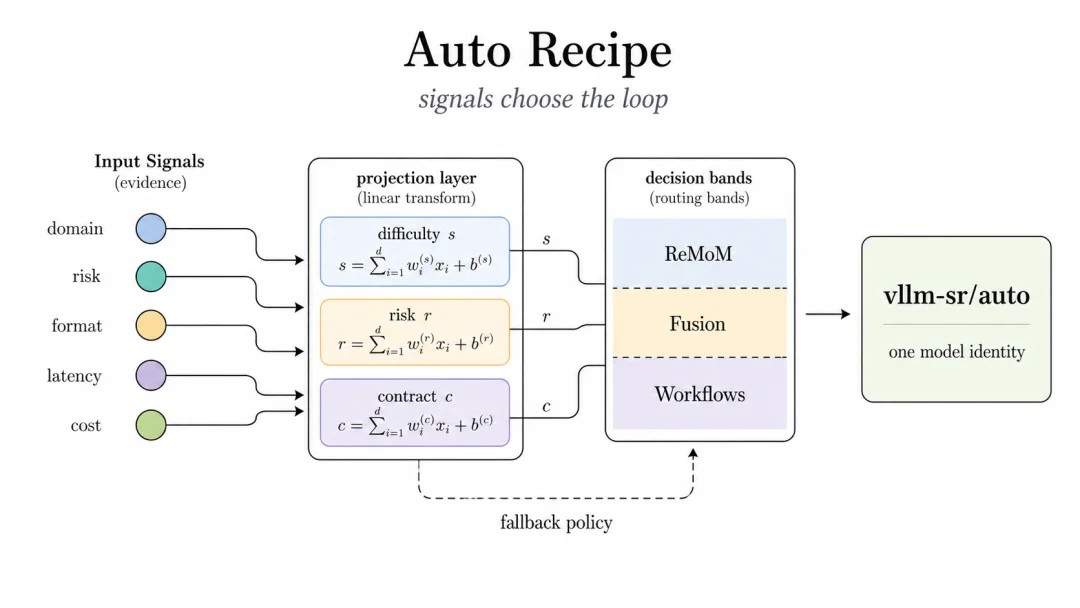
图 8:Auto Recipe 用 signals 选择 collaboration pattern,同时保持单一 model identity。
Loop 是万能的吗?
我们做 eval 后,最明确的发现是:没有一个 loop 能对对所有 benchmark 都做到最优。
而更准确的结论是:
最好的 loop 是由 task-shaped。
GPQA-Diamond 要保证有 multiple-choice contract。LiveCodeBench 要拥有 runnable code、hidden-test robustness、输入输出格式。Humanity’s Last Exam 要处理分歧、长推理和 exact answer。SWE 任务则天然就需要 planner、patcher、verifier、finalizer。
所以说 vllm-sr/auto 的真正价值并不是把所有请求都拖进昂贵协作,而是把 request shape 提前感知出来,再选择对应匹配的 recipe。
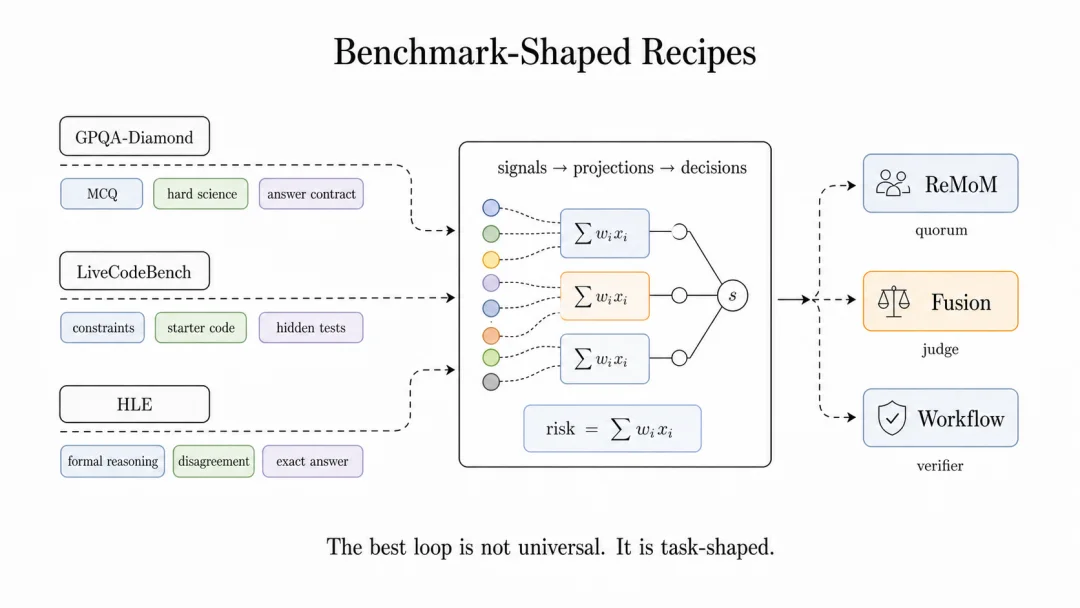
图 9:不同 benchmark 对应不同 recipe,router 用 signals 和 projections 选择合适的协作路径。
在我们的实验里,这些 shape 是显式写进路由策略的:
这就是为什么 router-side model collaboration 不只是 prompt engineering。Prompt 只是其中一层。
真正的 recipe 还包括 model pool、roles、reasoning effort、concurrency、quorum、timeout、synthesis model、fallback policy、output contract 和 observability labels。
三个实验:分数不是全部,
但足够能说明趋势方向
我们把当前 recipe 放到三个高难 benchmark 上做了实验:LiveCodeBench、GPQA-Diamond、Humanity’s Last Exam,都取得了不错的成绩:
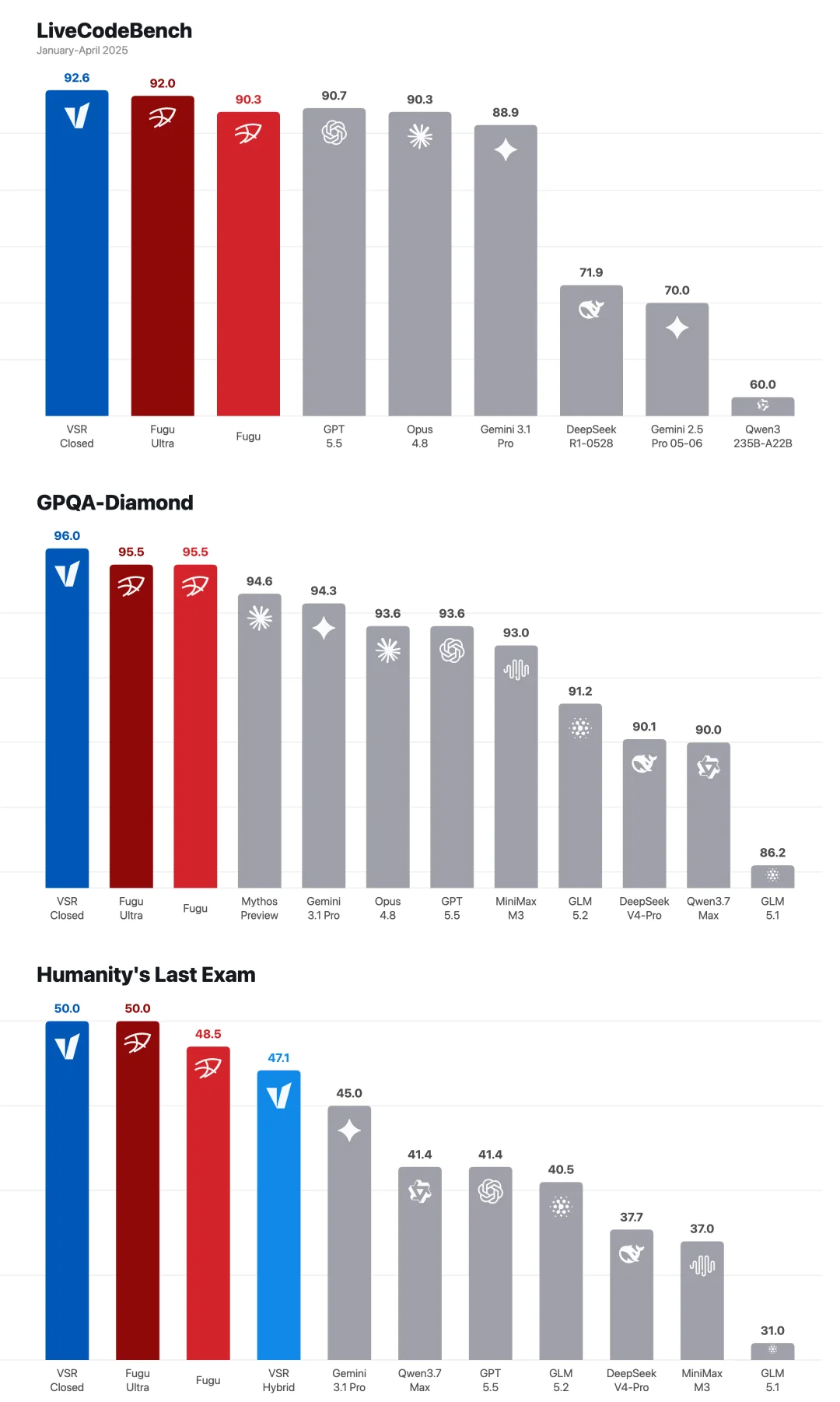
图 10:VSR Closed / VSR Hybrid 在三个 hard eval 上的 scorecard。
VSR Closed 指 recipe 全部使用闭源商业化模型。
VSR Hybrid 指 recipe 混合开源和闭源模型,并在高风险 judging、repair、synthesis 或 fallback 上使用更强的闭源模型。(在成本上相比全部闭源模型有很大的优势)
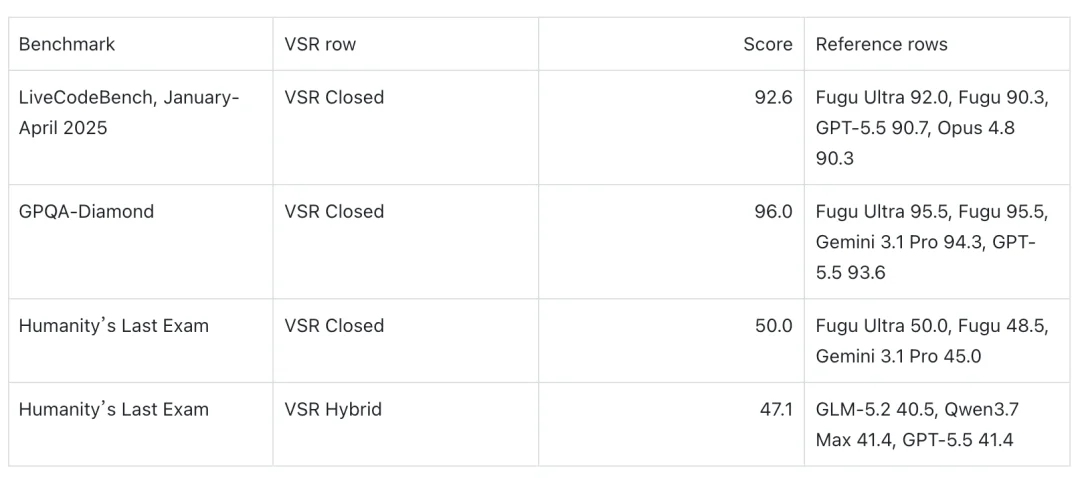
实验表明:hybrid model collaboration 可以形成一个比底层单次调用更强的统一 Mixture-of-Models。它可以接近、匹配甚至超过 SOTA 单模型的 model baseline,持平或超过了 Fugu 的商业化 Collaborative Model,同时保持一个干净的 Model API 接口。
用户看到的是一个模型名称。而系统控制着路由配方,可以在不改客户端的情况下快速接入。开源模型和闭源模型也可以在同一个 Router 的指挥下参与协作。
Model Serving 的边界正在被改变
过去的 serving stack 是被动的:收到 model name,把请求发给 backend。
下一代 serving stack 是主动的。它会问:
这不是应用 glue。这是 infrastructure。
Micro-agent 进入 router,因为 router 天然就站在 Agent 和 Model 之间,掌握着一切路由所需要的语义(Semantics)以及系统状态(KVCache、Load),担任系统的大脑去智能的路由和调度模型,最终以 OpenAI-compatible API 的兼容语义暴露出去。
作者介绍与致谢
本项目由来自 MBZUAI、McGill University、Mila 和 Agentic Intelligence Lab 的研究者共同完成,并得到了 Dr. Bowei He 和 Prof. Xue Liu 的指导与支持。Dr. Bowei He 是 MBZUAI 和 McGill University 的博士后研究员,当前主要研究方向围绕 Agentic AI。Prof. Xue Liu 是 MBZUAI 和 McGill University 的 CS 和 ML 系教授,同时也是加拿大工程院院士和 IEEE Fellow. 主要 Individual Contributors 包括来自 vLLM Semantic Router 社区的: Xunzhuo Liu、Huamin Chen、Yincheng Ren。同时也感谢 AMD 的 Andy Luo 和 Haichen Zhang 提供了 AMD GPU 硬件支持,以及高性能的 Model Serving 和 Evaluation 环境等。
下一轮模型竞赛仍然会有更强的模型出现。但它也会有更强的 router 出现:知道什么时候省钱,什么时候做安全升级,什么时候留在边端,什么时候去云端,什么时候把一次请求变成一支小而纪律严明的队伍。
这也是 vLLM Semantic Router 团队专注的方向,欢迎大家使用和参与到开源贡献中!
文章来自于微信公众号 “机器之心”,作者 “机器之心”


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
