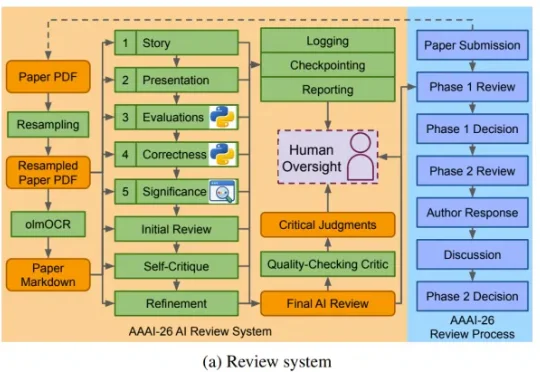
一天审完两万篇!AAAI 2026首次实装AI审稿,单篇成本不到1美元
一天审完两万篇!AAAI 2026首次实装AI审稿,单篇成本不到1美元AI 的整体表现已经胜过了人类。或者按 AAAI 官方的说法是:「对 AAAI-26 作者和程序委员会成员的大规模调查显示,参与者不仅认为 AI 评审有用,而且在技术准确性和研究建议等关键维度上,实际上更偏好 AI 评审。」
来自主题: AI技术研报
8627 点击 2026-04-19 13:33
 搜索
搜索
AI 的整体表现已经胜过了人类。或者按 AAAI 官方的说法是:「对 AAAI-26 作者和程序委员会成员的大规模调查显示,参与者不仅认为 AI 评审有用,而且在技术准确性和研究建议等关键维度上,实际上更偏好 AI 评审。」
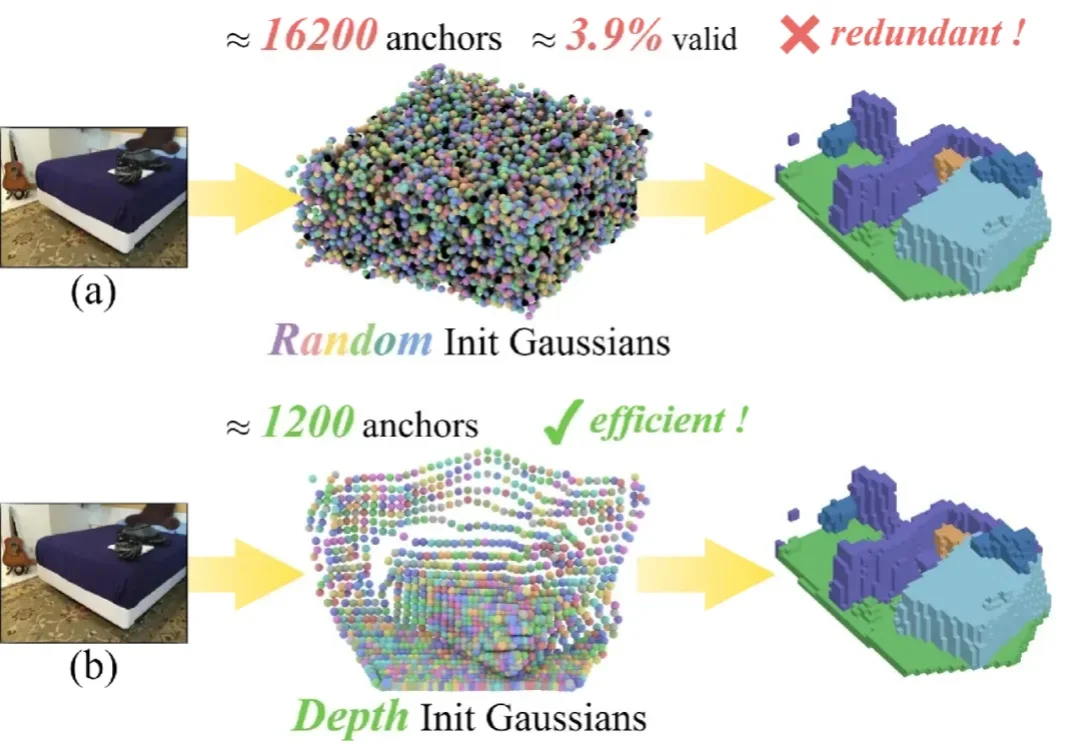
单目 3D 语义场景补全 (Semantic Scene Completion, SSC) 是具身智能与自动驾驶领域的一项核心技术,其目标是仅通过单幅图像预测出场景的密集几何结构与语义标签。
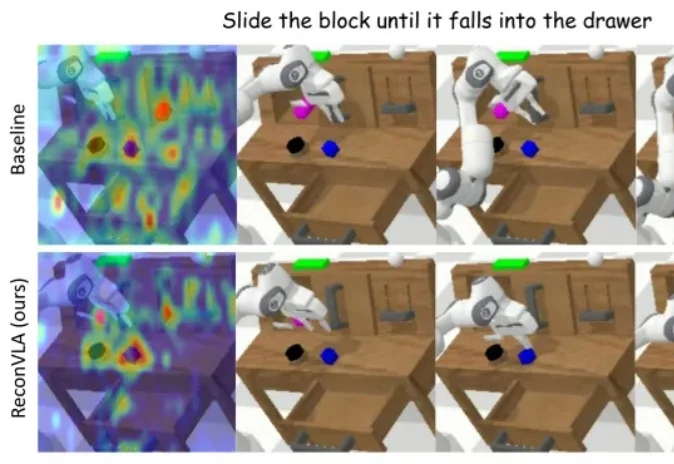
在长期以来的 AI 研究版图中,具身智能虽然在机器人操作、自动化系统与现实应用中至关重要,却常被视为「系统工程驱动」的研究方向,鲜少被认为能够在 AI 核心建模范式上产生决定性影响。

AAAI 2026「七龙珠」,华人团队强势霸榜!从视觉重建到因果发现,再到知识嵌入传承,新一代AI基石正在新加坡闪耀。

GEM框架利用认知科学原理,从少量人类偏好中提取多维认知评估,让AI在极少标注下精准理解人类思维,提高了数据效率,在医疗等专业领域表现优异,为AI与人类偏好对齐提供新思路。
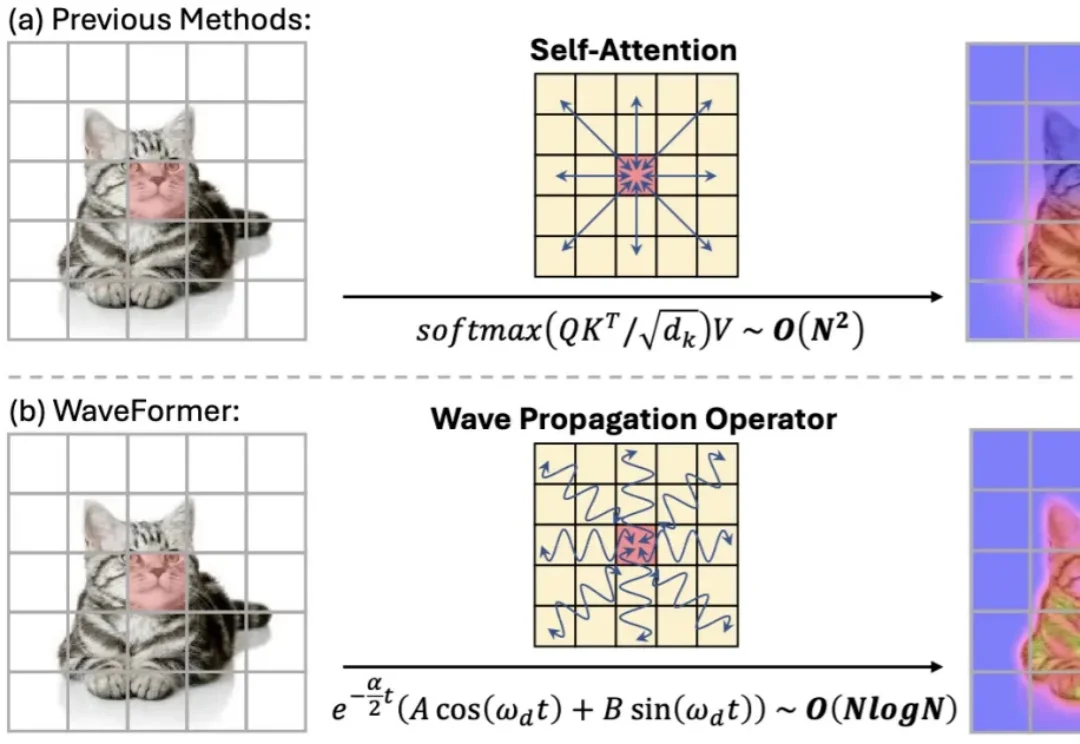
“全局交互” 几乎等同于 self-attention:每个 token 都能和所有 token 对话,效果强,但代价也直观 —— 复杂度随 token 数平方增长,分辨率一高就吃不消。现有方法大多从 “相似度匹配” 出发(attention),或从 “扩散 / 传导” 出发(热方程类方法)。但热方程本质上是一个强低通滤波器:随着传播时间增加,高频细节(边缘、纹理)会迅速消失,导致特征过平滑。
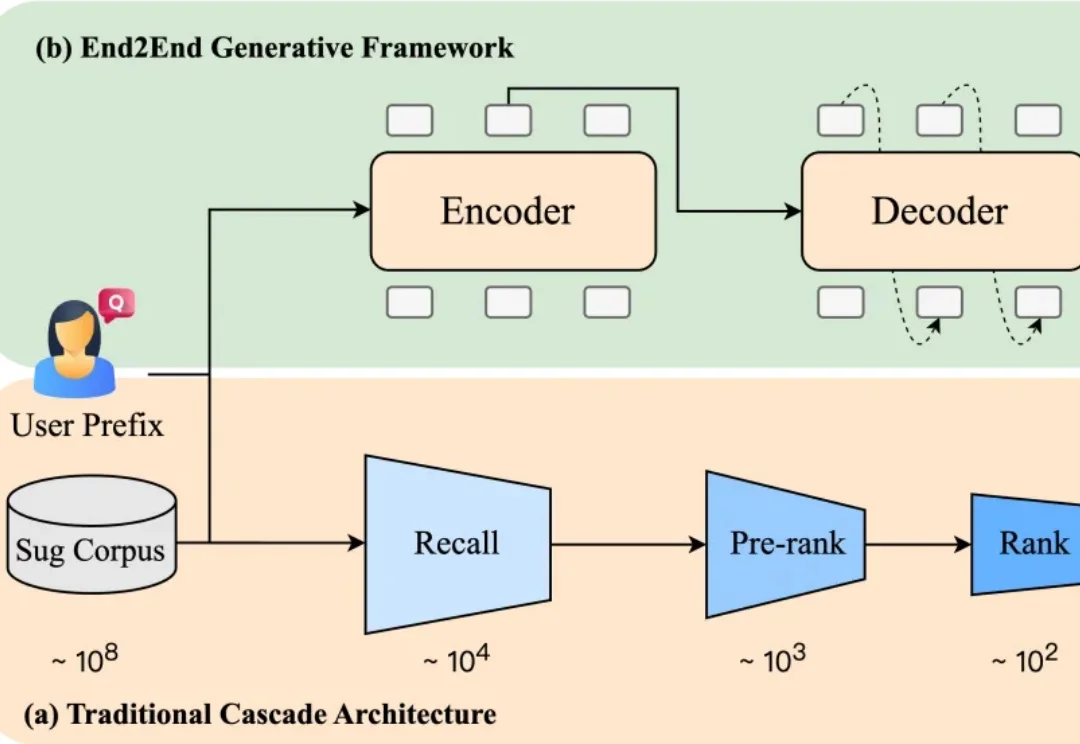
当你在电商平台搜索“苹果”,系统会推荐“水果”还是“手机”?或者直接跳到某个品牌旗舰店?短短一个词,背后承载了完全不同的购买意图。而推荐是否精准,直接影响用户的搜索体验,也影响平台的转化效率。
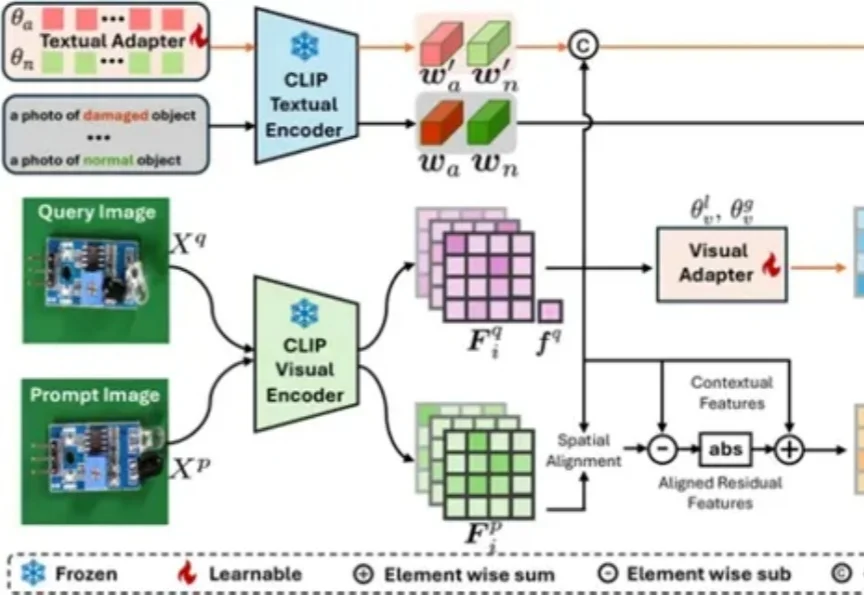
视觉模型用于工业“缺陷检测”等领域已经相对成熟,但当前普遍使用的传统模型在训练时对数据要求较高,需要大量的经过精细标注的数据才能训练出理想效果。
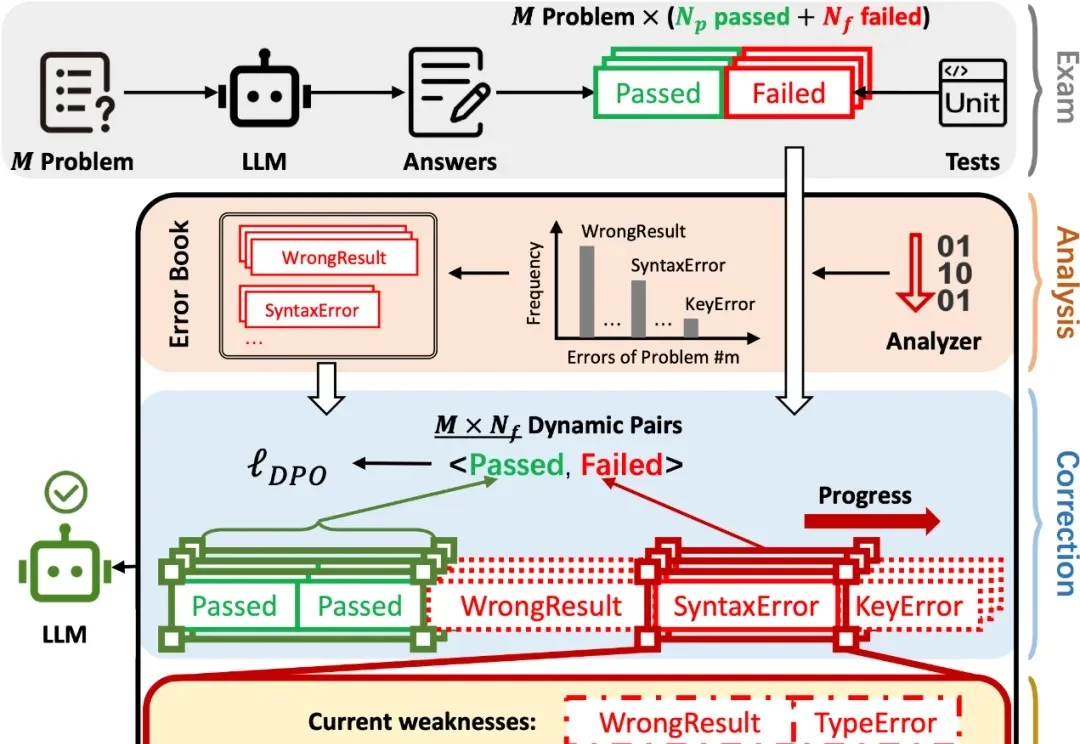
在 AI 辅助 Coding 技术快速发展的背景下,大语言模型(LLMs)虽显著提升了软件开发效率,但开源的 LLMs 生成的代码依旧存在运行时错误,增加了开发者调试成本。
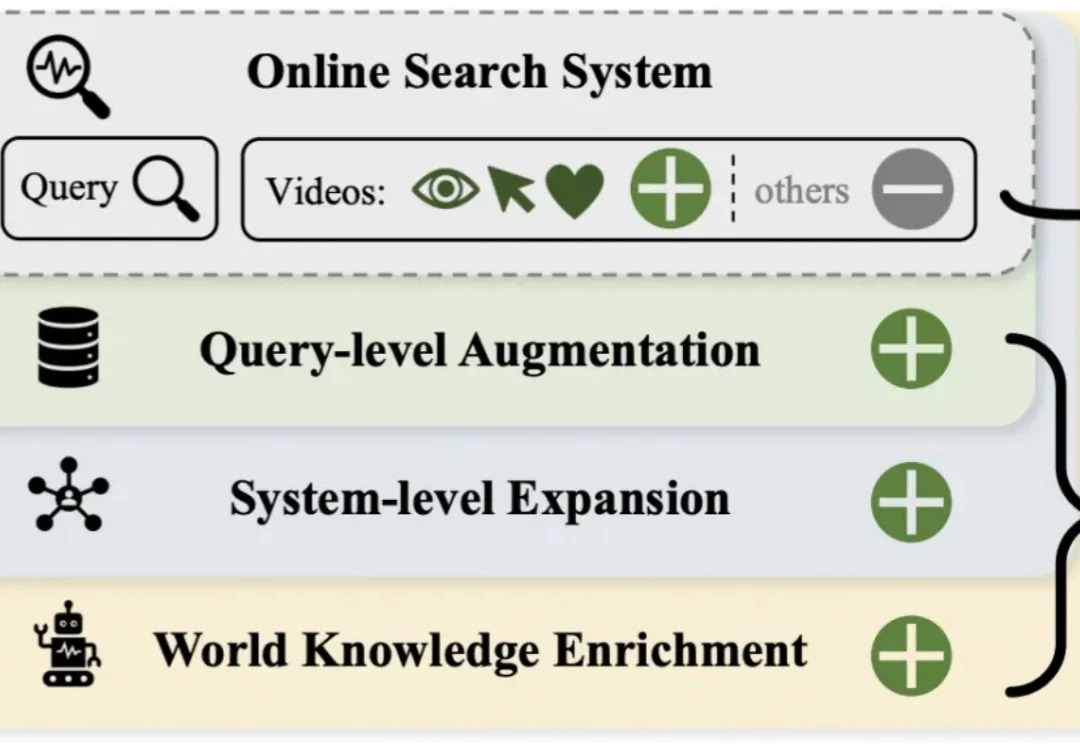
短视频搜索业务是向量检索在工业界最核心的应用场景之一。然而,当前业界普遍采用的「自强化」训练范式过度依赖历史点击数据,导致系统陷入信息茧房,难以召回潜在相关的新鲜内容。