
AAAI 2026结果公布,刷出88887高分!2.3万投稿录用率仅17.6%
AAAI 2026结果公布,刷出88887高分!2.3万投稿录用率仅17.6%AAAI 2026录用结果重磅公布!这一届,投稿量暴增至23,680篇,录用率仅17.6%,竞争程度远超往年。一些成功上岸的研究员们晒出了录用成绩单,有人甚至拿下了88887高分。
来自主题: AI技术研报
8009 点击 2025-11-10 14:33
 搜索
搜索
AAAI 2026录用结果重磅公布!这一届,投稿量暴增至23,680篇,录用率仅17.6%,竞争程度远超往年。一些成功上岸的研究员们晒出了录用成绩单,有人甚至拿下了88887高分。
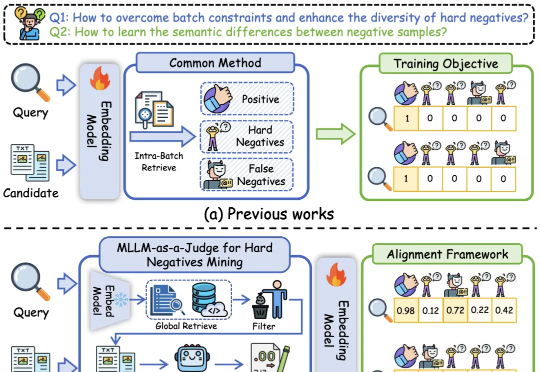
基于多模态大模型语义理解能力的统一多模态嵌入模型UniME-V2。该方法首先通过全局检索构建潜在困难负例集,随后创新性地引入“MLLM-as-a-Judge”机制:利用MLLM对查询-候选对进行语义对齐评估,生成软语义匹配分数。
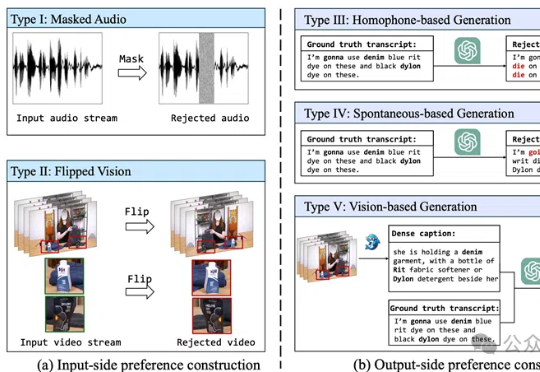
视觉+语音=更强的语音识别!BPO-AVASR通过优化音视频输入和输出偏好,提升语音识别在真实场景中的准确性,解决了传统方法在噪声、口语化和视觉信息利用不足的问题。
大模型的快速及持续发展,离不开对模型所有权及数据隐私的保护。

哈尔滨工业大学团队提出HEROS-GAN技术,通过生成式深度学习将低成本加速度计信号转化为高精度信号,突破其精度与量程瓶颈。该技术利用最优传输监督和拉普拉斯能量调制,使0.5美元的传感器达到200美元高端设备的性能,为工业、医疗等领域应用带来变革。

精准预测和设计蛋白质的序列、结构及模拟其动态变化,一直是科学界的重大挑战。

一年一度的AAAI Fellow计划又成为了人工智能领域大家关注的焦点。本次发布的2025年名单中,共有16位知名学者当选,其中包含了四位著名华人学者。
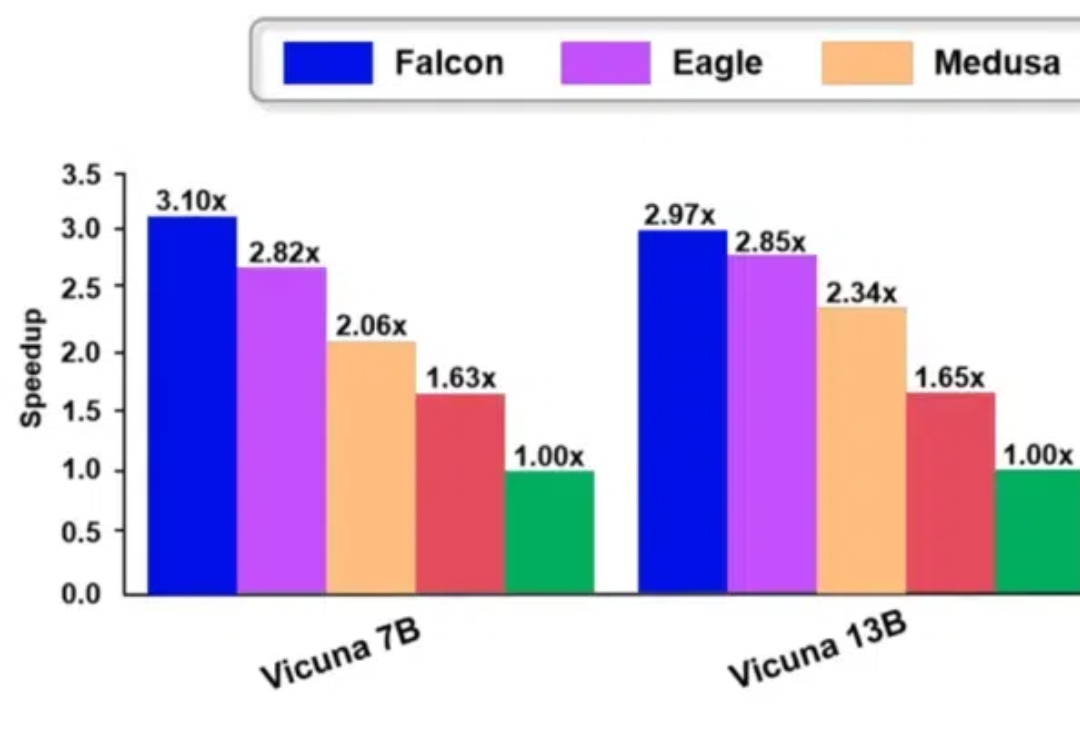
Falcon 方法是一种增强半自回归投机解码框架,旨在增强 draft model 的并行性和输出质量,以有效提升大模型的推理速度。Falcon 可以实现约 2.91-3.51 倍的加速比,在多种数据集上获得了很好的结果,并已应用到翼支付多个实际业务中。
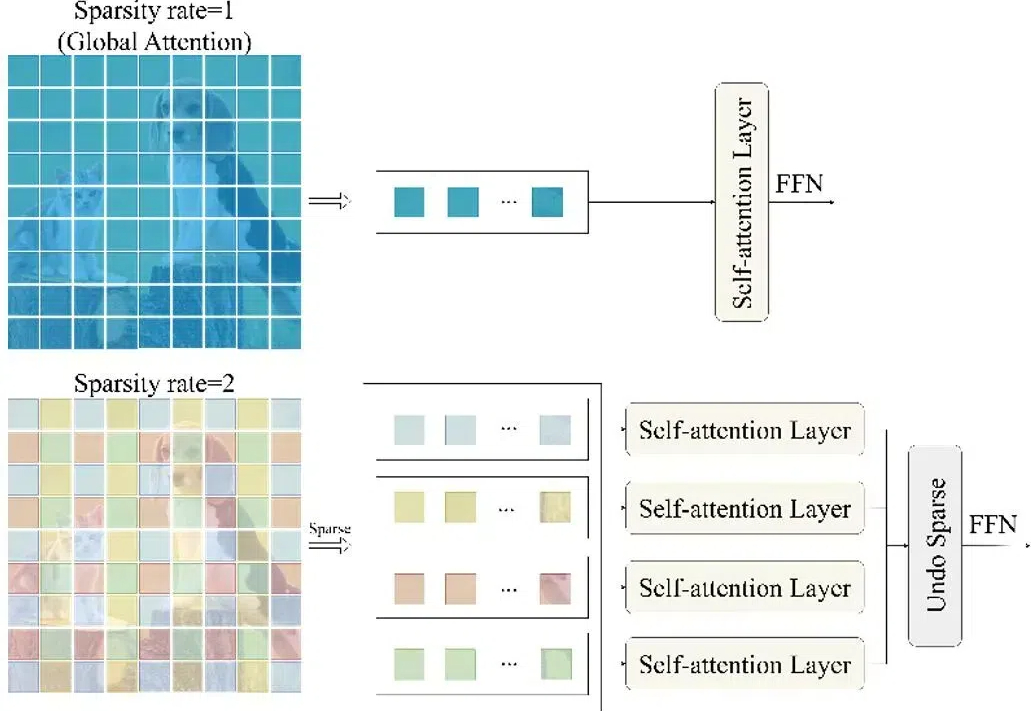
随着图像编辑工具和图像生成技术的快速发展,图像处理变得非常方便。然而图像在经过处理后不可避免的会留下伪影(操作痕迹),这些伪影可分为语义和非语义特征。
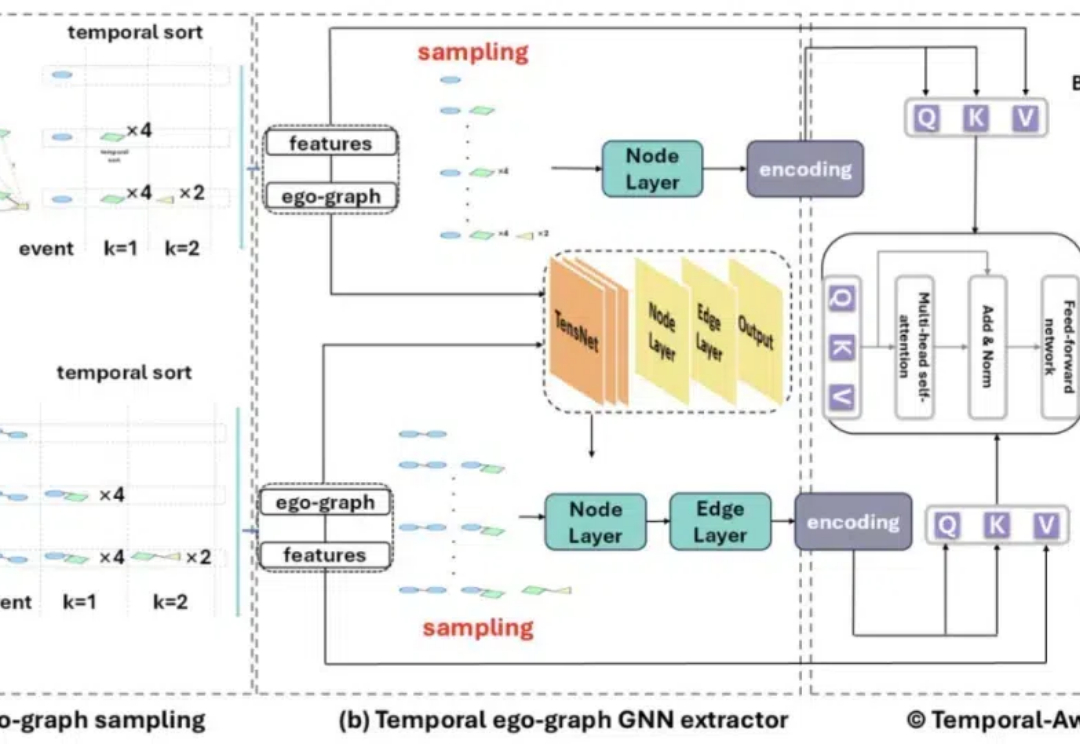
此项研究成果已被 AAAI 2025 录用。该论文的第一作者是南洋理工大学计算与数据科学学院 (CCDS) 的硕士生杨潇,师从苗春燕教授,主要研究方向是图神经网络。