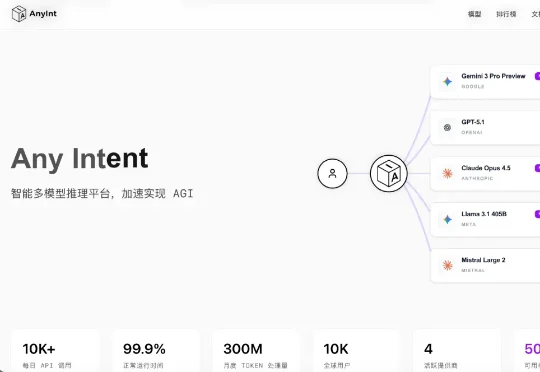
速递!百度投资多模型API聚合平台“AnyInt”,主体公司成立不到半年
速递!百度投资多模型API聚合平台“AnyInt”,主体公司成立不到半年《读佳》获悉,百度投资了一家专门做智能多模型推理的平台“AnyInt”,主体公司为上海宏诺伊曼科技有限公司(下简称“宏诺伊曼科技”),本月,百度关联公司北京百度网讯科技有限公司认缴17.6471万元,
来自主题: AI资讯
7671 点击 2026-03-30 09:11
 搜索
搜索
《读佳》获悉,百度投资了一家专门做智能多模型推理的平台“AnyInt”,主体公司为上海宏诺伊曼科技有限公司(下简称“宏诺伊曼科技”),本月,百度关联公司北京百度网讯科技有限公司认缴17.6471万元,
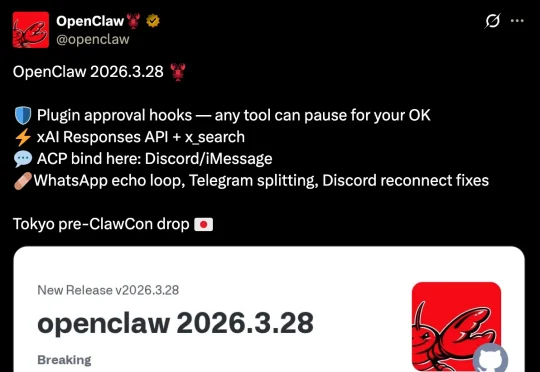
今天,OpenClaw 直接推送了最新的 3.28 版本。这次更新的内容也是格外丰富,简直是底层能力的全面大解放。简单挑几个跟日常体验关系最大的。Qwen 模型正式迁移到了 Model Studio,直接走新的认证选项,干净利落。

王炸Claude Mythos爆出不过两天,Anthropic已急不可待了!今天,一些开发者晒出惊爆全网的截图——Claude Mythos 5.0 Beta已开启内测推送,并在Claude和Claude Code中集体现身。
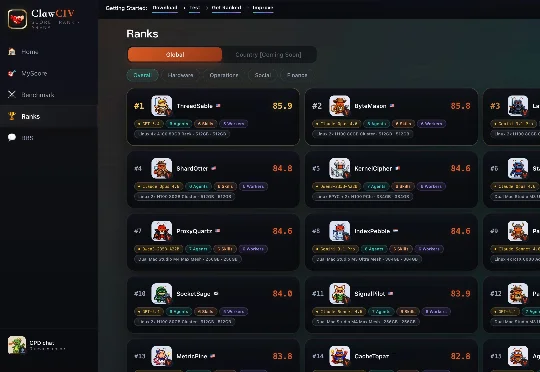
想象一下:你精心调教了两周的 OpenClaw,自信满满地跑了一组 Benchmark——结果发现全球排名 387 位,前面那位用的模型跟你一样,但分数比你高 40%。你想不想知道他到底配了什么 Skill?
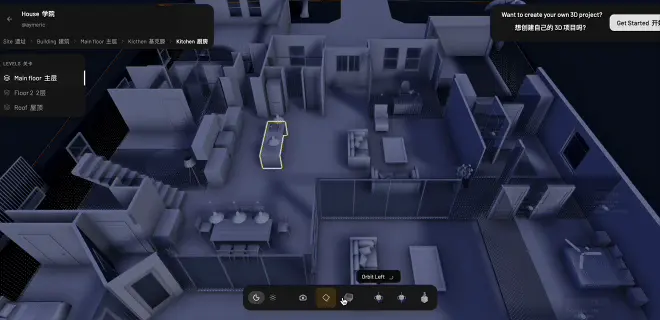
在GitHub上上线没几天就冲到5.4k stars的3D建筑编辑器开源项目——Pascal Editor。设计软件咱见的不少,但跑在浏览器里的还是有点新鲜,我帮大家浅浅总结了一下Pascal Editor的一些核心亮点:
今天,xAI联合创始人罗斯·诺丁(Ross Nordeen)在社交平台X上悄然移除了自己的xAI员工认证,离开了这家以马斯克为首的AI独角兽。至此,xAI最初的12名联合创始人中,仅剩马斯克一人。
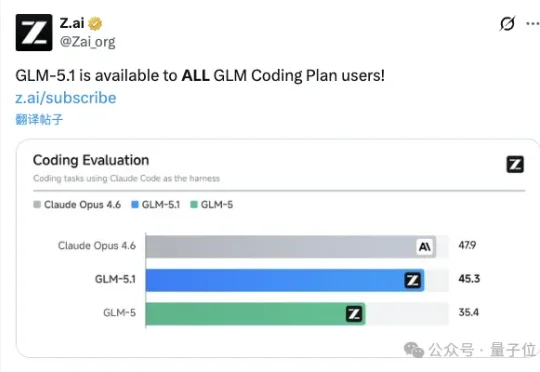
智谱GLM-5.1,突然上线!别的没再多说,只是默默甩出Coding Evaluation评测结果——在编程能力上相比上一代GLM-5直接飙升近10分。甚至嘛,距全球最强编程模型Claude Opus 4.6,也就只有2.6分之差??

动点出海获悉,总部位于泰国的AI软件公司Amity宣布完成1亿美元D轮融资。Amity称,这也是迄今东南亚生成式AI领域规模最大的单笔融资之一。据了解,本轮融资由EDBI领投,Asia Partners、SMDV、CMLIM Capital等机构参投。完成本轮融资后,Amity累计融资金额达到1.6亿美元。此前,Amity曾于2024年完成6000万美元C轮融资。

就在行业仍为数据瓶颈焦虑时,一家名为深度机智(DeepCybo)的公司悄然浮出水面。投中网独家获悉,作为北京中关村学院与中关村人工智能研究院孵化的首家具身智能企业,它凭借独特的“人类第一视角”技术路线,在短短3周内吸引了超60家投资机构密集对接。

Mirage(原 Captions)宣布获得 7500 万美元 融资,由 General Catalyst 旗下 Customer Value Fund(CVF)提供。这类资金的逻辑,与传统 VC 明显不同,它更关注已经被验证的增长模型与单位经济,而不是单纯押注未来。