
2天手搓商业级App!开源GLM-5.2+Image2太绝了~【附教程】
2天手搓商业级App!开源GLM-5.2+Image2太绝了~【附教程】大家好,我是袋鼠帝。 如果你家的猫狗真的能说话,它们开口第一句会说什么?
来自主题: AI技术研报
9783 点击 2026-06-18 15:29
 搜索
搜索
大家好,我是袋鼠帝。 如果你家的猫狗真的能说话,它们开口第一句会说什么?

刚刚,Google 甩出了 Gemini 3.5 Live Translate。这是它最新的语音对语音翻译模型,一句话概括:把「等你说完再翻」的老规矩,直接掀了。Google DeepMind 首席科学家 Jeff Dean 亲自发帖官宣,字里行间透着一股「二十年磨一剑」的底气:

哪个铲屎官不想在自己的小猫小狗发出声音时,听懂它到底想说什么;或者是让它们听懂人类的语言。 杭州一家名为「萌小译」的公司最近推出了一款产品,800 块就能实现我们和宠物之间的双向翻译,并且准确率达到了

今年 4 月,一款名为 PettiChat的“宠物AI翻译器”在Kickstarter 众筹及独立站一经面市,便获得国内外众多关注。 外表看,这是一款重量仅27.2克、可夹在项圈或背带上的轻量化智能设
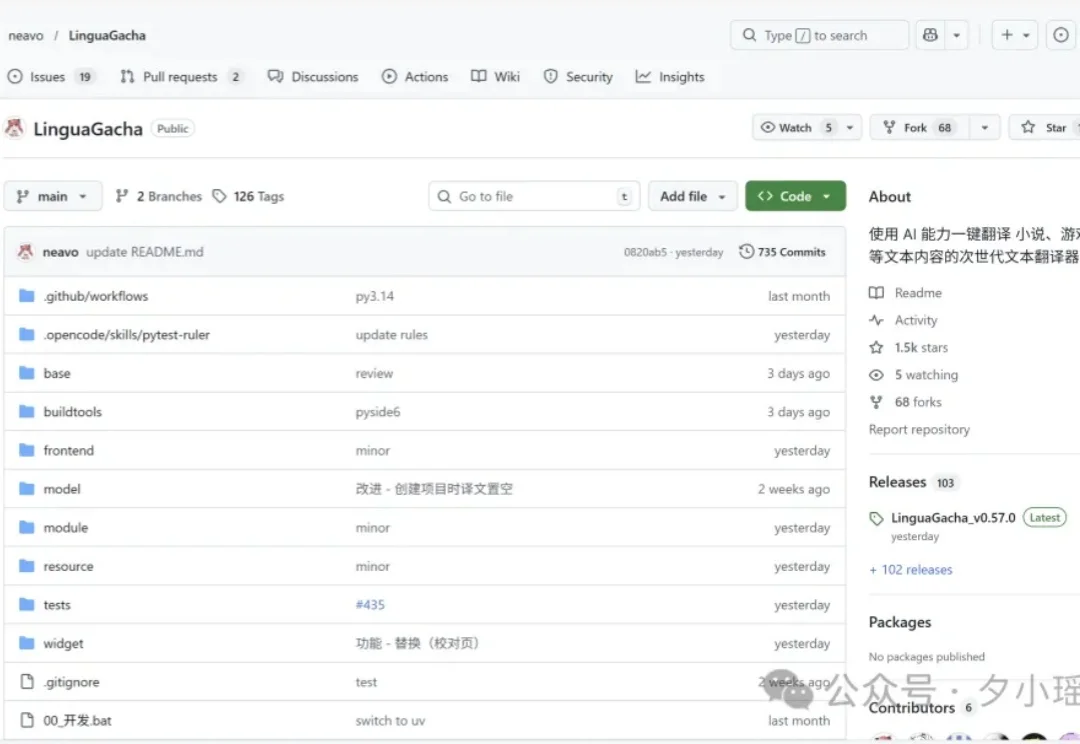
前两天有个朋友问我最近在忙什么。

DiscoX构建了一套200题的长文翻译数据集,以平均长度1,712 tokens的长篇章做评测单元,要求整个长文文本作为一个整体来翻译,除翻译准确度外,重点考察跨段落的逻辑与风格一致性、上下文中的术语精确性、以及专业写作规范,贴合用户真实的使用场景。

OpenAI悄悄发布了翻译产品ChatGPT Translate,谷歌则祭出强势回应——TranslateGemma,一个能在手机上翻55种语言的开源模型。
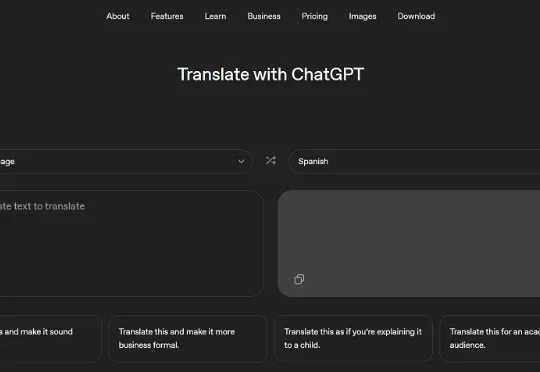
今天,OpenAI在ChatGPT网页端悄悄推出了独立的翻译功能——ChatGPT Translate。乍一看,它与谷歌翻译等传统翻译工具颇为类似。真正将二者区分开来的,可能是翻译后ChatGPT Translate提供的交互与个性化调整能力。

在 2026 年的 CES 全球消费电子展上,AI 硬件无疑是不可忽视的一支—— 小至能根据指令作画的 AI 画框,大到能叠衣服的家务机器人......AI 已经无处不在。
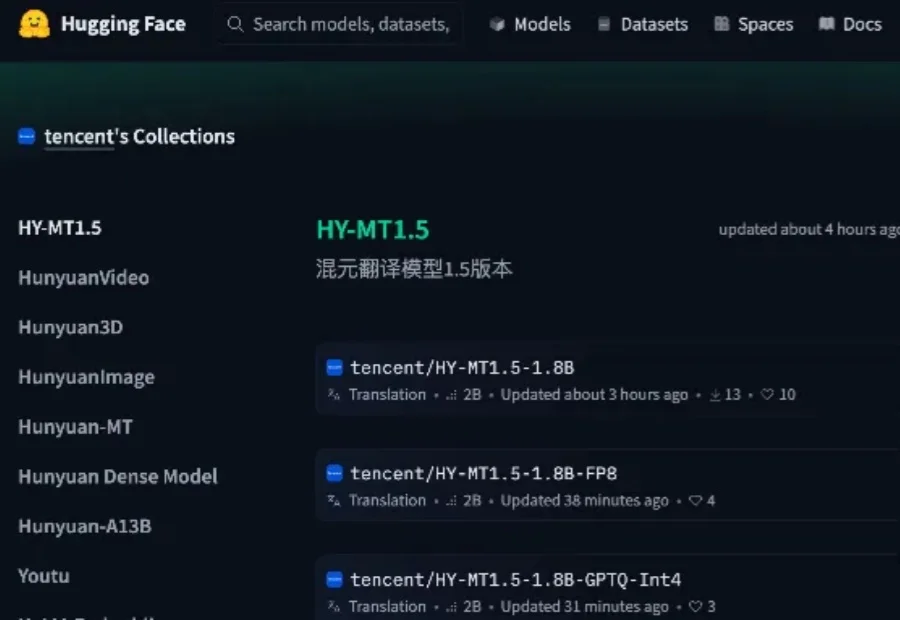
能翻译33语种+5方言,医学术语/粤语翻译实测“能打”。