
藏师傅开发的 Codepilot 保姆级入门攻略
藏师傅开发的 Codepilot 保姆级入门攻略Codepilot 是藏师傅从今年一月开始纯 Vibe Coding 写个一个全平台通用开源 Agent 客户端。截止目前已经迭代了几百个版本,github 的 Star 也来到了 5100. 支持你能想到的小龙虾和 ClaudeCode 等 Agent 所有的能力,比如:
来自主题: AI资讯
8464 点击 2026-04-10 15:48
Codepilot 是藏师傅从今年一月开始纯 Vibe Coding 写个一个全平台通用开源 Agent 客户端。截止目前已经迭代了几百个版本,github 的 Star 也来到了 5100. 支持你能想到的小龙虾和 ClaudeCode 等 Agent 所有的能力,比如:
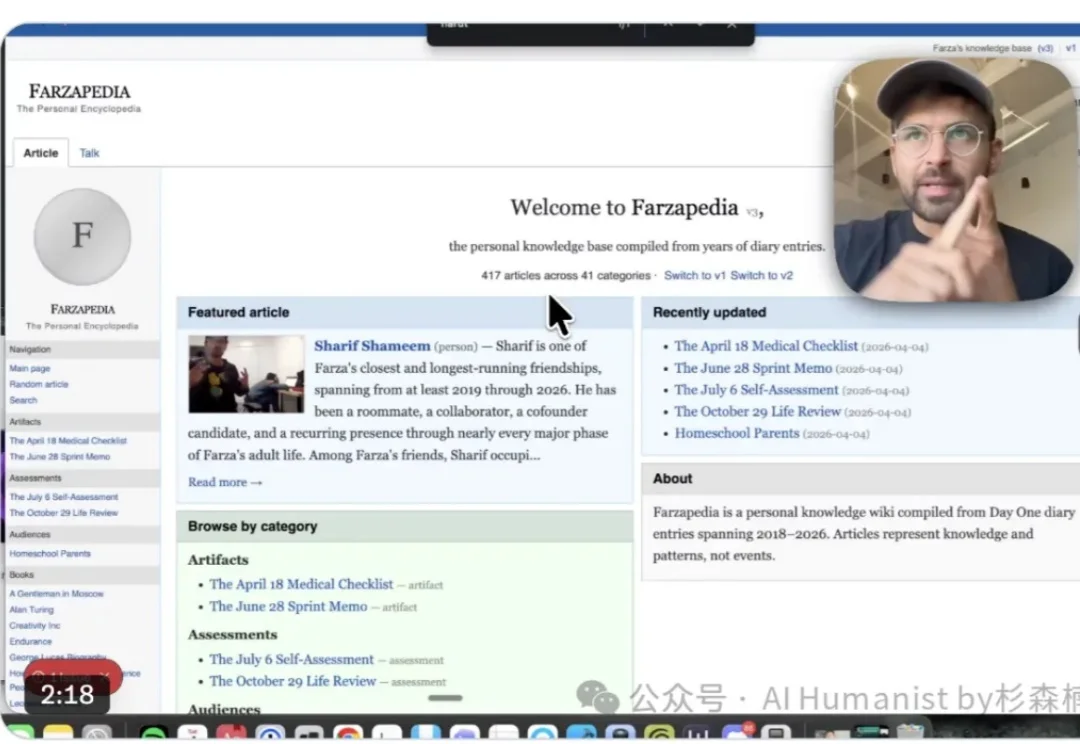
前天刷 X,刷到一个叫 Farza 的老哥,做了件牛 X 的事。

在这篇文章里,我想介绍编码智能体(Coding agents)以及 Agent harnesses 的整体设计:它们是什么、怎么运作,以及各个零件在实践中怎么拼到一起。

过去两年,图像生成模型在质感和审美上一路狂飙,但大多仍是 “直接出图” 的范式。
李飞飞的 World Labs 又更新模型了。
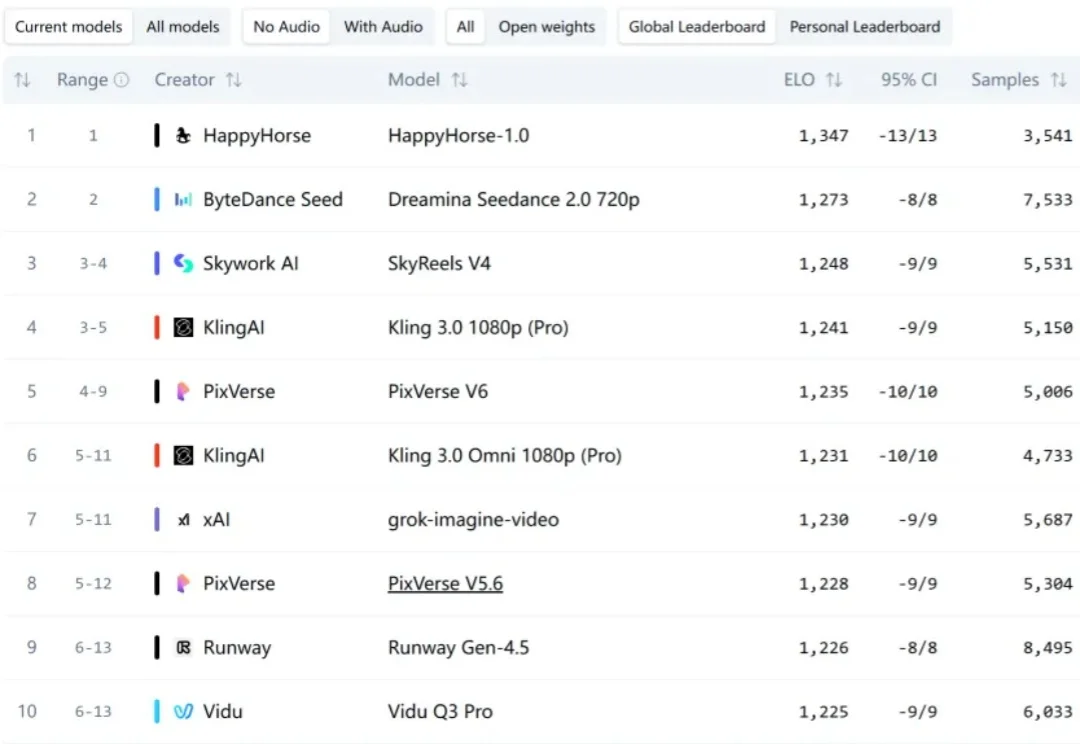
就在 OpenAI 都停了 Sora,所有人以为 Seedance 2.0 要一统天下的时候,没想到不知哪里冒出来一匹马。
「用一句话交代任务,然后什么都不用管,AI 自动执行。」这或许是大家最初对「AI 超级助手」的想象。

MSL交出首张答卷。
Anthropic推出平台级产品:Claude Managed Agents,开发周期从数月压缩到几天,To B业务更进一步,这是直接给了一个Harness Agent的盒子,用户只管干活就行了,随着产品发布,A厂还发布了一篇Harness(Managed Agents)工程细节文章,感觉A厂就差说在座的都是xx了,再一次遥遥领先!我们一文来说清楚

国产AI营销持续刷屏行业!原本2周策划,现在十几分钟落地,从内容爆款到精准投放全流程智能搞定。营销人别再拍脑袋,再不跟上这个浪潮,669亿AI营销市场真没你份了。