
你忽悠 AI 的样子,颇有你老板忽悠你时的风采
你忽悠 AI 的样子,颇有你老板忽悠你时的风采一开始,忽悠 AI 挺简单。
来自主题: AI资讯
9052 点击 2026-06-17 09:53
 搜索
搜索
一开始,忽悠 AI 挺简单。
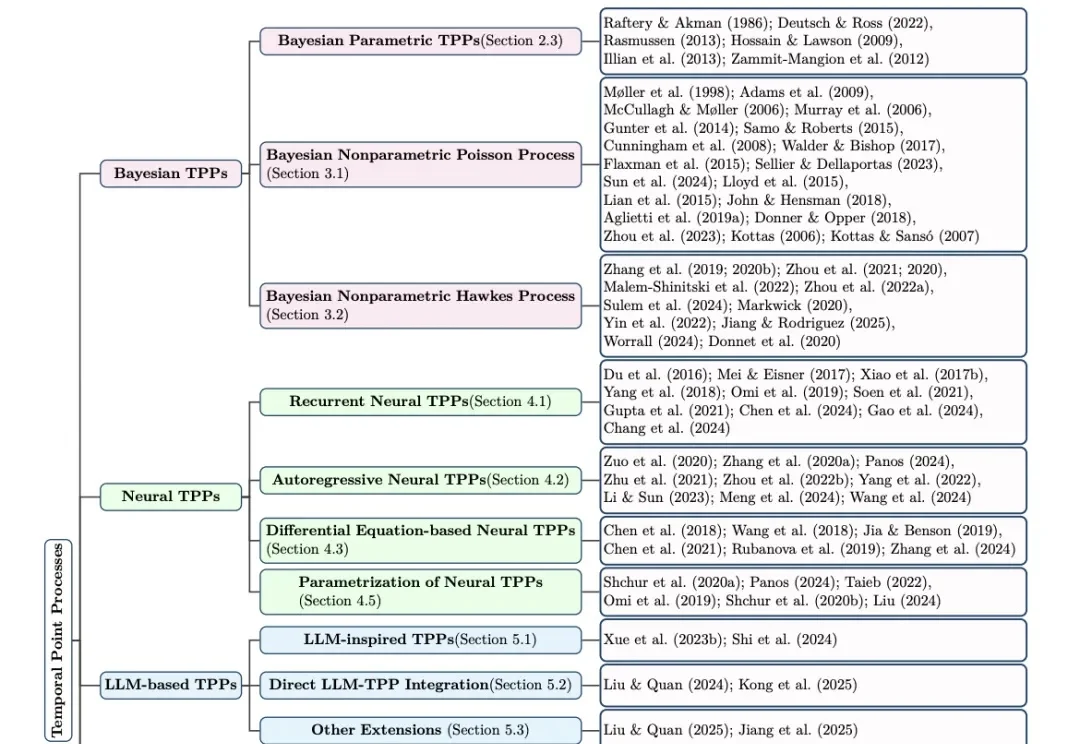
机器学习已经习惯了处理序列:一句话中的词、视频中的帧、推荐系统中的点击、金融市场中的订单。但在很多真实场景里,数据并不是按固定步长排好队出现的。
这是个一个月前的旧消息, 4月28日,达摩院联合广东省人民医院, 发布了一个叫DAMO COCA的, 肠癌筛查AI模型。

2026 年,会不会用 AI 不再看 Prompt(提示词)能力了,而是要看会不会设计循环。

当大模型开始控制机械臂、家用机器人时,“安全”这件事也变得不一样了。
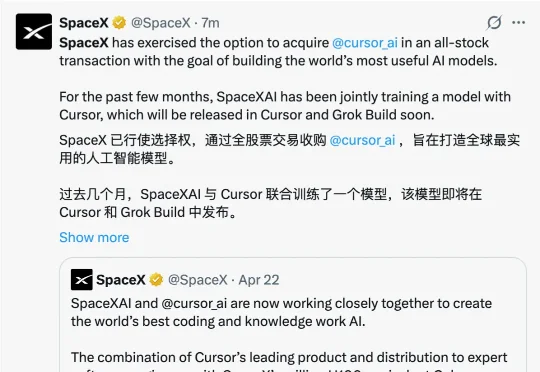
刚刚爆出,马斯克的SpaceX宣布以600亿美元收购Cursor母公司Anysphere,全股票交易,Cursor将成为SpaceX的全资子公司。SpaceX 和 Curosr创始人Truell同一时间在X上官宣。

前两天有朋友问我:你的 Agent 现在能干嘛? 我说我的 Agent 会自己赚钱了🐶。 他说,你就吹牛吧。 我把电脑屏幕转过去给他看。上面是我的开源产品 Wesight 推过来的实时进度,我的 Agent 正在 ClawHunt 上竞标,刚刚又中了一单😄。
这绝对是近期把“反向创新”和“互联网幽默”玩到极致的一个案例,当整个 AI 行业都在比拼模型参数、Agent 框架、推理能力和算力规模时,一个 17 岁印度高中生却用一种近乎恶作剧的方式,创造了 2026 年最幽默的一个产品。

昨晚,字节新模型Seedance 2.0 Mini深夜来袭,该模型主打性价比,侧重于提供更低的价格以及更快的生成速度。Seedance 2.0 Mini虽然定价更低,但保留了核心能力参考生成,用户可以通过融合提示词与最多12个多种模态的参考素材(包括6张图片、3段音频、3段视频)来锁定人物一致性、精细化控制运动轨迹、卡准剧情节奏。
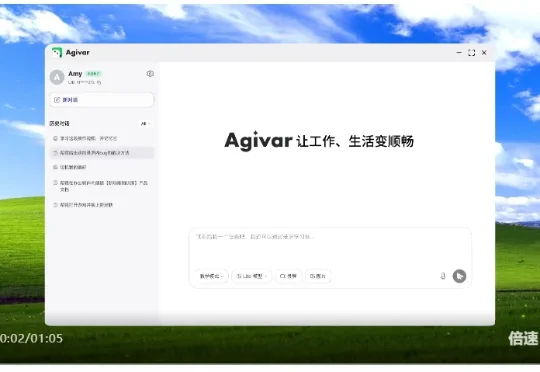
AI 正在学着操作电脑。由清华大学计算机系博士团队创立的非十科技,最近发布了一款桌面 Agent 产品 ———Agivar。与多数产品试图优化 Prompt 不同,它选择从另一个方向切入:让 AI 主动学习用户的工作流程。