
刚刚,OpenAI把Transformer作者挖走了
刚刚,OpenAI把Transformer作者挖走了AI 圈又迎来一次标志性的人才流动。就在刚刚,Transformer 论文作者之一,知名 AI 研究员 Noam Shazeer 在 社交媒体发文宣布,他将正式加入 OpenAI。
来自主题: AI资讯
10155 点击 2026-06-18 10:40
 搜索
搜索
AI 圈又迎来一次标志性的人才流动。就在刚刚,Transformer 论文作者之一,知名 AI 研究员 Noam Shazeer 在 社交媒体发文宣布,他将正式加入 OpenAI。

刚刚,国内 AI 应用层最大的一笔融资落定了,但你很可能并没有听过这家公司的名字——演语。演语科技,英文名 Evoken。这是它第一次用集团品牌的身份对外发声。在此之前,外界更熟悉的,是它旗下的 LiblibAI。
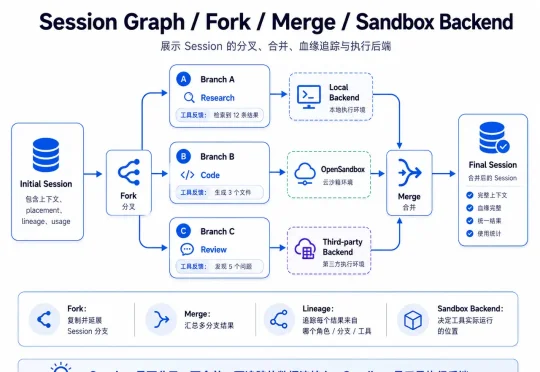
最近,一个来自清华大学与中山大学的团队(Rath Team)把他们的解法开源了,叫OpenRath:这是一个像PyTorch的多智能体、多会话运行时。它的主张是:别再围着Agent转了。真正该被当成一等公民的,是Session。

Salesforce 公司已同意以约 36 亿美元收购 Fin——一家开发人工智能驱动型顾客服务代理的公司,这家软件企业正致力于为企业级 AI 赢得新业务。Fin 的旗舰产品 AI Agent 可通过聊天、电子邮件、WhatsApp、短信、短信、电话和 Slack 处理顾客查询。
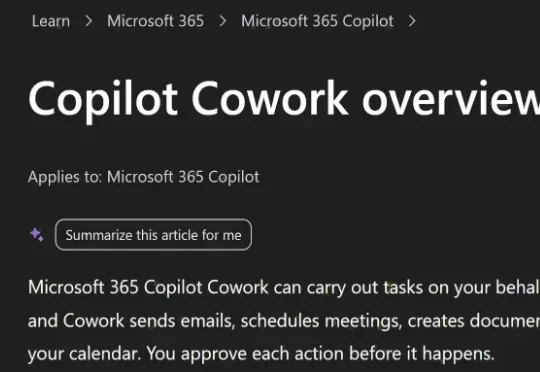
当地时间6月16日,微软宣布将企业AI工具Copilot Cowork转向按使用量计费。另据外媒Axios报道,在扩大该工具访问范围的同时,Copilot Cowork近期考虑引入由微软托管的DeepSeek模型,作为更低成本的模型选项。

跑通 C 端后,Plaud 开始新探索。

2026年,飞书新增客户中有九成同时采购飞书AI产品。

今日,SENASIC琻捷(6675.HK)正式登陆港交所,成为港股市场首家聚焦Physical AI端侧感算芯片赛道的上市公司。上市首日,SENASIC琻捷高开72.11%报31.6港元,市值逼近120亿港元。

新一代具身基础模型G0.5和首款双足人形机器人Kengo亮相不到半个月,星海图又整活儿了。
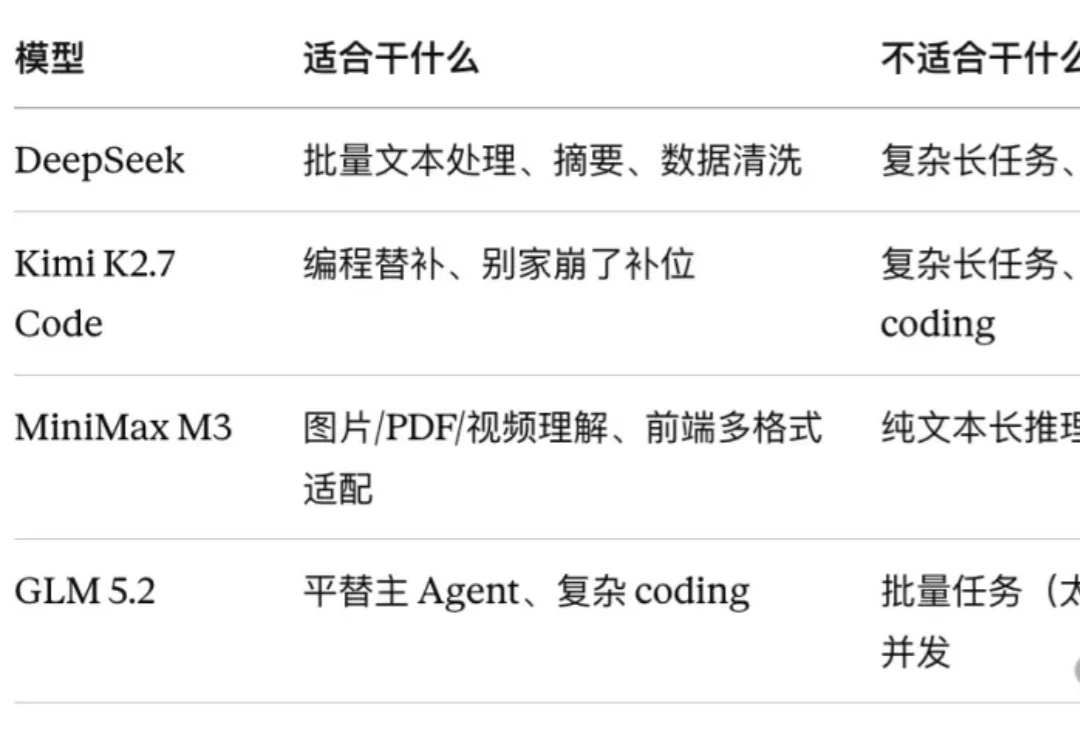
最近,Kimi 2.7 Code 和 GLM 5.2 接连发布,一周双发,国产模型又崛起了。