
聊聊Anthropic这篇最新研究,我觉得可能是AI意识诞生的前夜。
聊聊Anthropic这篇最新研究,我觉得可能是AI意识诞生的前夜。今天凌晨刷到Anthropic发了一篇研究。标题叫《A Global Workspace in Language Models》,语言模型中的全局工作空间。如果用一句最简单的话来说,那就是,Anthropic在Claude的大脑里,找到了一个暗房间。
来自主题: AI技术研报
9269 点击 2026-07-07 09:42
 搜索
搜索
今天凌晨刷到Anthropic发了一篇研究。标题叫《A Global Workspace in Language Models》,语言模型中的全局工作空间。如果用一句最简单的话来说,那就是,Anthropic在Claude的大脑里,找到了一个暗房间。
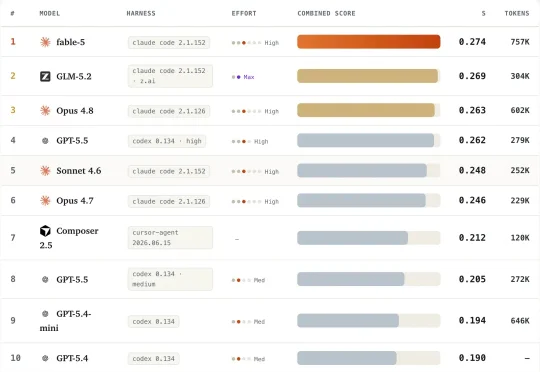
为了解决这一问题,来自 University of Arizona、Zoom 与 Stony Brook University 的研究团队推出了 VISTA(VIsual Spec-To-App Benchmark), 首个面向 Visual Spec-to-Web-App Coding Agents 的端到端 Benchmark。
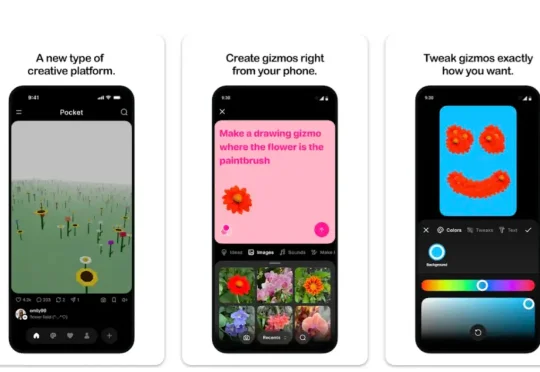
没有发布会,没有 Zuckerberg 的长文,Meta 就这样在六月底悄悄把一款新应用塞进了 App Store 和 Google Play。 这款叫 Pocket 的产品,直到七月初才被应用研究员 Alessandro Paluzzi 在 X 上扒出来。Appfigures 的数据证实,它最早出现在应用商店的时间是 6 月 29 日。没有官方公告,没有推广投放,甚至连美国用户眼下都下载不了

当地时间2026年7月2日,黑石旗下的数据中心运营商QTS正式决定,放弃参与位于弗吉尼亚州威廉王子县的Digital Gateway数据中心项目。Digital Gateway项目曾被视为AI时代的“算力圣地”:

WIRED 上周曝光了一个消息:Meta 的几百名外国员工,假扮成 13 岁少女、小学生等,向 ChatGPT、Gemini、Character.AI 发送提示词。这个项目代号叫 Cannes,Meta 通过外包商 Covalen 执行,最近一次活跃是今年 4 月。

北大团队雪梦未来(SnowOrigin)获龚虹嘉、陆奇及海外机构投资。公司以神经腕带、全景头环等可穿戴设备为入口,结合自研NMH(Neural Math Hybrid)AI 解码模型,试图将人类真实操作过程中的意图、姿态、发力趋势、微控制及环境上下文,转化为可用于机器人、世界模型和具身智能训练的结构化数据。
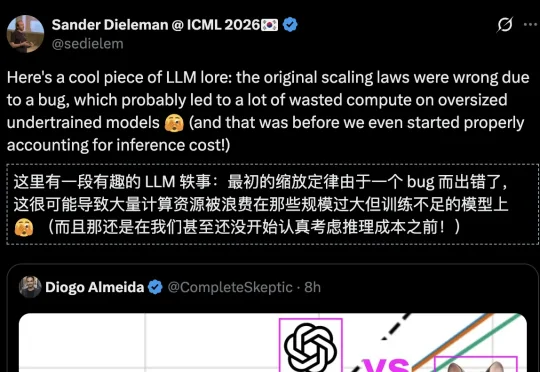
OpenAI误导了整个AI圈好几年!过去五年,整个AI行业都被Scaling Law推着往前冲。现在,有人站出来说:这条曲线,一开始就错了。刚刚,他发出一篇博客,标题冷得发指——《Scaling Laws, Honestly》。
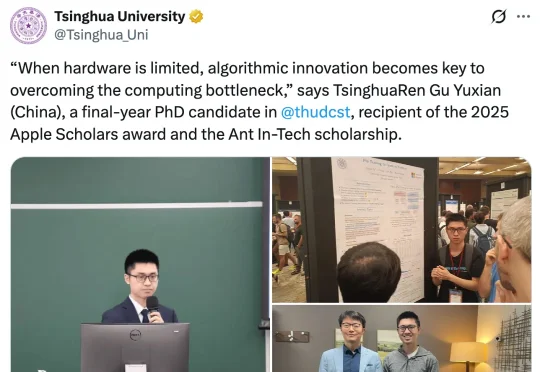
就我们所知,顾煜贤已经正式加入了 DeepSeek。顾煜贤还曾获得 2025 年度苹果博士奖学金以及蚂蚁 In-Tech 奖学金。个人主页显示,顾煜贤在清华大学交互式人工智能课题组(Conversational AI, CoAI)学习,师从黄民烈教授。

今天想和大家分享一种业务建模方法:Agent Ontology,Agent 本体论 Ontology 是我在研究 Palantir 时不断出现的一个词,仔细研究后觉得很有必要单独拿出来,和大家分享。 首先,Ontology 不是单纯的方法论,也不是单独一个工具。

硅谷创投哲学家纳瓦尔·拉维坎特(Naval Ravikant)有一个著名的论断,令人印象深刻:“在一个拥有无限杠杆的世界里,判断力是最重要的技能。”我们一直以来对AI的忧虑——失业、偏见、安全……,或许都只是冰山浮出水面的部分。海面之下,一个更巨大、更隐蔽的变革正在发生。