视觉大模型迎来“o1时刻”:腾讯混元提出SOAR,让AI在生成中学会自我纠偏
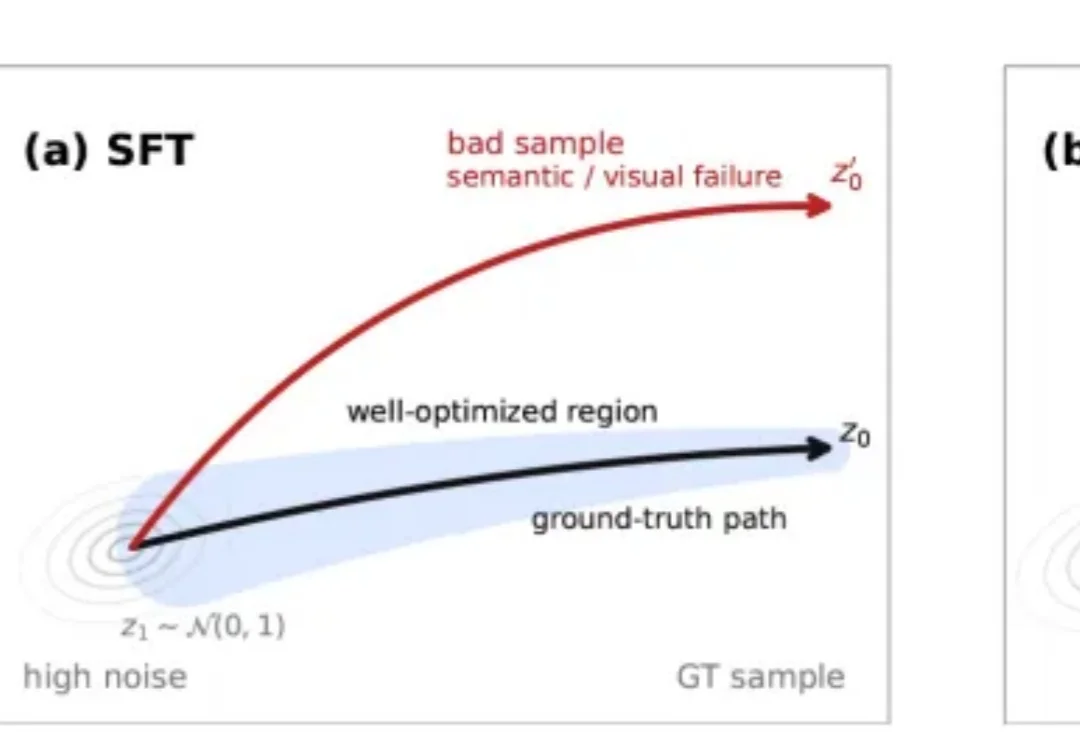
视觉大模型迎来“o1时刻”:腾讯混元提出SOAR,让AI在生成中学会自我纠偏近日,腾讯混元团队提出HY-SOAR (Self-Correction for Optimal Alignment and Refinement),一种面向扩散模型和流匹配模型的数据驱动后训练方法。
来自主题: AI技术研报
7809 点击 2026-04-23 14:44
 搜索
搜索
近日,腾讯混元团队提出HY-SOAR (Self-Correction for Optimal Alignment and Refinement),一种面向扩散模型和流匹配模型的数据驱动后训练方法。

1997年深蓝下棋,2016年AlphaGo围棋,2026年9个Claude副本做真实科研……每次我们都说「只是特定领域」。这一次,我们真的还能说什么?欢迎来到AI成为科研同事、竞争者、甚至继任者的时代。
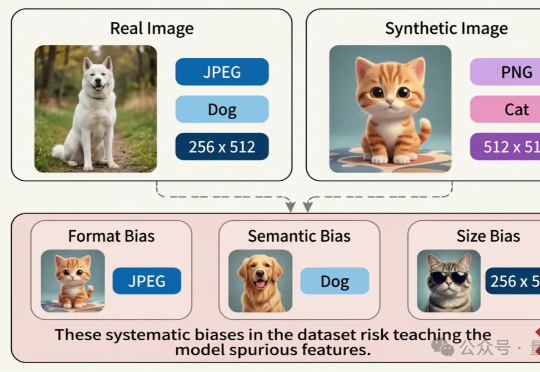
近日,腾讯优图实验室联合华东理工大学、北京大学等研究团队在A生成图像检测(AI-Generated Image Detection)泛化问题上展开研究,提出Dual Data Alignment(双重数据对齐,DDA)方法,从数据层面系统性抑制“偏差特征”,显著提升检测器在跨模型、跨数据域场景下的泛化能力。

刚刚,Anthropic 发布了一项新研究成果。今天,他们发布的成果是《Natural emergent misalignment from reward hacking》,来自 Anthropic 对齐团队(Alignment Team)。他们发现,现实中的 AI 训练过程可能会意外产生未对齐的(misaligned)模型。

阿里巴巴集团安全部联合清华大学、复旦大学、东南大学、新加坡南洋理工等高校,联合发布技术报告;其理念与最近OpenAI发布的GPT-5 System Card放在首位的“From Hard Refusals to Safe-Completions”理念不谋而合。

这份提示词有很多哲学性思考,很多表达让我看到背后的设计者把claude当成一个人去设计。 我猜,应该是Amanda Askell(Anthropic负责alignment和character design,是学哲学的一位女生,也是我的榜样) 主要设计的。

OpenAI 在 “双十二” 发布会的最后一天公开了 o 系列背后的对齐方法 - deliberative alignment,展示了通过系统 2 的慢思考能力提升模型安全性的可行性。

OpenAI o1风格的推理大模型,有行业垂直版了。HK-O1aw,是由香港生成式人工智能研发中心(HKGAI)旗下AI for Reasoning团队(HKAIR) 联合北京大学对齐团队(PKU-Alignment Team)推出的全球首个慢思考范式法律推理大模型。

随着人工智能大模型的能力日益强大,如何让其行为和目标同人类的价值、偏好、意图之间实现协调一致,即人机对齐(human-AI alignment)问题,变得越发重要。

随着大规模语言模型的快速发展,如 GPT、Claude 等,LLM 通过预训练海量的文本数据展现了惊人的语言生成能力。然而,即便如此,LLM 仍然存在生成不当或偏离预期的结果。这种现象在推理过程中尤为突出,常常导致不准确、不符合语境或不合伦理的回答。为了解决这一问题,学术界和工业界提出了一系列对齐(Alignment)技术,旨在优化模型的输出,使其更加符合人类的价值观和期望。