
谷歌Gemma4-12B怎么用最好?16G显存轻薄本也能跑起本地多模态SubAgent
谷歌Gemma4-12B怎么用最好?16G显存轻薄本也能跑起本地多模态SubAgent过去一年,开源模型的发布节奏已经快到让人麻木。每次发布,伴随的永远是一组跑分、一张能力雷达图,以及几个“超越某某”的结论。
来自主题: AI技术研报
7805 点击 2026-06-11 10:18
 搜索
搜索
过去一年,开源模型的发布节奏已经快到让人麻木。每次发布,伴随的永远是一组跑分、一张能力雷达图,以及几个“超越某某”的结论。

一年前,行业还在为“从自动补全到 Agent”的进化感到兴奋。然而一年过去,我们不难发现单纯靠“Vibe Coding”和“Prompt 调优”,面对非确定性模型带来的风险和成本问题,显然无法撑起企业级软件开发。

VeRL-Omni 是一个面向多模态生成模型的通用 RL 后训练框架,由 VeRL-Omni 团队在 verl 与 vllm-omni 之上构建。覆盖扩散 transformer(Qwen-Image)、混合 AR-DiT(Qwen-Omni)、统一理解 + 生成(BAGEL、HunyuanImage-3.0)等架构。

李诞带火了一个AI娱乐应用贝果,带着好奇,我第一时间通过内部朋友要到了内测资格。最上头的是贝果的“现实 Online”这个产品。它的玩法听上去极其简单:拿起手机,随手一扫,但就在这短短几秒钟里,整个办公室瞬间就被改造成了一个可以实时探索的游戏空间。
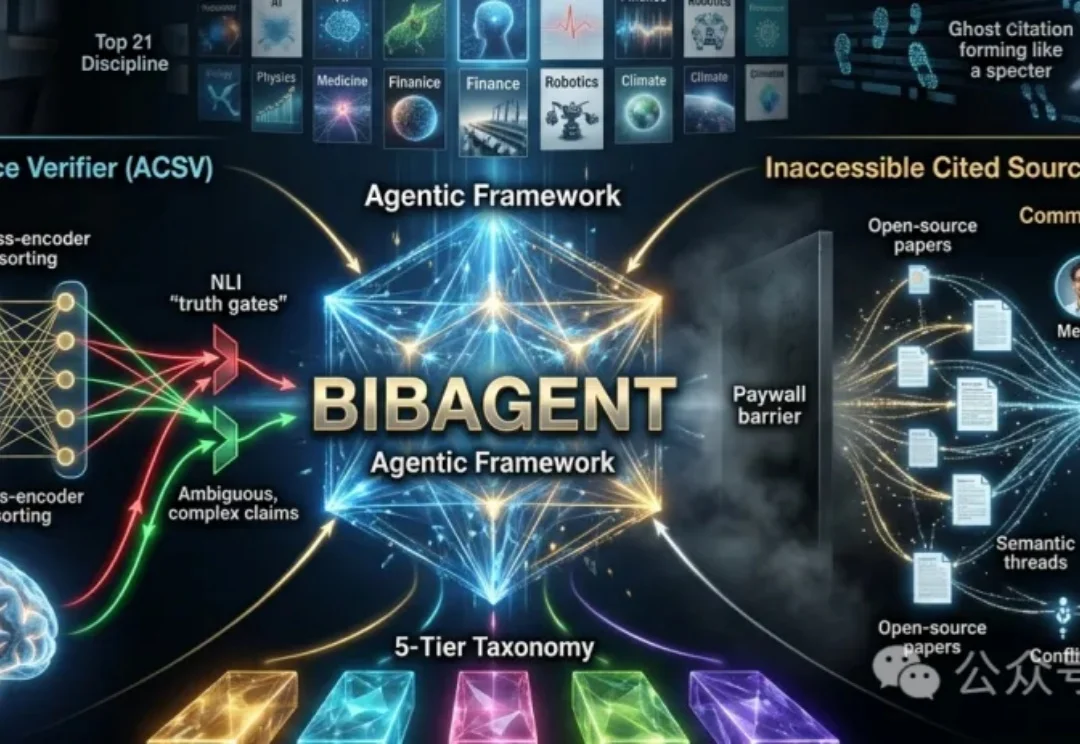
大模型正在批量生成「看起来很像真的」学术论述,但这些论述背后的引用,真的成立吗?更关键的是:当被引论文被付费墙锁住、原文根本读不到时,自动化核验是否就注定失效?
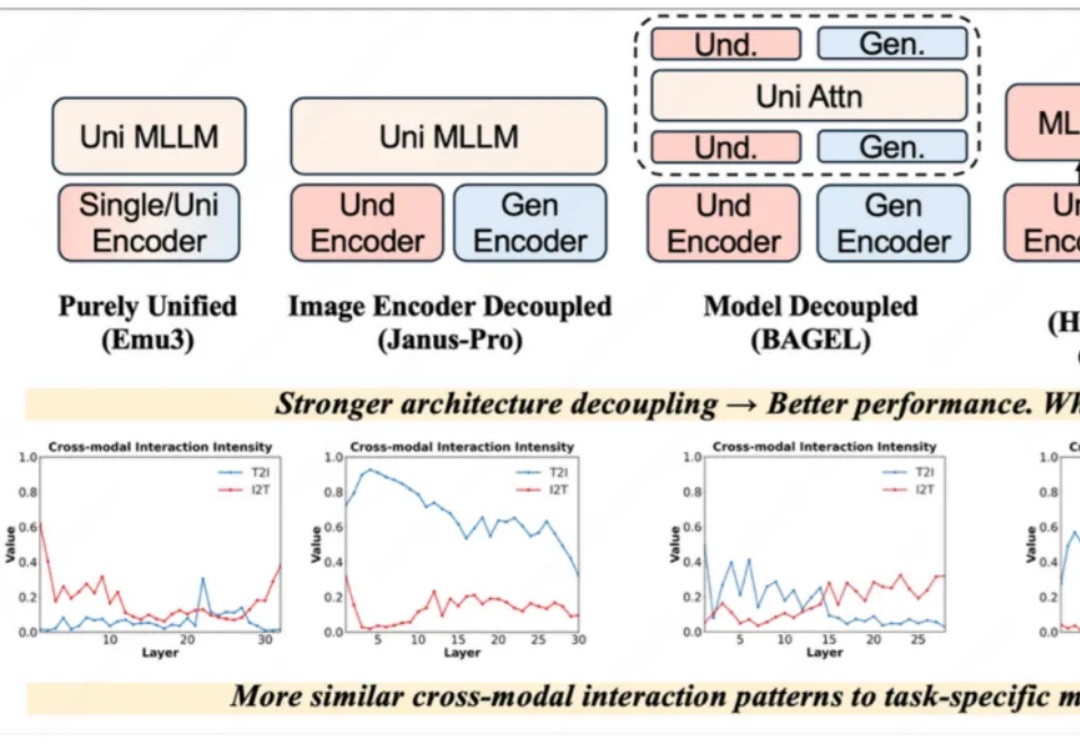
近一年以来,统一理解与生成模型发展十分迅速,该任务的主要挑战在于视觉理解和生成任务本身在网络层间会产生冲突。早期的完全统一模型(如 Emu3)与单任务的方法差距巨大,Janus-Pro、BAGEL 通过一步一步解耦模型架构,极大地减小了与单任务模型的性能差距,后续方法甚至通过直接拼接现有理解和生成模型以达到极致的性能。
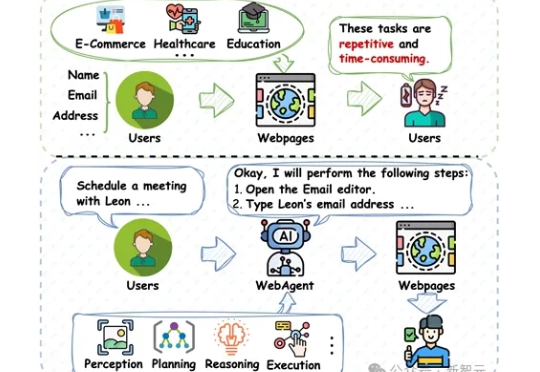
互联网技术的发展极大地便利了我们的生活,但许多网络任务重复繁琐,降低了效率。为了解决这一问题,研究人员正在开发基于大型基础模型(LFMs)的智能体——WebAgents,通过感知环境、规划推理和执行交互来完成用户指令,显著提升便利性。香港理工大学的研究人员从架构、训练和可信性等角度,总结了WebAgents的代表性方法,全面梳理了相关研究进展。

WebAgent 续作《WebShaper: Agentically Data Synthesizing via Information-Seeking Formalization》中
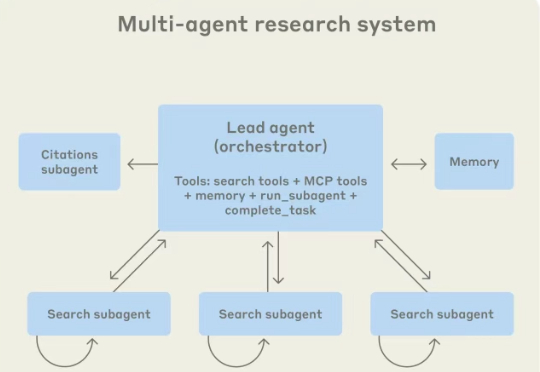
在这篇文章中,它详细展示了如何构建一个有效的多智能体研究系统,这是一个架构,其中主代理(The Lead Agent)会生成和协调子代理(Subagents),以并行方式探索复杂查询,内容涵盖系统架构、提示工程以及评估方法等。

过去一段时间,“通用 Agent”成了 AI 应用的默认发展方向。无论产品叙事还是技术布局,大家似乎都在追求一个“什么都能做”的智能体。但现实逐渐显露:通用 Agent 在真实世界中并不那么“通用”。