刚刚,OpenClaw史上最猛更新!AI记忆可自由插拔,开发者等了半年
刚刚,OpenClaw史上最猛更新!AI记忆可自由插拔,开发者等了半年OpenClaw推出v2026.3.7-beta.1,史上最密集一次更新:89项提交、200+Bug修复,核心亮点是全新ContextEngine插件接口——上下文管理终于可以「自由插拔」,不动核心代码就能换策略。这次更新值得每一个做AI Agent的人认真看。
来自主题: AI资讯
9534 点击 2026-03-09 11:07
 搜索
搜索
OpenClaw推出v2026.3.7-beta.1,史上最密集一次更新:89项提交、200+Bug修复,核心亮点是全新ContextEngine插件接口——上下文管理终于可以「自由插拔」,不动核心代码就能换策略。这次更新值得每一个做AI Agent的人认真看。

不久前在 AGI-Next 前沿峰会上,姚顺雨曾分享过一个核心观点:模型想要迈向高价值应用,核心瓶颈就在于能否「用好上下文(Context)」。

大模型的能力正在被不同的范式逐步解锁:In-Context Learning 展示了模型无需微调即可泛化到新任务;Chain-of-Thought 通过引导模型分步推理来提升复杂问题的求解能力;近期,智能体框架则赋予模型调用工具、多轮交互的能力。
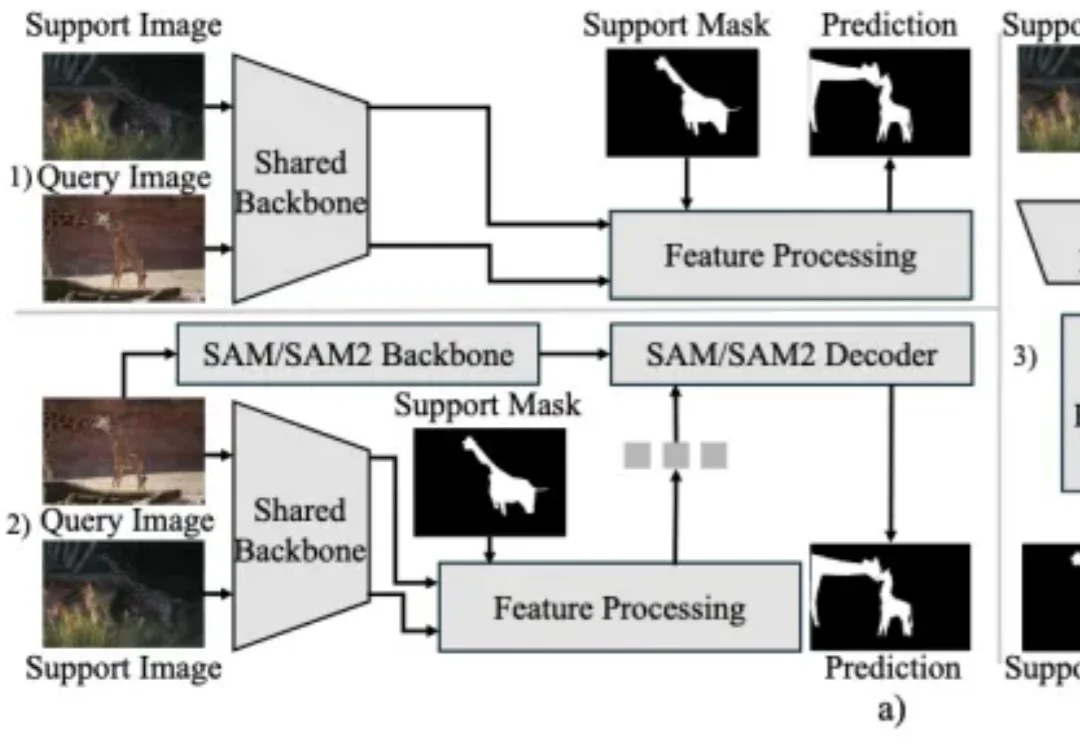
上下文分割(In-Context Segmentation)旨在通过参考示例指导模型实现对特定目标的自动化分割。尽管 SAM 凭借卓越的零样本泛化能力为此提供了强大的基础,但将其应用于此仍受限于提示(如点或框)构建,这样的需求不仅制约了批量推理的自动化效率,更使得模型在处理复杂的连续视频时,难以维持时空一致性。

最近,Cursor 也发表了一篇文章《Dynamic context discovery》,分享了他们是怎么做上下文管理的。结合 Manus、Cursor 这两家 Agent 领域头部团队的思路,我们整理了如何做好上下文工程的一些关键要点。
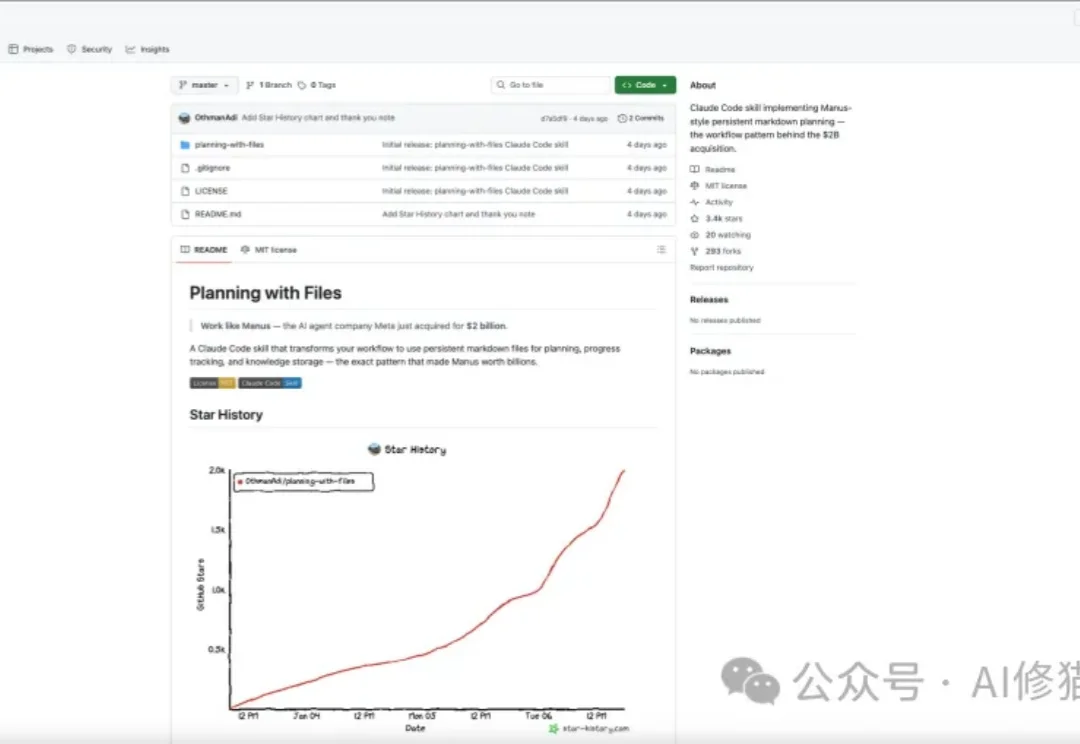
planning-with-files是开源社区最近疯传的一个Skill,发布仅四天收获3.3k star。目前还在持续增长。
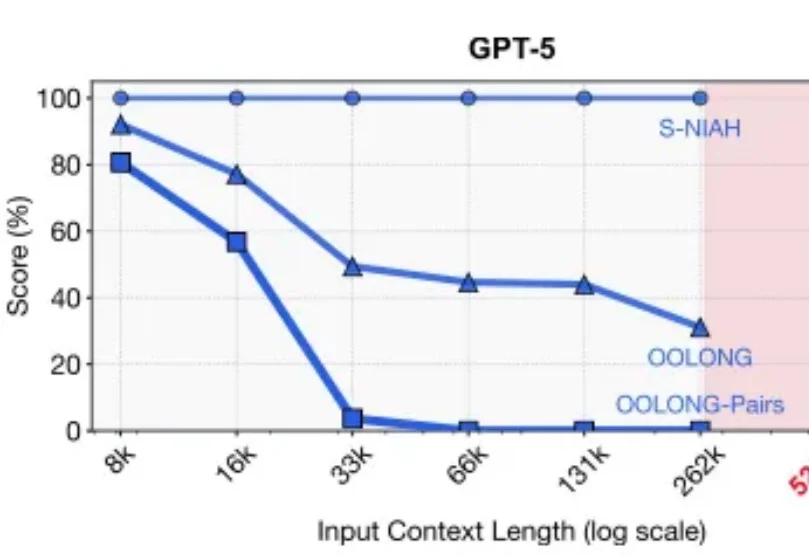
2025年的最后一天, MIT CSAIL提交了一份具有分量的工作。当整个业界都在疯狂卷模型上下文窗口(Context Window),试图将窗口拉长到100万甚至1000万token时,这篇论文却冷静地指出了一个被忽视的真相:这就好比试图通过背诵整本百科全书来回答一个复杂问题,既昂贵又低效。
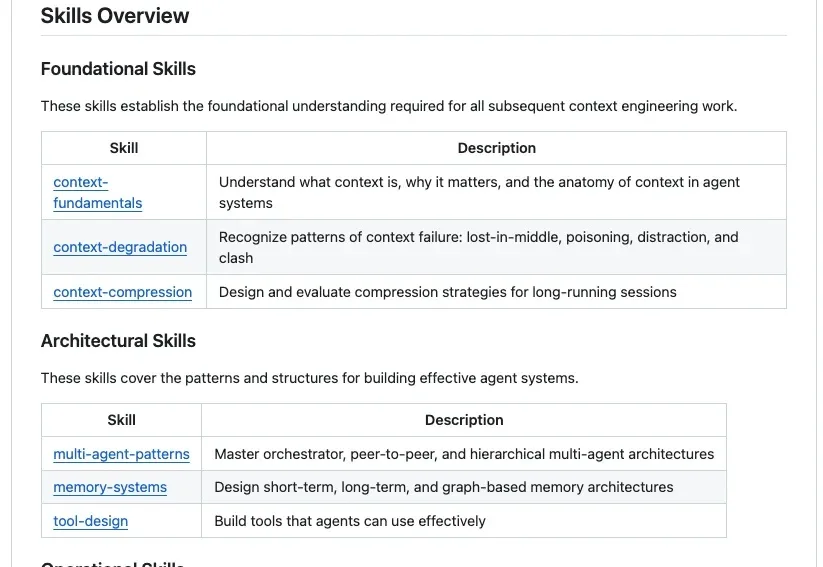
GitHub上最近出现了一个非常火的项目Agent-Skills-for-Context-Engineering,发布不到一周就斩获了2.3k Stars。为什么它能瞬间引爆社区?因为站在2025年末的节点上,我们已经受够了那些只存在于大厂白皮书里的Context Engineering(上下文工程) 理论。

浙江大学ReLER团队开源ContextGen框架,攻克多实例图像生成中布局与身份协同控制难题。基于Diffusion Transformer架构,通过双重注意力机制,实现布局精准锚定与身份高保真隔离,在基准测试中超越开源SOTA模型,对标GPT-4o等闭源系统,为定制化AI图像生成带来新突破。
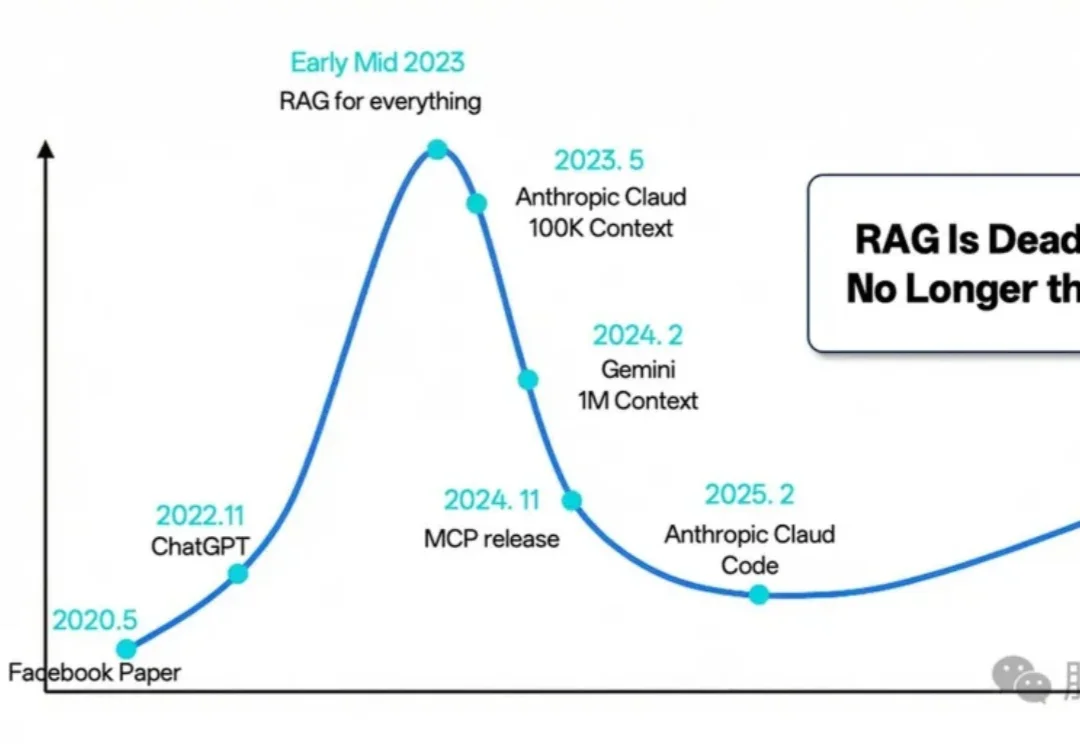
过去的 2025 年,对于检索增强生成(RAG)技术而言,是经历深刻反思、激烈辩论与实质性演进的一年。