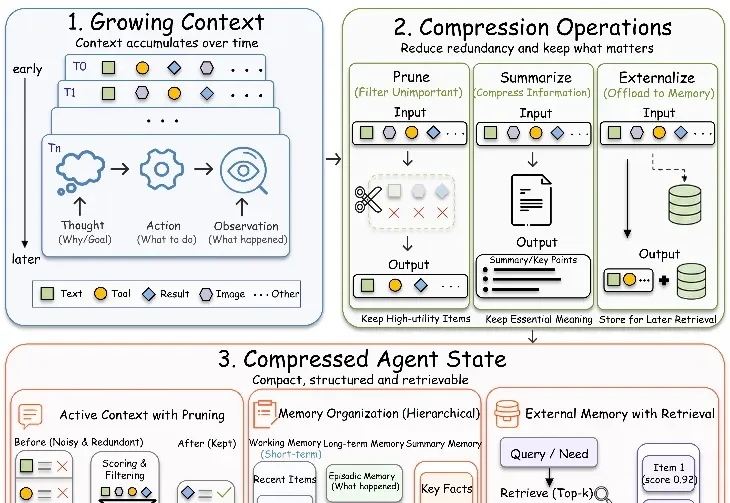
一篇综述看懂 agent context compression:怎么压、压什么、谁来压
一篇综述看懂 agent context compression:怎么压、压什么、谁来压LLM Agent 做长任务时,真正让人头疼的往往不是模型不会推理,而是上下文开始失控:前几步还很清楚,后面就忘约束、丢状态、重复试错,最后把任务跑成事故现场。
来自主题: AI技术研报
6305 点击 2026-06-11 14:32
 搜索
搜索
LLM Agent 做长任务时,真正让人头疼的往往不是模型不会推理,而是上下文开始失控:前几步还很清楚,后面就忘约束、丢状态、重复试错,最后把任务跑成事故现场。
除此之外,context-mode 将大模型的记忆力从30分钟提升至 3 小时。

一年前,行业还在为“从自动补全到 Agent”的进化感到兴奋。然而一年过去,我们不难发现单纯靠“Vibe Coding”和“Prompt 调优”,面对非确定性模型带来的风险和成本问题,显然无法撑起企业级软件开发。

Lucius 是一家做企业级 AI 员工的公司,但创始人赵赫不太喜欢「AI 员工」这个标签。他更愿意说,Lucius 做的是企业的 Context Layer,一套让 Agent 能够进入组织、理解现场、遵守边界、持续调度任务的组织调度系统。
欢迎大家尝试前不久GitHub的日榜榜首项目——Claude Context。通过在AI coding场景引入混合检索,Claude Context相比使用grep的原生 Claude Code 能大幅提升检索精度和效率,减少约 40% 的 不必要Token 消耗。

郭亚楠说,Context就承接了新需求。传统OS让人和软件对齐,新OS应该让人和Agent对齐。因为Context是个人数据的结构化、语义化集合,它就像OS管理内存和CPU一样管理每个人的数字痕迹。
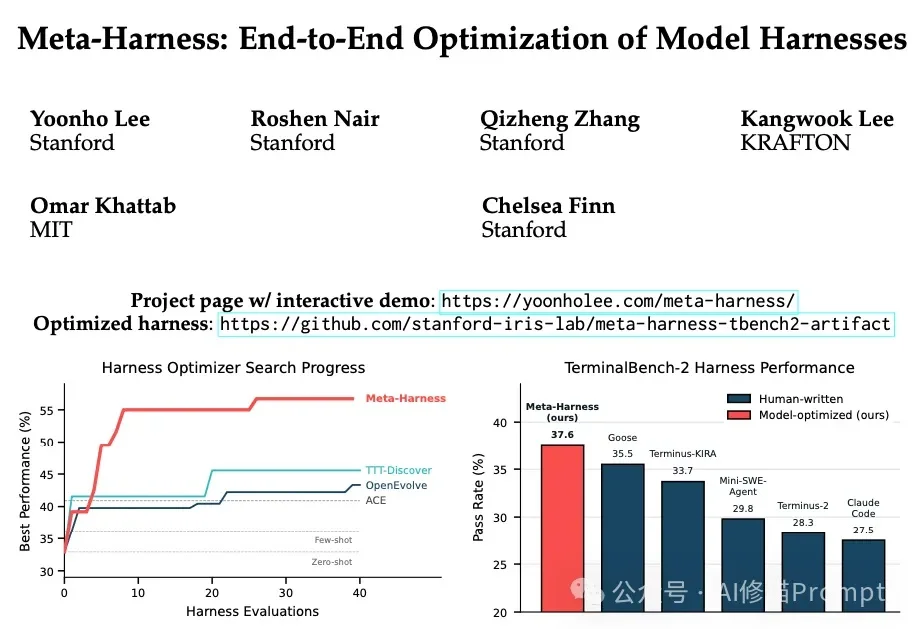
去年讨论Agent落地时,重点往往是Context Engineering。大家都在琢磨怎么放 Few-shot,怎么优化 RAG 检索的文本片段。但随着 Agent 任务复杂度的上升,控制数据流向、工具调度和异常处理的底层脚手架代码,往往比单纯拼接文本对系统性能的影响更大。
AirJelly 发布了内测版本。
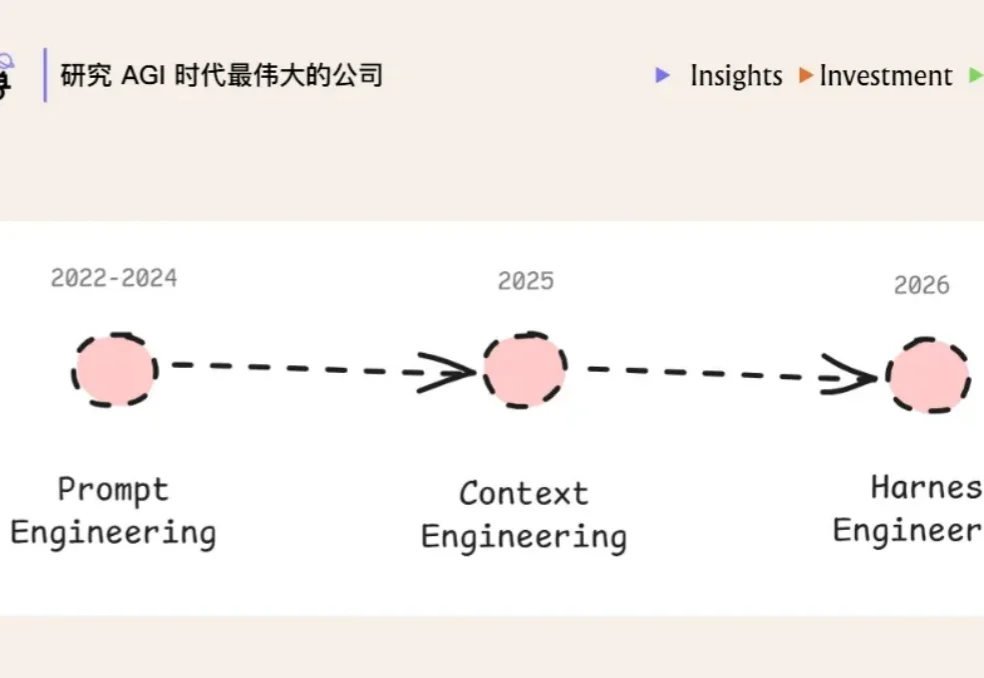
最近,harness engineering 又成了继 prompt engineering、context engineering 之后新一代的 buzzword。

「龙虾」(OpenClaw)的爆发,让一个趋势迅速达成共识——Agent 正在「杀死」软件,GUI 正在过时。而当下的电脑、手机等设备,并不是运行「龙虾」的最佳选项。