刚刚谷歌发布 Gemini 3.1 Pro
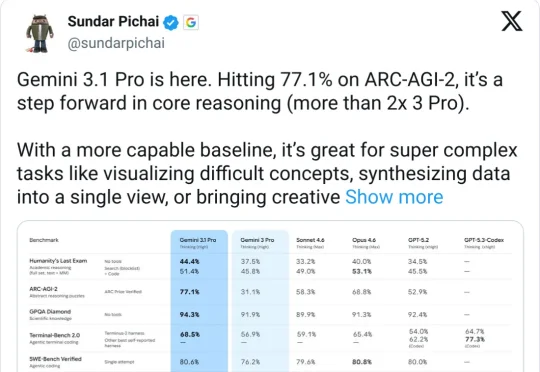
刚刚谷歌发布 Gemini 3.1 Pro今天凌晨,Google 发布 Gemini 3.1 Pro。核心提升在推理能力,ARC-AGI-2(抽象推理基准)从 3 Pro 的 31.1% 跳到 77.1%,翻了一倍多,GPQA Diamond(科学知识推理)从 91.9% 提到 94.3%
来自主题: AI资讯
10969 点击 2026-02-20 02:47
 搜索
搜索
今天凌晨,Google 发布 Gemini 3.1 Pro。核心提升在推理能力,ARC-AGI-2(抽象推理基准)从 3 Pro 的 31.1% 跳到 77.1%,翻了一倍多,GPQA Diamond(科学知识推理)从 91.9% 提到 94.3%

宾夕法尼亚大学沃顿商学院(The Wharton School)今年发布了一系列名为《Prompting Science Reports》的重磅研究报告。他们选取了2024-2025最常用的模型(如GPT-4o, Claude 3.5 Sonnet, Gemini Pro/Flash等),在极高难度的博士级基准测试(GPQA Diamond)上进行了数万次的严谨测试。

AI科学发现公司Autopoiesis Sciences宣布,其人工智能联合科学家Aristotle X1 Verify在多项基准测试中取得了显著成果,性能超越了所有主流AI模型。据悉,Aristotle X1 Verify在推理基准测试GPQA Diamond中达到了92.4%的准确率
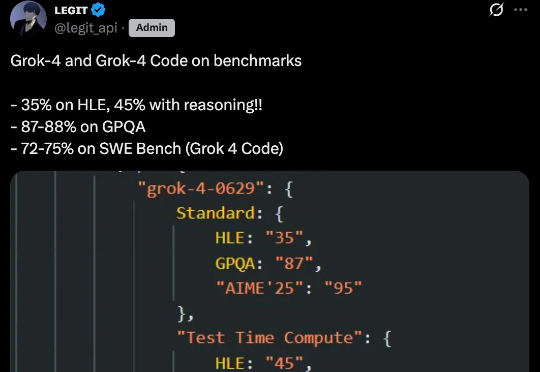
刚刚,Grok 4 和 Grok 4 Code 的基准测试结果疑似泄露。X 博主 @legit_api 发帖称,Grok 4 在 HLE(Humanities Last Exam,人类最后考试)上的标准得分是 35%,使用推理技术后提高到 45%;在 GPQA 上的得分是 87-88%;而Grok 4 Code 在 SWE Bench 上的得分则达到 72-75%。

没等来 DeepSeek 官方的 R2,却迎来了一个速度更快、性能不弱于 R1 的「野生」变体!这两天,一个名为「DeepSeek R1T2」的模型火了!这个模型的速度比 R1-0528 快 200%,比 R1 快 20%。除了速度上的显著优势,它在 GPQA Diamond(专家级推理能力问答基准)和 AIME 24(数学推理基准)上的表现均优于 R1,但未达到 R1-0528 的水平。

要知道,过去几年,各种通用评测逐渐同质化,越来越难以评估模型真实能力。GPQA、MMLU-pro、MMLU等流行基准,各家模型出街时人手一份,但局限性也开始暴露,比如覆盖范围狭窄(通常不足 50 个学科),不含长尾知识;缺乏足够挑战性和区分度,比如 GPT-4o 在 MMLU-Pro 上准确率飙到 92.3%。
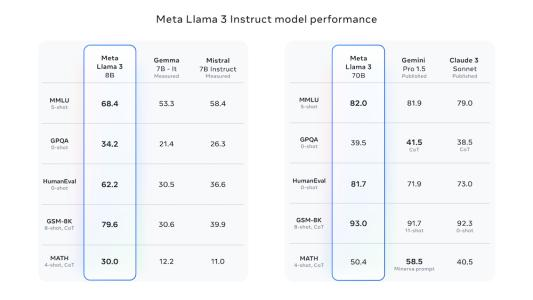
智东西4月19日消息,Meta推出迄今为止能力最强的开源大模型Llama 3系列,发布8B和70B两个版本。 Llama 3在一众榜单中取得开源SOTA(当前最优效果)。Llama 3 8B在MMLU、GPQA、HumanEval、GSM-8K等多项基准上超过谷歌Gemma 7B和Mistral 7B Instruct。