
112页报告深挖GPT-4V!UCLA等发布全新「多模态数学推理」基准MathVista
112页报告深挖GPT-4V!UCLA等发布全新「多模态数学推理」基准MathVista大型多模态模型会做数学题吗?在UCLA等机构最新发布的MathVista基准上,即使是当前最强的GPT-4V也会感到「挫败感」。
来自主题: AI资讯
11032 点击 2023-12-05 17:15
 搜索
搜索
大型多模态模型会做数学题吗?在UCLA等机构最新发布的MathVista基准上,即使是当前最强的GPT-4V也会感到「挫败感」。

本文中,上海交大 & 上海 AI Lab 发布 Radiology Foundation Model (RadFM),开源 14B 多模态医疗基础模型,首次支持 2D/3D 放射影像输入。

目前最好的大型多模态模型 GPT-4V 与大学生谁更强?我们还不知道,但近日一个新的基准数据集 MMMU 以及基于其的基准测试或许能给我们提供一点线索,

由南洋理工华人团队新提出的80亿参数多模态大模型OtterHD,不仅可以搞定让GPT-4V都发愁的难题,甚至还可以数出来《清明上河图》(局部)里到底有多少只骆驼!
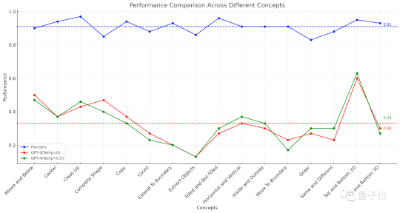
GPT-4的图形推理能力,竟然连人类的一半都不到? 美国圣塔菲研究所的一项研究显示,GPT-4做图形推理题的准确率仅有33%。而具有多模态能力的GPT-4v表现更糟糕,只能做对25%的题目。
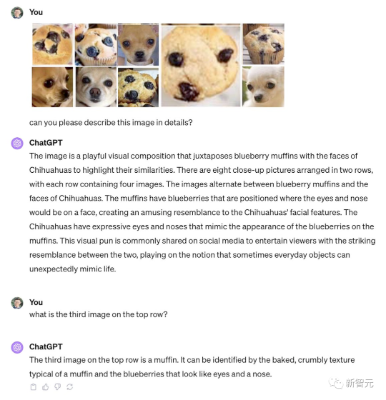
最近,GPT-4V接连被曝重大缺陷,会把吉娃娃认成松饼,只要一被忽悠就会同意图中的葫芦娃中有8个!
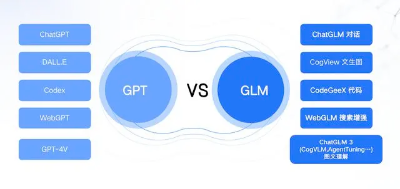
在新模型发布后,智谱 AI CEO 张鹏和极客公园聊了聊他们的近况和一些行业认知。谈到与ChatGLM2相比,智谱 AI 此次瞄准 GPT-4V 推出的 ChatGLM 3 性能更加强大,接入了具有多模态理解能力的模型 CogVLM、代码增强模块 Code Interpreter、网络搜索增强模型 WebGLM,并增强了语义理解和逻辑理解能力,实现了若干功能的迭代升级。

GPT-4V挑战视觉错误图,结果令人“大跌眼镜”。 像这种判断“哪边颜色更亮”的题,一个没做对
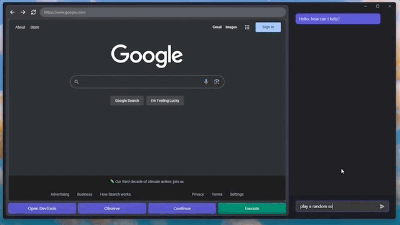
GPT-4V学会自动操纵电脑,这一天终于还是到来了。 只需要给GPT-4V接入鼠标和键盘,它就能根据浏览器界面上网:甚至还能快速摸清楚“播放音乐”的播放器网站和按钮,给自己来一段music:
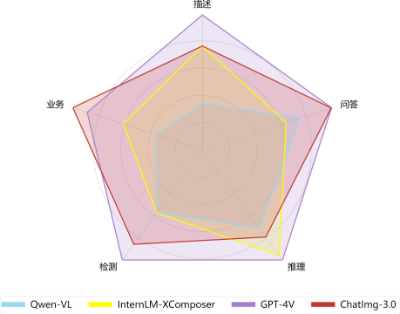
在 10 月 28 日举办的 CNCC 2023「超智融合 AI 大模型应用落地发展论坛」上,智子引擎发布了「元乘象 Chatimg3.0」,展示了多模态通用生成模型「元乘象 Chatimg3.0」的最新进展与落地探索。