
奥特曼亲封GPT-5.5「自闭天才」!16人团队连夜退订Claude
奥特曼亲封GPT-5.5「自闭天才」!16人团队连夜退订Claude奥特曼亲口盖章,GPT-5.5是个「自闭天才」。16人团队连夜退订Claude,换GPT-5.5月省3.2万刀。Codex单周狂飙9000万下载大虐对手12倍,开发者大迁徙开始了。
来自主题: AI资讯
7391 点击 2026-05-11 09:37
 搜索
搜索
奥特曼亲口盖章,GPT-5.5是个「自闭天才」。16人团队连夜退订Claude,换GPT-5.5月省3.2万刀。Codex单周狂飙9000万下载大虐对手12倍,开发者大迁徙开始了。
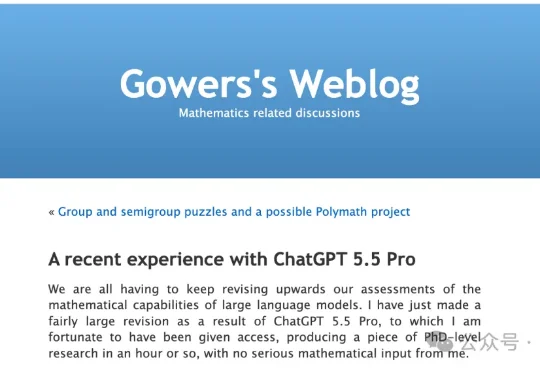
全网震撼!菲尔兹奖得主把未解数学题扔给GPT-5.5 Pro,不到两小时拿到博士论文级证明。整个过程中,他没给出任何数学思路。
ChatGPT默认模型,今天大升级。

5月5日下午5:55,GPT-5.5要给自己办场party——时间是GPT-5.5自己挑的,客人由Codex从推文回复里挑。这场看起来像段子的活动背后,是一个真实的市场拐点:过去两个月,AI编程工具圈发生了一次明显的用户迁移,开发者开始从Claude Code转向Codex。
就在刚刚,OpenAI 正式发布了 GPT-5.5 Instant,将其设为 ChatGPT 的默认模型,取代此前的 GPT-5.3 Instant,面向所有用户开放。Instant 系列是 ChatGPT 的日常主力模型,每天有数以亿计的用户在用。官方说,在这个量级上,哪怕只是小幅改进,积累起来的效果也相当可观。
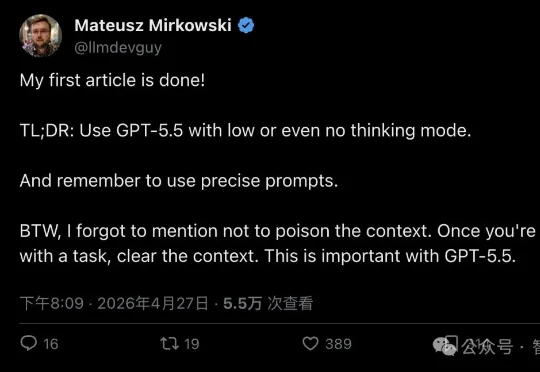
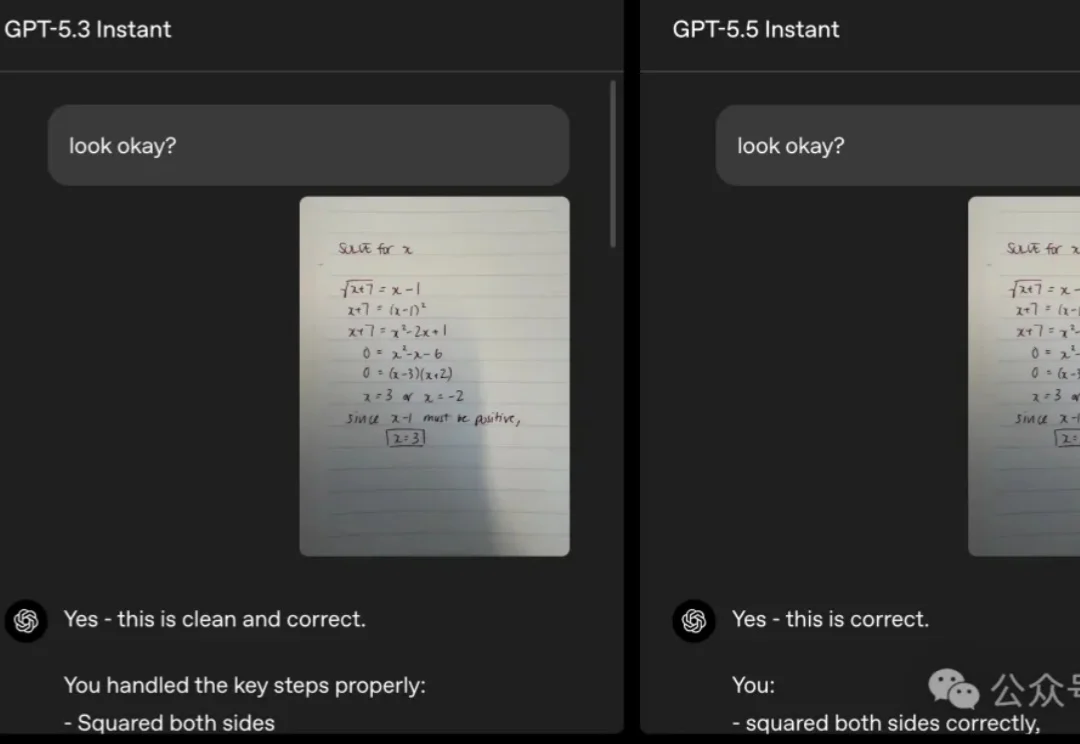
过去一年,整个 AI 行业都在告诉你:让模型多想一会儿,答案更好。但一批 GPT-5.5 重度用户刚刚用实战经验打了所有人的脸——thinking 开低、甚至不开,反而更稳更快更能打。
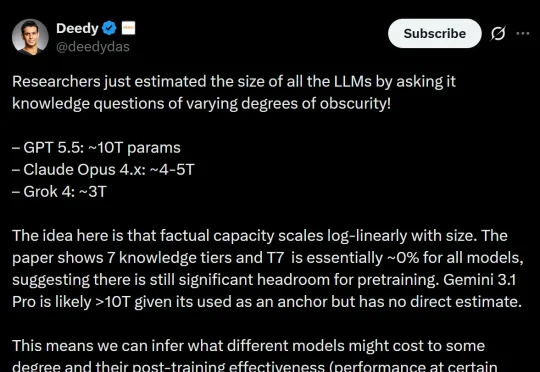
五一假期前,AI社区被一篇「GPT-5.5拥有近10万亿参数」的论文刷屏,今天这项研究就被研究者打假了!研究者表示,修正论文中的各种问题后,GPT-5.5的参数很可能约为1.5T。

OpenAI 和 Anthropic 几乎在同一时间发布自己的提示词文档,在 OpenAI 官网,从 GPT-4.1 到 GPT 5.5,每次新模型发布都有一份完整的提示词指南,告诉我们怎么用新的模型。

Grok 4.3 是 xAI 一次务实升级:更便宜、更快、更像能干活的助手。但它在硬推理、稳定性和可信度上,仍落后 GPT-5.5 与 Claude Opus 4.7。
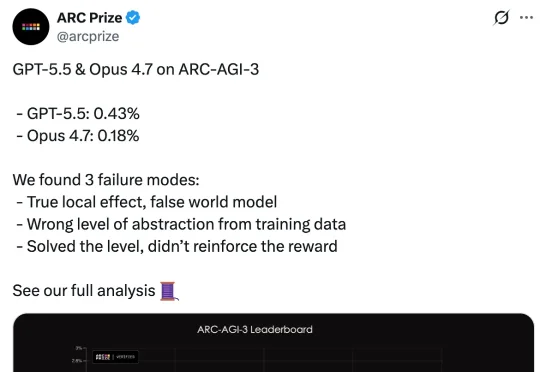
近日,ARC Prize 官方发布了针对这两款顶级模型的详细分析报告,结果令人震惊:在面对未见过的逻辑任务时,两者的表现得分均低于 1%,GPT-5.5 得分 0.43%,Claude Opus 4.7 得分 0.18%。