
清华孙茂松团队 × 深言科技:以解释作为训练信号,让 8B 模型在幻觉检测上反超闭源大模型
清华孙茂松团队 × 深言科技:以解释作为训练信号,让 8B 模型在幻觉检测上反超闭源大模型FaithLens 模型在忠实性幻觉检测任务上,达到了当前最优效果。
来自主题: AI技术研报
9172 点击 2026-01-08 08:43
 搜索
搜索
FaithLens 模型在忠实性幻觉检测任务上,达到了当前最优效果。
在 LLM Agent 领域,有一个常见的问题:Agent 明明 "看到了" 错误信息,却总是重蹈覆辙。
最近,视频会议软件公司 Zoom 发布了一条出人意料的消息:他们宣称在“人类最后的考试”(Humanity s Last Exam,简称 HLE)这个号称当前 AI 领域最具挑战性的基准测试上,取得了 48.1% 的成绩,比此前由 Google Gemini 3 Pro(带工具)保持的 45.8% 高出 2.3 个百分点。

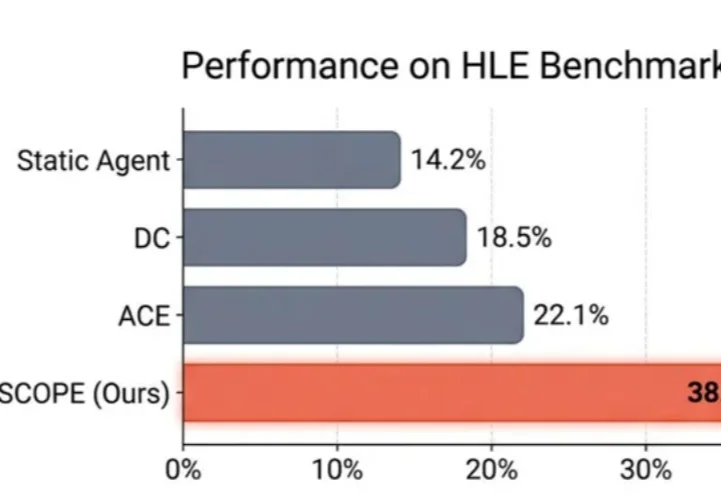
觉得大模型消耗的算力过大,英伟达推出的8B模型Orchestrator化身「拼好模」,通过组合工具降本增效,使用30%的预算,在HLE上拿下37.1%的成绩。

当问题又深又复杂时,一味上最强模型既贵又慢。测试时扩展能想得更久,却不一定想得更对。
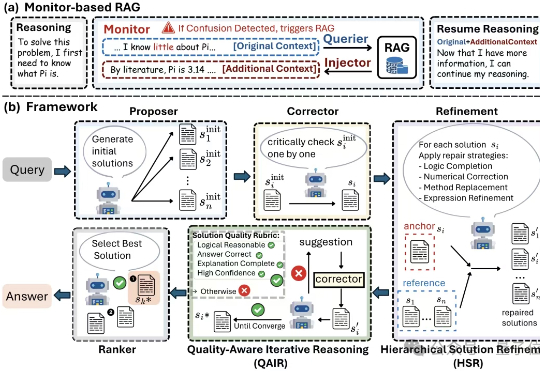
就在最近,由耶鲁大学唐相儒、王昱婕,上海交通大学徐望瀚,UCLA万冠呈,牛津大学尹榛菲,Eigen AI金帝、王瀚锐等团队联合开发的Eigen-1多智能体系统实现了历史性突破

红杉美国合伙人 Konstantine Buhler 预测 2025 年将成为 AI agent 的“群体协作”时代,标志着 Agent 元年的到来。
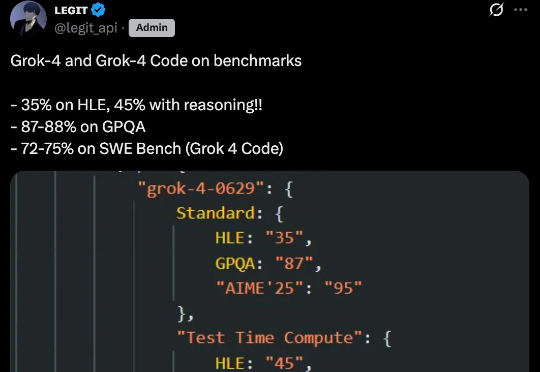
刚刚,Grok 4 和 Grok 4 Code 的基准测试结果疑似泄露。X 博主 @legit_api 发帖称,Grok 4 在 HLE(Humanities Last Exam,人类最后考试)上的标准得分是 35%,使用推理技术后提高到 45%;在 GPQA 上的得分是 87-88%;而Grok 4 Code 在 SWE Bench 上的得分则达到 72-75%。

今日凌晨,Meta AI 部门副总裁 Ahmad Al-Dahle 发文,回应了近日发布的 Llama 4 大模型的争议问题:对于「不同服务中模型质量参差不齐」这一问题,Ahmad Al-Dahle 解释称,由于模型一准备好就发布了,所以 Meta 的团队预计所有公开的应用实现都需要几天时间来进行优化调整,团队后续会继续进行漏洞修复工作。
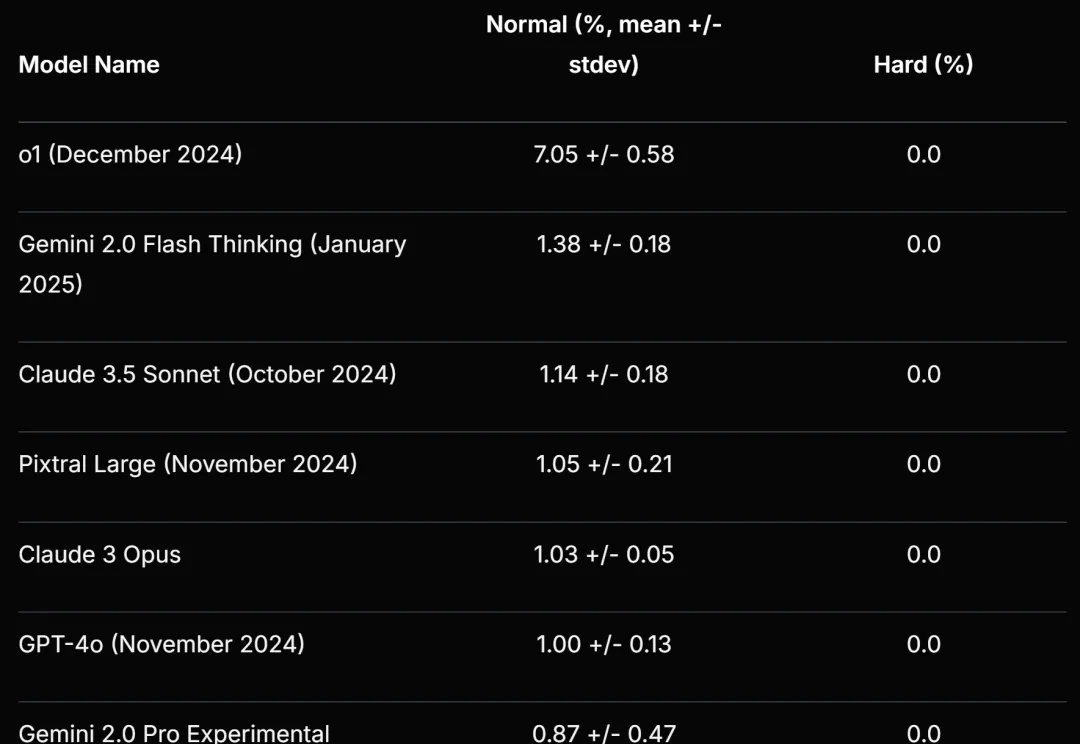
Scale AI 等提出的新基准再次暴露了大语言模型的弱点。