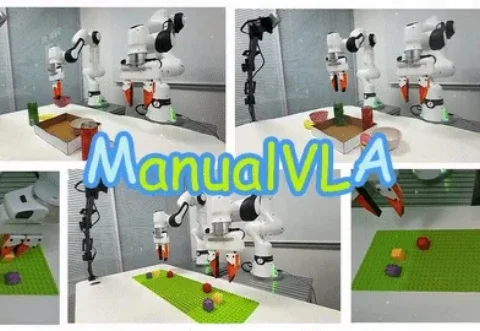
北大发布 ManualVLA:首个长程「生成–理解–动作」一体化模型,实现从最终状态自主生成说明书并完成操纵 北大发布 ManualVLA:首个长程「生成–理解–动作」一体化模型,实现从最终状态自主生成说明书并完成操纵 关键词: AI,模型训练,ManualVLA,人工智能 视觉–语言–动作(VLA)模型在机器人场景理解与操作上展现出较强的通用性,但在需要明确目标终态的长时序任务(如乐高搭建、物体重排)中,仍难以兼顾高层规划与精细操控。 来自主题: AI技术研报 8882 点击 2025-12-19 10:23