# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
视觉–语言–动作(VLA)模型在机器人场景理解与操作上展现出较强的通用性,但在需要明确目标终态的长时序任务(如乐高搭建、物体重排)中,仍难以兼顾高层规划与精细操控。
针对这一问题,北京大学、香港中文大学与至简动力团队提出了全新的「生成–理解–动作」一体化模型 ManualVLA。


不同于 π0 等端到端模型在处理复杂长程任务时仍面临的推理与执行割裂问题,ManualVLA 摒弃了将「高层次规划」与「动作生成」拆分的传统分层级联方案,构建了全新通用基础模型 Mixture-of-Transformers (MoT) 架构,在同一模型中统一多专家模块,实现多模态生成与动作执行的紧密协同。
首先由「规划专家」生成由图像、空间位置提示和文字说明组成的多模态操作说明书,再通过显式与隐式相结合的「思维链」(ManualCoT)推理,将信息反馈给「动作专家」,为每一步操作提供清晰的显式控制条件的同时,通过潜在表征为动作生成提供持续的隐式引导,实现理解与生成的高度统一。
实验结果表明,ManualVLA 在现实场景任务中表现出显著优势,其平均成功率相较于分层结构的最新基线方法提升约 32%,充分验证了「生成手册–指导动作」这一统一范式的有效性。
近年来,VLA 模型在机器人场景理解和泛化操作方面取得了显著进展,推动了通用具身智能体的发展。但当面临需要精确定义最终目标状态的长周期任务,例如复杂的乐高组装或物体重新排列时,现有模型仍然难以协调高级规划与精确操作。
这些任务主要面临两个核心难题:首先,VLA 模型必须执行精确操作以严格对齐预定义的最终场景或物体配置;其次,模型必须有效地将长周期规划与细粒度控制相集成,同时保持对多样化现实世界环境的泛化能力。
现有的分层方法通过依赖人工制作说明书或人类演示视频来模仿这种能力,然而,这些方法通常在泛化到未见过的最终目标状态方面存在局限性,在系统复杂度、部署成本和泛化性之间难以取得兼顾,难以形成一个统一、可端到端训练和部署的体系。

为此,ManualVLA 让模型学会「自己生成说明书,再按说明书去执行动作」。在推理阶段,系统首先接收自然语言指令、当前场景图像和最终目标图像,由规划专家生成包含关键步骤的多模态手册:由文字描述指出要操控哪些物体以及要完成的子目标,像素级坐标给出目标物体在图像中的精确位置,子目标图像则展示子目标完成后的「预期画面」。动作专家在闭环控制中执行这一子目标,直到达到预期状态,再进入下一次手册生成与执行。通过这种逐步推进的方式,原本困难的长时序任务被拆解为一系列可控、可解释的短阶段。
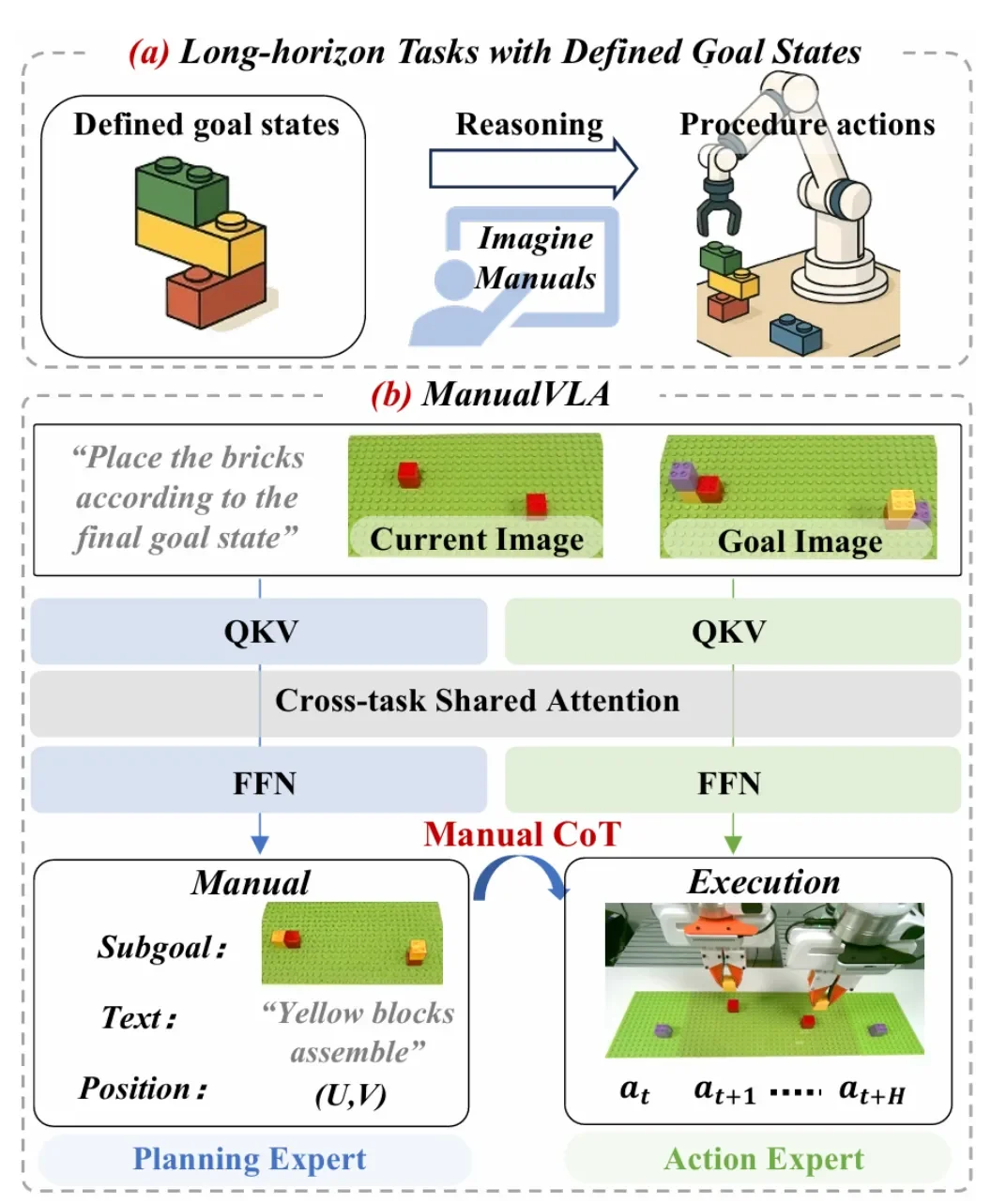
▲ 图 1 | (a) 诸如乐高拼搭或物体重排等具有预定义目标状态的长程任务,对智能机器人构成了重大挑战。(b) 为了解决此类任务,我们提出了 ManualVLA。这是一个基于 MoT 架构构建的统一 VLA 模型,它通过一种精心设计的「说明书思维链」(Manual Chain-of-Thought),实现了多模态手册生成与动作生成之间的紧密协同。

ManualVLA 将 Janus-Pro 1B 拓展到 MoT 架构,形成统一 VLA 模型并集成「规划专家」和「动作专家」,实现了多模态手册生成和动作执行之间的连贯协作。
该机制从显式与隐式两条路径影响动作生成。
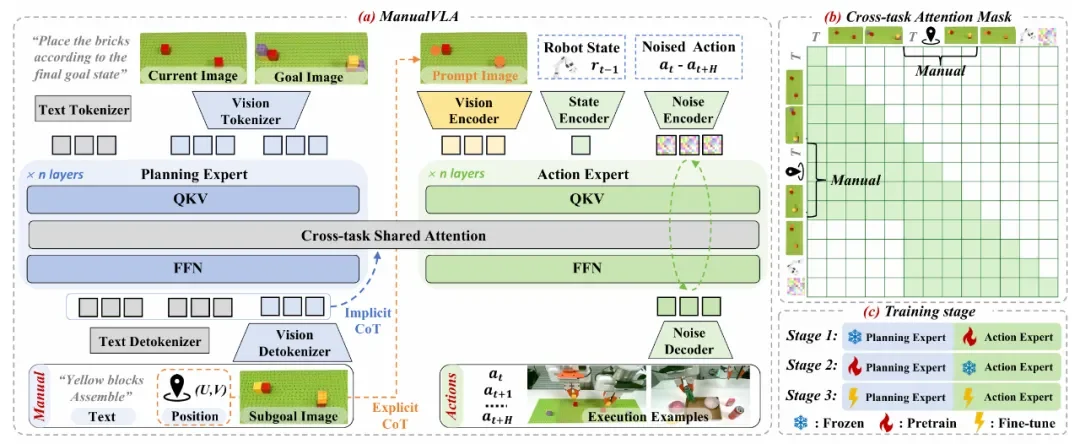
▲ 图 2 | (a) 该框架包含两个专家模块:负责生成多模态「说明书」的规划专家,以及负责预测精确动作的动作专家。规划专家处理人类指令、当前图像和最终目标图像,生成结合了下一步图像、位置坐标和子任务指令的中间手册。我们引入了一个显式思维链 (Explicit CoT) 推理过程,其中每个位置指示符都作为一个视觉提示 (Visual Prompt) 嵌入到动作专家的观测输入中。(b) 结合跨任务共享注意力机制和专门设计的 Attention mask,生成的「说明书」token 也被用作动作生成的条件信号,从而实现了一种能有效引导动作专家的隐式思维链 (Implicit CoT) 推理过程。
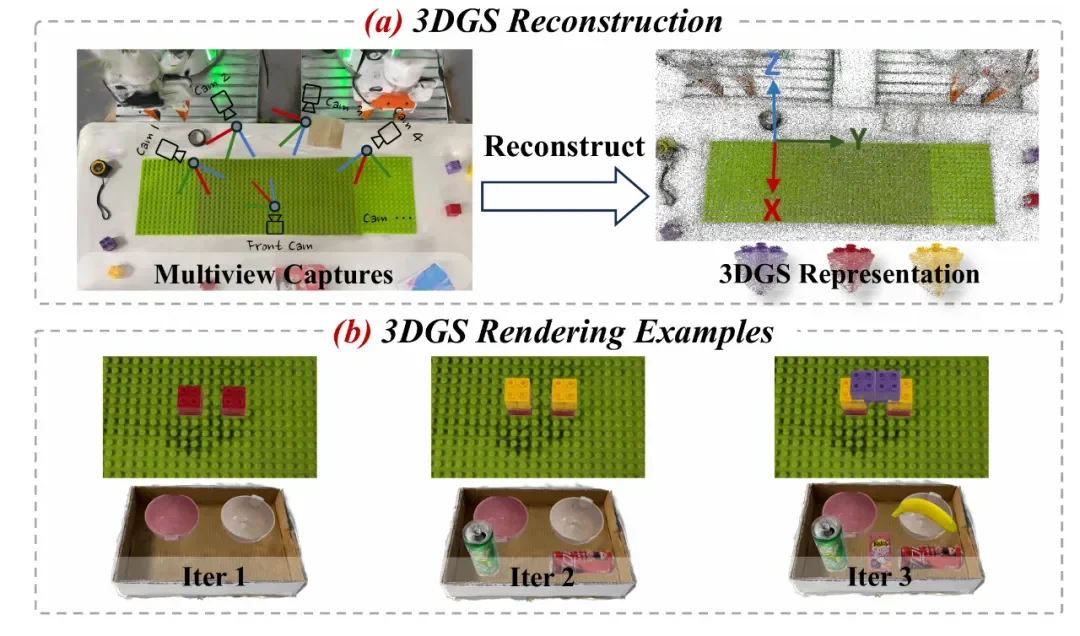
▲ 图 3 | 数字孪生示例 (a) 我们重建了 3D 高斯溅射表征,随后将其分解为乐高底板和单个积木。(b) 我们逐步地将积木放置在底板上/将物体放置在盒子上。
在 Franka 双臂平台上,ManualVLA 测试了三个需要明确目标状态的长周期真实世界任务——2D 乐高组装、3D 乐高组装和物体重新排列。在手册生成方面,规划专家在 300 个未见过的测试样本上生成了令人满意的中间图像(例如 2D 乐高组装的 PSNR 达 29.01),低 FID 分数(例如物体重新排列为 24.46)证实了生成图像的真实性和保真度,而极低的 MAE 分数(例如 2D 乐高组装为 3.23)则突显了模型在预测目标对象位置方面的精确性。

▲ 图 5 | 「规划专家」逐步生成 ManualCoT「说明书」,Pred 指代模型生成的预测结果,GT 指代真实图像。
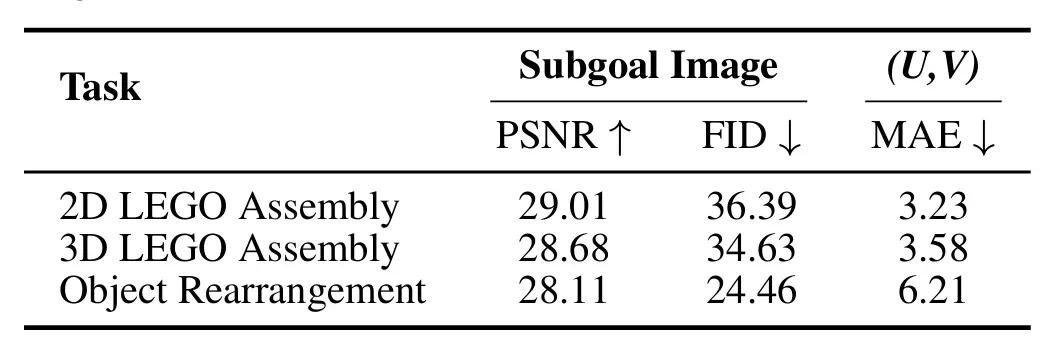
▲ 表 1 | 在三个长程任务上,ManualVLA 生成的中间目标图像与 UV 坐标的质量的量化结果。
ManualVLA 在所有三个真实世界长周期任务中均取得了最高成功率,相比最强的分层基线 (VLM + π0.5),最终任务完成率提高了 15% 到 30%,平均成功率高出 32%。基线模型通常难以在整个长序列中保持性能,但 ManualVLA 通过 ManualCoT 策略有效地将复杂任务分解并锚定到精确动作中,缓解了性能随步骤数增加而下降的问题。


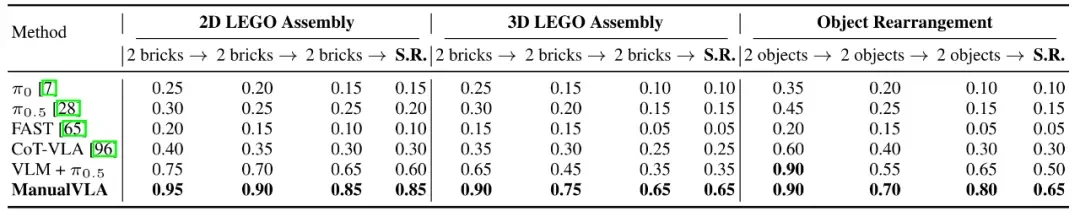
▲ 表 2 | 我们使用 20 个模型均未见过的目标状态进行测试,得到完成长程任务的操作成功率与关键中间步骤的成功率。
ManualVLA 在 RLBench 的 10 个仿真任务上取得了 70% 的平均成功率,超越了 SOTA 方法 π0 的 63%,进一步验证了 ManualCoT 策略在指导精确动作生成方面的优势,在通用原子任务上也能表现出良好效果。

▲ 表 3 | ManualVLA 与各 Baseline 模型在仿真环境 RLBench 上各项原子任务的成功率与方差。
消融实验证明,说明书中所有模态信息(文本、图像、UV 坐标)和隐式 CoT(潜在空间中的条件信号)推理对于解决长周期、目标明确的操作任务是不可或缺的,两者结合才能达到最佳性能。同时,ManualVLA 在未见过的背景、物体形状和光照变化下也表现出鲁棒的泛化能力。
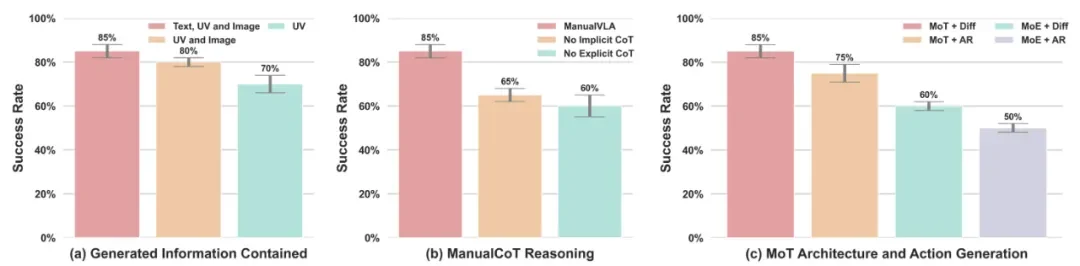
▲ 表 4 | 我们探究了如下因素对任务成功率的影响:(a) 说明书中包含的信息;(b) 显式与隐式的 ManualCoT 思维链机制;(c) MoT 架构与 action 生成范式。
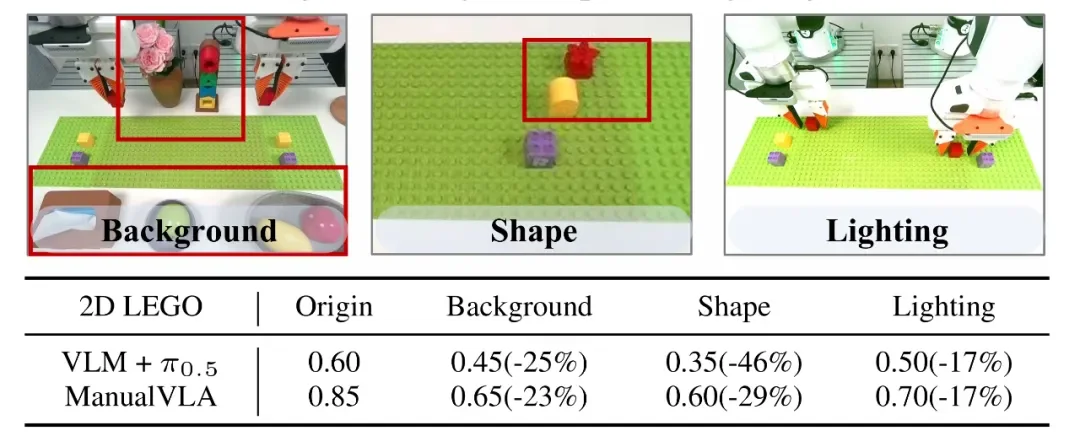
▲ 表 5 | 在明显变化且模型未见过的背景、物体形状和光照变化下,ManualVLA 的任务成功率。
文章来自于“机器之心”,作者“机器之心”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
