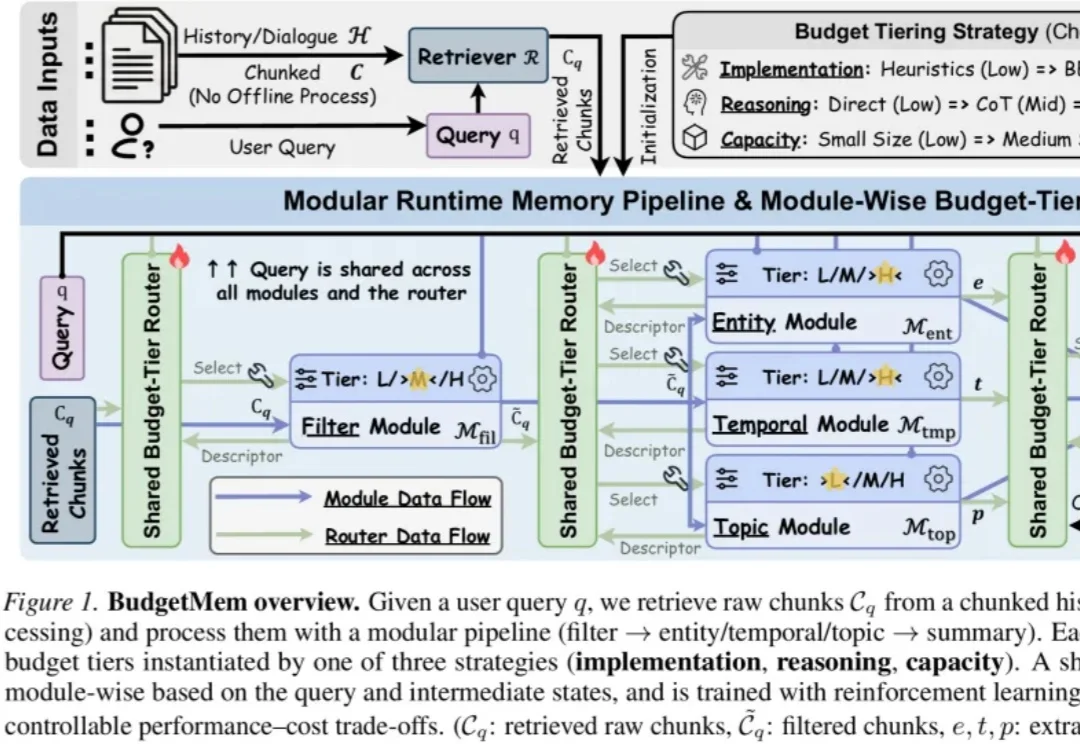
BudgetMem:给Runtime Agent Memory装上「预算路由器」,让记忆系统学会按需分配运行成本
BudgetMem:给Runtime Agent Memory装上「预算路由器」,让记忆系统学会按需分配运行成本当 LLM Agent 处理长期对话、多轮交互和复杂文档时,Memory 已经成为不可或缺的核心模块。它帮助智能体保存历史、检索信息、维持个性化上下文,并支撑跨时间的推理能力。
来自主题: AI技术研报
8051 点击 2026-06-15 09:20
 搜索
搜索
当 LLM Agent 处理长期对话、多轮交互和复杂文档时,Memory 已经成为不可或缺的核心模块。它帮助智能体保存历史、检索信息、维持个性化上下文,并支撑跨时间的推理能力。
某天,老板让你用 Agent 手搓个自动化流程的小工具,你袖子一撸,信心满满地开干。

2026年的AI行业,正在出现一种微妙的变化。

多模态Agent最容易制造的一种错觉是:它看过图片,所以它记住了图片。
TencentDB Agent Memory 全球正式开源

从谷歌DeepMind分拆而出的AI药物英国研发公司Isomorphic Labs昨日宣布完成21亿美元(约合人民币143亿元)B轮融资。据外媒Ventureburn报道,这笔融资创下全球AI制药行业单笔融资新纪录。

随着大模型后训练(Post-training)技术的发展,强化学习(RL)在提升模型推理能力方面的表现备受瞩目。

昨天晚上,OpenAI 宣布推出了 OpenAI 部署公司(OpenAI Deployment Company),目标是帮助企业构建和部署 AI。该公司由 OpenAI 持有多数股权并进行控制,汇集了 19 家领先的投资机构、咨询公司和系统集成商,协助各类组织将前沿 AI 投入生产应用,从而在业务上产生实际影响

EverMind 想做点不一样的。这家由盛大集团孵化的公司,定位是为所有AI Agent提供一个通用的"记忆层"(Memory Layer)。它的核心产品EverOS是一套开源的长期记忆系统,开发者可以把它接入自己的Agent,让AI不仅能记住用户的历史对话和偏好,还能像人一样对记忆进行整理、更新,甚至从过去的经验中学习和进化。
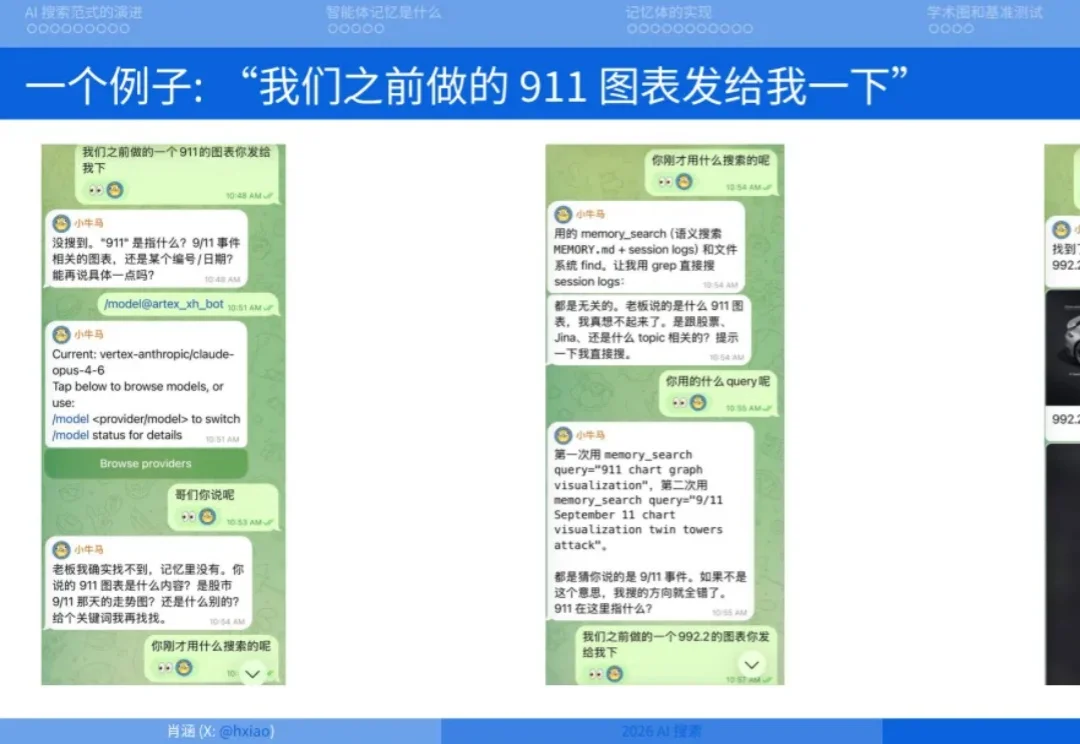
4 月 18 日,Elastic 中国 AI 搜索技术大会在北京召开。以下内容整理自 Elastic 全球副总裁肖涵,原 Jina AI 创始人兼 CEO 在会上的演讲。肖涵讲述了 AI 搜索的发展历程以及为什么说在 2026 年做 AI 搜索基本就是在做智能体记忆 (Agent Memory)。