
多模态大模型首次实现像素级推理!3B参数超越72B传统模型,NeurIPS 2025收录
多模态大模型首次实现像素级推理!3B参数超越72B传统模型,NeurIPS 2025收录多模态大模型首次实现像素级推理,指代、分割、推理三大任务一网打尽!
来自主题: AI技术研报
10137 点击 2025-10-17 10:01
 搜索
搜索
多模态大模型首次实现像素级推理,指代、分割、推理三大任务一网打尽!
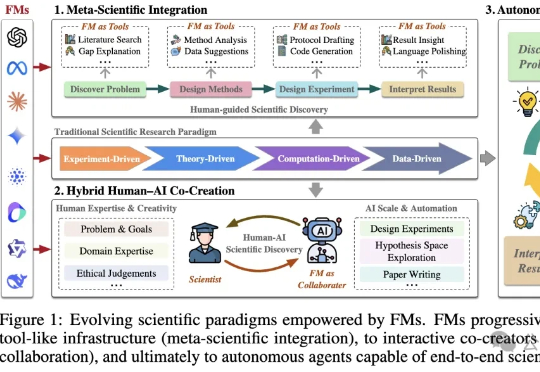
基础模型(FM)是一种在海量数据上训练的人工智能系统,具备强大的通用性和跨模态能力。港科大最新发表的论文显示:FM可能引领科学进入第五范式,但大模型的偏见、幻觉等问题仍需正视。
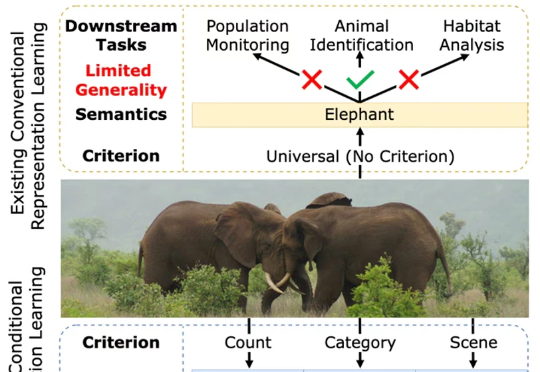
一张图片包含的信息是多维的。例如下面的图 1,我们至少可以得到三个层面的信息:主体是大象,数量有两头,环境是热带稀树草原(savanna)。然而,如果由传统的表征学习方法来处理这张图片,比方说就将其送入一个在 ImageNet 上训练好的 ResNet 或者 Vision Transformer,往往得到的表征只会体现其主体信息,也就是会简单地将该图片归为大象这一类别。这显然是不合理的。
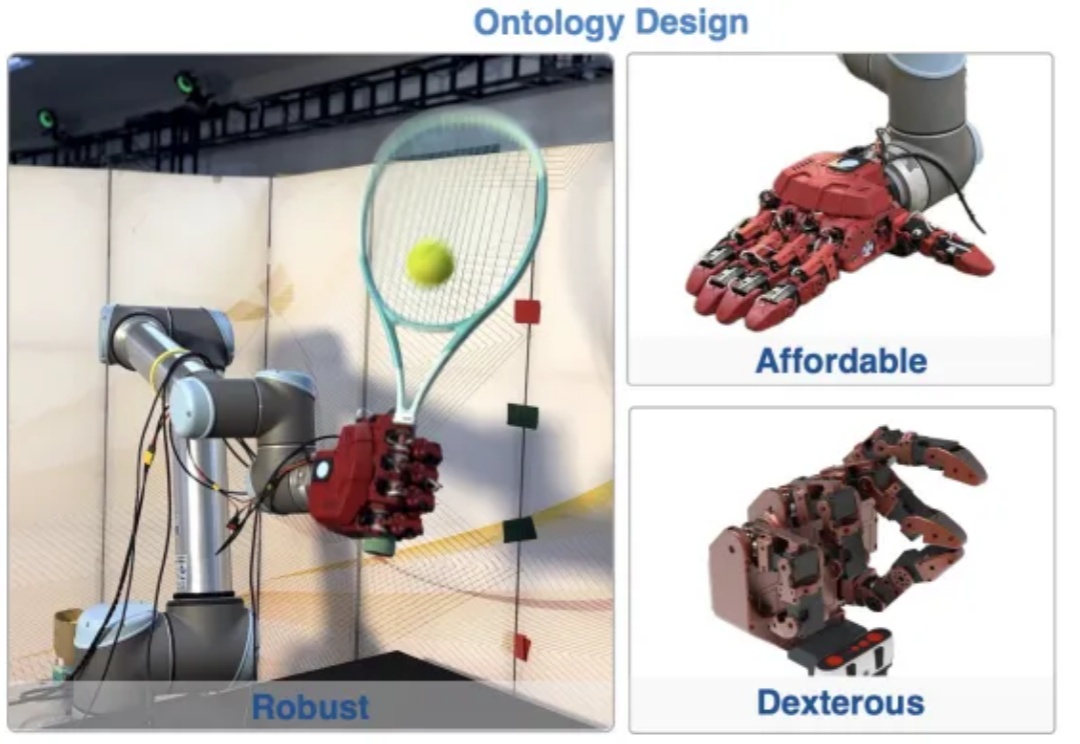
在最近的一篇 NeurIPS 25 中稿论文中,来自中山大学、加州大学 Merced 分校、中科院自动化研究所、诚橙动力的研究者联合提出了一个全新开源的高自由度灵巧手平台 — RAPID Hand (Robust, Affordable, Perception-Integrated, Dexterous Hand)。
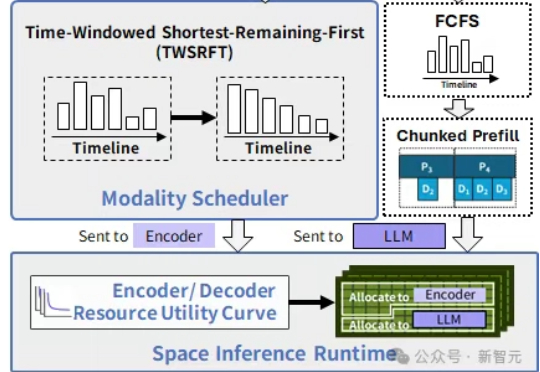
在中国科学院计算技术研究所入选NeurIPS 2025的新论文中,提出了SpaceServe的突破性架构,首次将LLM推理中的P/D分离扩展至多模态场景,通过EPD三阶解耦与「空分复用」,系统性地解决了MLLM推理中的行头阻塞难题。
近年来,NeRF、SDF 与 3D Gaussian Splatting 等方法大放异彩,让 AI 能从图像中恢复出三维世界。但随着相关技术路线的发展与完善,瓶颈问题也随之浮现:

3D 生成正从纯虚拟走向物理真实,现有的 3D 生成方法主要侧重于几何结构与纹理信息,而忽略了基于物理属性的建模。
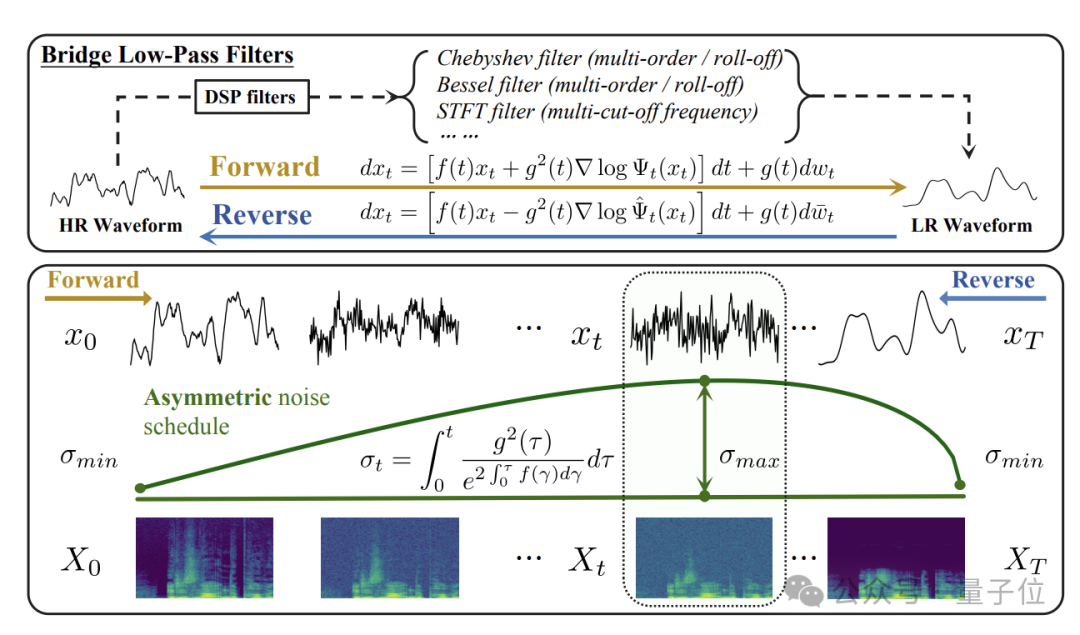
在这一背景下,清华大学与生数科技(Shengshu AI)团队围绕桥类生成模型与音频超分任务展开系统研究,先后在语音领域顶级会议ICASSP 2025和机器学习顶级会议NeurIPS 2025发表了两项连续成果:

在具身智能领域,视觉 - 语言 - 动作(VLA)大模型正展现出巨大潜力,但仍面临一个关键挑战:当前主流的有监督微调(SFT)训练方式,往往让模型在遇到新环境或任务时容易出错,难以真正做到类人般的泛化

近期,北京大学、哈尔滨工业大学联合 PsiBot 灵初智能提出首个自我增强的灵巧操作数据生成框架 ——DexFlyWheel。该框架仅需单条演示即可启动任务,自动生成多样化的灵巧操作数据,旨在缓解灵巧手领域长期存在的数据稀缺问题。目前已被 NeurIPS 2025 接受为 Spotlight(入选率约 3.2%)