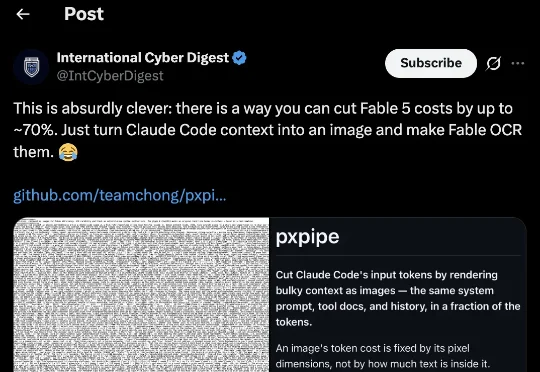
Fable 5被网友薅出省钱神招!pxpipe最高让token减70%!
Fable 5被网友薅出省钱神招!pxpipe最高让token减70%!这两天,有位机智的老哥发现,只要把Fable 5的上下文转换成一张张密密麻麻写满文字的图片,再让模型通过OCR读回来,token输入成本最多能省下70%。更离谱的是,不只是普通对话,系统提示、工具文档、历史记录,全都能一股脑塞进图里。
来自主题: AI资讯
9060 点击 2026-07-06 12:25
 搜索
搜索
这两天,有位机智的老哥发现,只要把Fable 5的上下文转换成一张张密密麻麻写满文字的图片,再让模型通过OCR读回来,token输入成本最多能省下70%。更离谱的是,不只是普通对话,系统提示、工具文档、历史记录,全都能一股脑塞进图里。
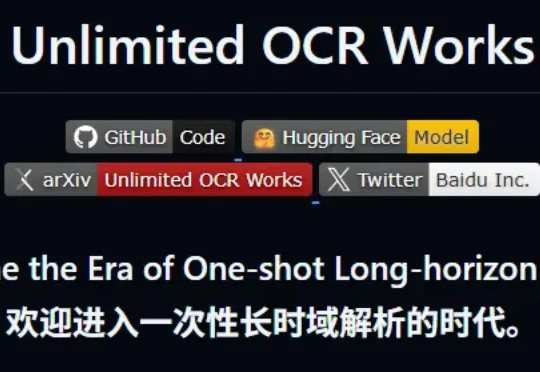
最新开源的Unlimited OCR,总参数3B,实际激活仅500M——放在大模型时代几乎是个零头。但就是这个小到离谱的模型,在OmniDocBench v1.5上拿下93.23%的综合分,v1.6更是达到93.92%,直接刷新了端到端SOTA。

大模型再强,也读不懂你公司那一柜子的合同、发票和扫描件。在"纸张世界"和"LLM世界"之间,缺一座桥——而百度开源的 PaddleOCR,可能就是当下最稳的那座。
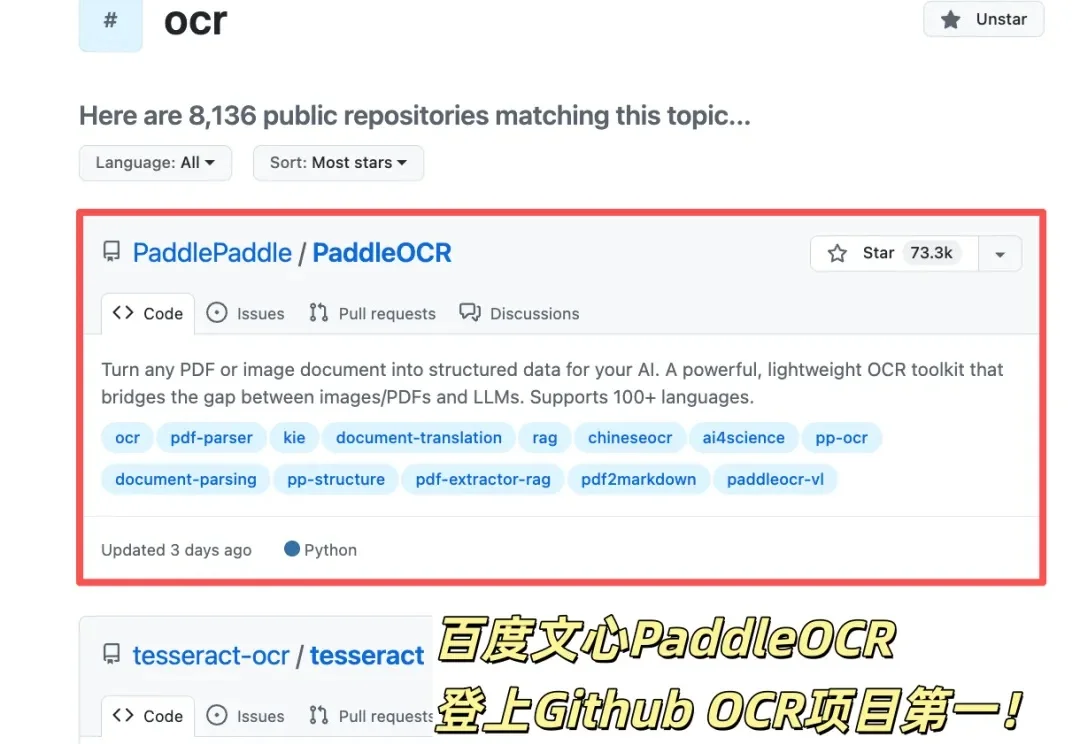
GitHub OCR项目之王刚刚历史性易主。
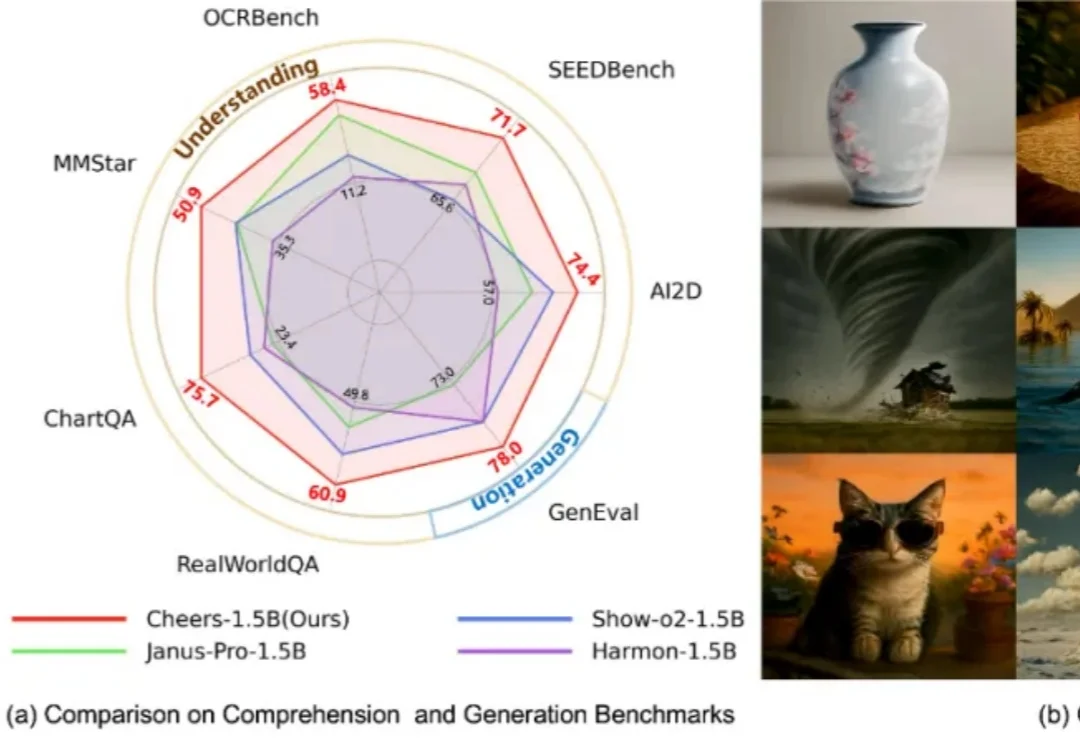
过去几年,多模态模型在理解任务上快速演进,图像问答、OCR、视觉推理、跨模态对话等能力不断提升;与此同时,图像生成模型也在视觉质量、指令遵循和细节表达上持续突破。下一步一个自然的问题是:能否用同一个模型,同时做好理解与生成?这正是统一多模态模型(Unified Multimodal Models, UMMs)正在回答的问题。
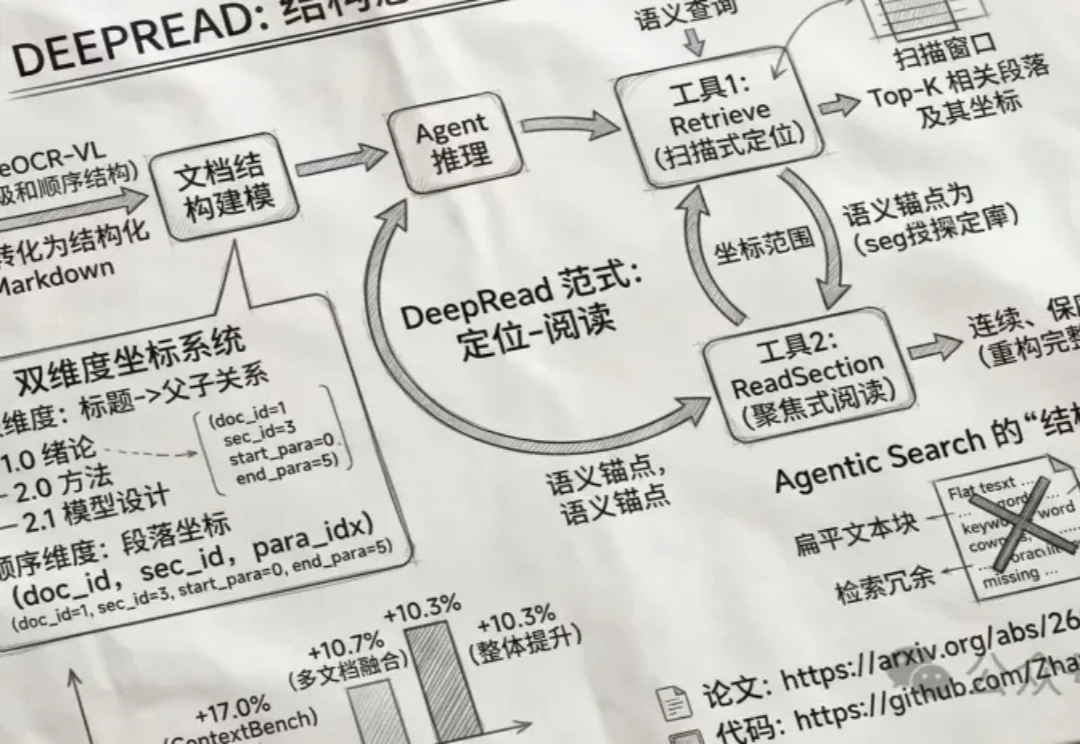
DeepRead让AI像人一样阅读文档:利用OCR识别章节结构,先精准定位相关段落,再完整读取上下文,避免碎片化检索。实验显示,其长文档问答准确率提升17%,能自动跳过冗余信息,精准提取财报、论文等复杂内容,无需额外知识图谱,轻量高效。
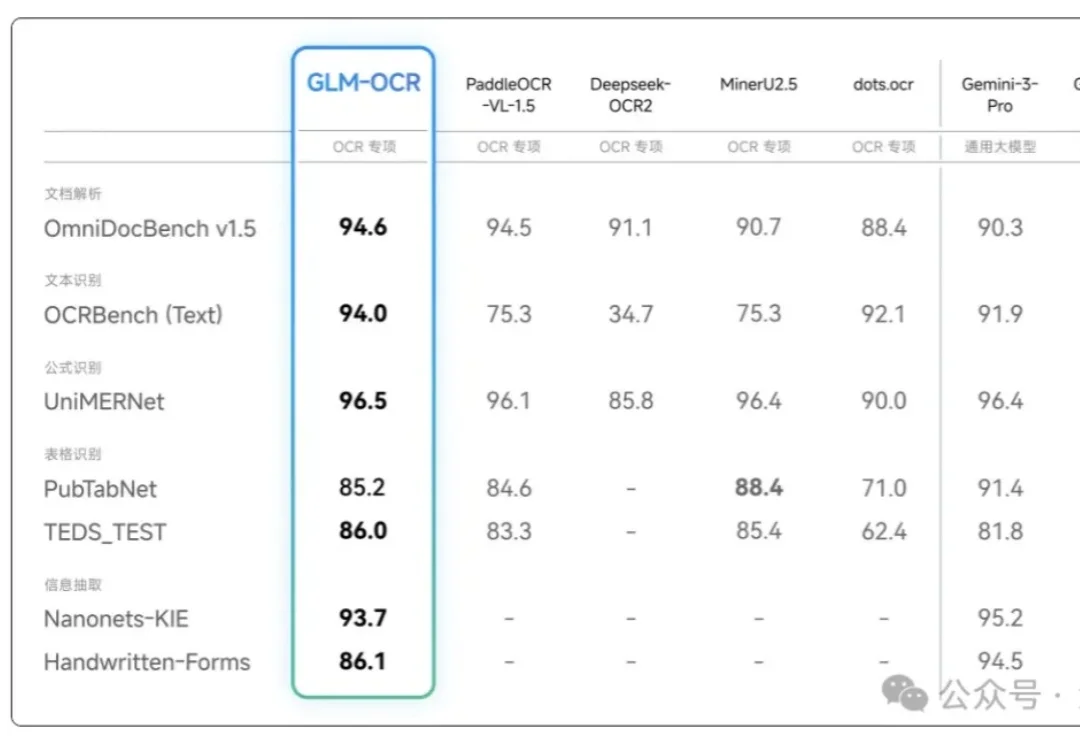
OCR模型究竟能干什么?干得怎么样?
没想到吧,Google DeepMind刚刚为Gemini 3 Flash推出了一个重量级新能力:Agentic Vision(智能体视觉)。(难道是被DeepSeek-OCR2给刺激到了?)

嘿!刚刚,DeepSeek 又更新了!这次是更新了十月份推出的 DeepSeek-OCR 模型。刚刚发布的 DeepSeek-OCR 2 通过引入 DeepEncoder V2 架构,实现了视觉编码从「固定扫描」向「语义推理」的范式转变!

DeepSeek开源DeepSeek-OCR2,引入了全新的DeepEncoder V2视觉编码器。该架构打破了传统模型按固定顺序(从左上到右下)扫描图像的限制,转而模仿人类视觉的「因果流(Causal Flow)」逻辑。