ICML 2026|小模型也能「指挥」大模型RL后训练:清华&腾讯提出GPS,最高减少69% Rollout成本
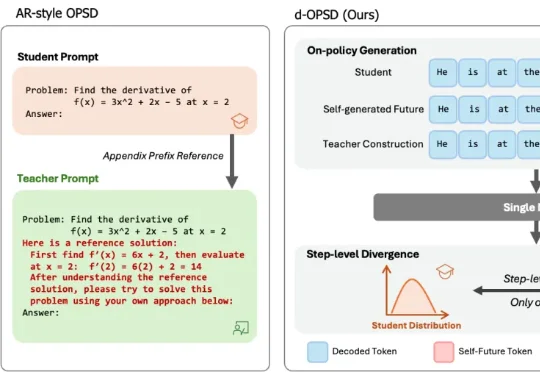
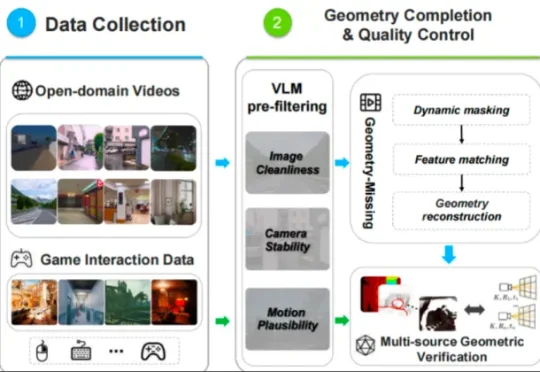
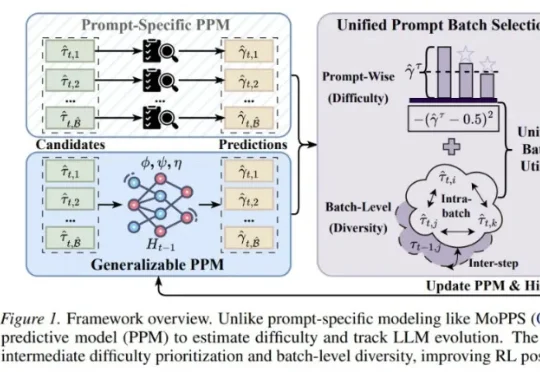
ICML 2026|小模型也能「指挥」大模型RL后训练:清华&腾讯提出GPS,最高减少69% Rollout成本来自清华大学与腾讯的研究者提出了 Generalizable Predictive Prompt Selection(GPS)。GPS 的做法很直接:先训练一个小型、可泛化的 Prompt Predictive Model(PPM),让它预测不同 prompt 在当前模型下的难度;再根据难度和 batch 多样性选择训练样本,从而减少无效 rollout。
来自主题: AI技术研报
7786 点击 2026-07-11 11:16