
牛津、英伟达等提出记忆压缩新范式:训练时让模型学会断舍离
牛津、英伟达等提出记忆压缩新范式:训练时让模型学会断舍离2026 年初,各大 AI 厂商在上下文窗口长度上展开激烈角逐。Google 的 Gemini 3 Pro 已支持 100 万级 token 上下文,Meta 的 Llama 4 Scout 更宣称可处理 1000 万 token。GPT-5 系列也在快速推进长上下文能力。
来自主题: AI技术研报
9820 点击 2026-06-02 11:23
 搜索
搜索
2026 年初,各大 AI 厂商在上下文窗口长度上展开激烈角逐。Google 的 Gemini 3 Pro 已支持 100 万级 token 上下文,Meta 的 Llama 4 Scout 更宣称可处理 1000 万 token。GPT-5 系列也在快速推进长上下文能力。

就在前两天,斯坦福大学等机构发布了一个名为 GPIC(Giant Permissive Image Corpus,巨型开放图像语料库)的数据集。
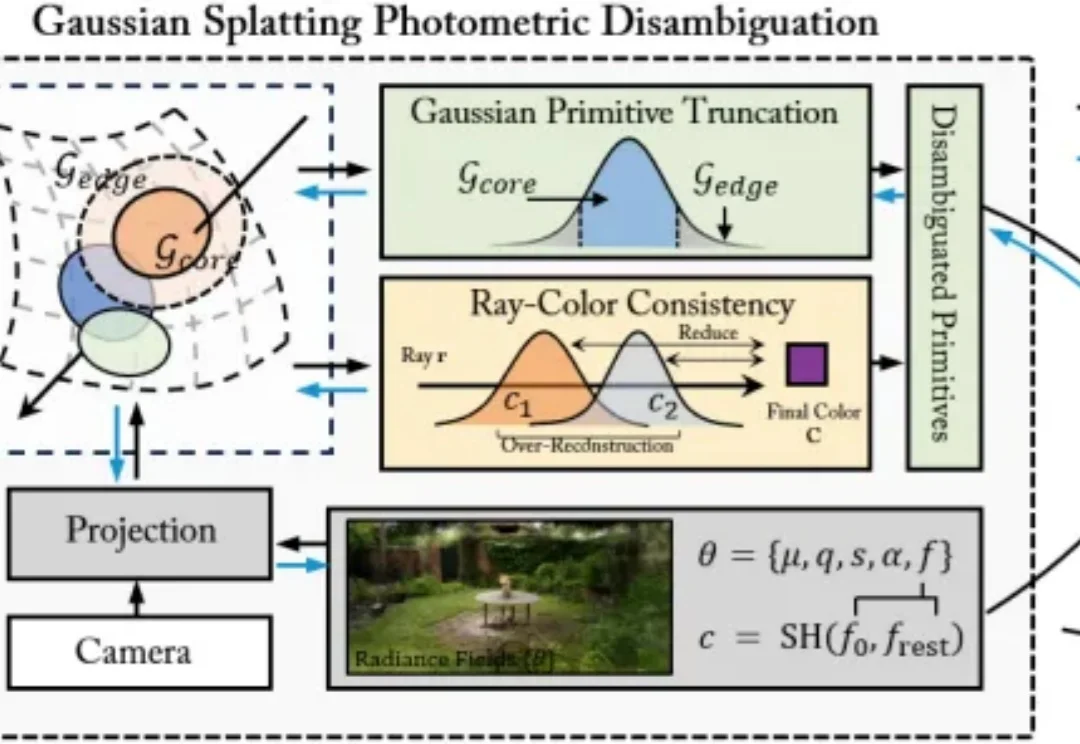
近年来,3D Gaussian Splatting(3DGS)在三维视觉和图形学中展现出很强的表示与渲染能力。相比传统体素或神经辐射场,它用一组可优化的各向异性高斯来表示三维场景,既能保留连续空间结构,又能实现高速渲染。

如果把现在最热门的几条 3D 生成技术线放在一起看,你会发现它们正在遇到一个很像的问题。
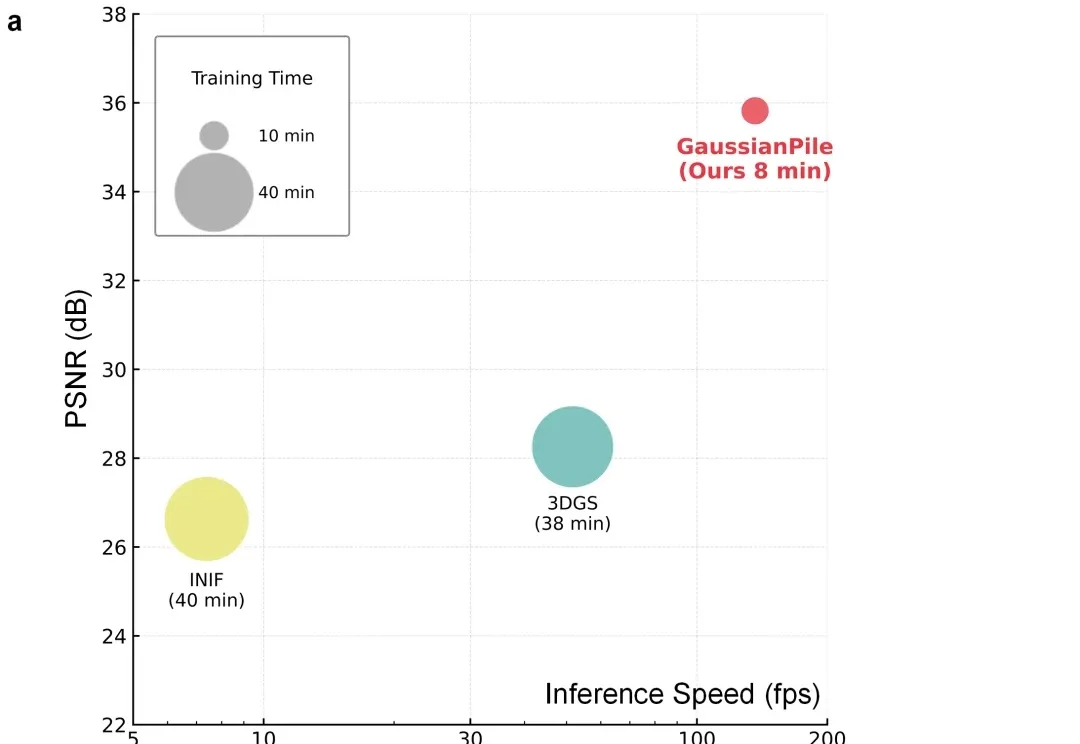
近年来,3D 高斯泼溅(3D Gaussian Splatting, 3DGS)凭借其卓越的新视角合成能力和实时的渲染效率,极大地推动了神经渲染技术的发展。然而,当研究者试图直接从 3DGS 中提取精确的 3D 几何表面(Mesh 等)时,往往会面临严重的几何失真问题。
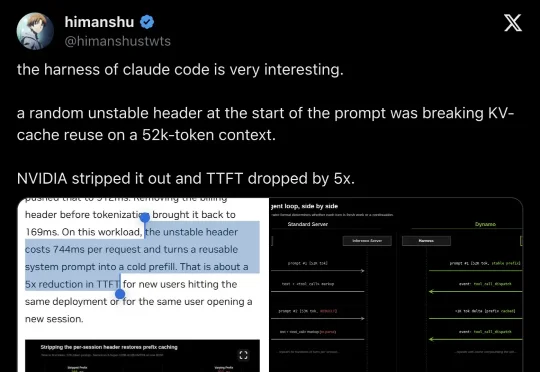
NVIDIA Dynamo 团队发现,Claude Code 向自定义端点发送请求时,prompt 最前面会带一行 session-specific billing header。这行 header 每个 session 都变,导致 52K token 的稳定前缀在 KV cache 中无法复用——TTFT 从 168ms 飙到 912ms。Dynamo 加了一个 `
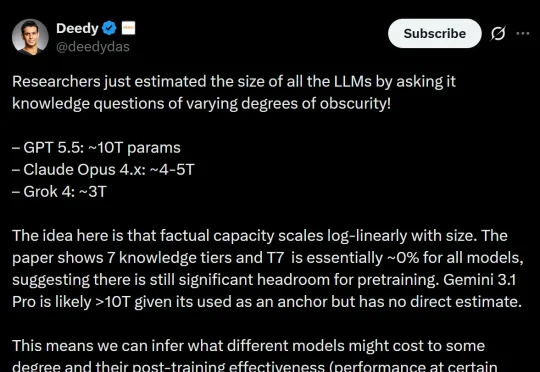
五一假期前,AI社区被一篇「GPT-5.5拥有近10万亿参数」的论文刷屏,今天这项研究就被研究者打假了!研究者表示,修正论文中的各种问题后,GPT-5.5的参数很可能约为1.5T。

Lindy.ai 的创始人 Flo Crivello 做了件挺大胆的事:把 AI 助理塞进了 iMessage。不是做一个新 App,不是搞一个聊天界面,就是直接出现在你的短信列表里,像一个真人助理一样跟你对话。
前几天,一篇来自Kimi的论文「ATTENTION RESIDUALS」在 AI 圈引发了激烈讨论——马斯克罕见地发出评价:"Impressive work from Kimi"。同时,两位前Openai大佬也同样发出了高度评价,OpenAI 「推理模型之父」Jerry Tworek表示“深度学习2.0时代即将到来”。

一个不存在的金发女兵,用AI合成的脸骗了一百万直男,用爱国人设收割了无数钱包——而这场骗局,可能只是AI虚假身份入侵现实世界的开场白。