
2秒钟转写5分钟音频!国产新语音模型拿下多项SOTA,定价骤减90%
2秒钟转写5分钟音频!国产新语音模型拿下多项SOTA,定价骤减90%阶跃星辰今日发布新一代自动语音识别模型StepAudio 2.5 ASR。该模型面向语音转写与长音频处理场景,在架构上引入Multi-Token Prediction(多Token预测)以提升推理效率,并通过扩展上下文窗口强化长内容识别能力。
来自主题: AI资讯
9595 点击 2026-04-25 10:22
 搜索
搜索
阶跃星辰今日发布新一代自动语音识别模型StepAudio 2.5 ASR。该模型面向语音转写与长音频处理场景,在架构上引入Multi-Token Prediction(多Token预测)以提升推理效率,并通过扩展上下文窗口强化长内容识别能力。

几乎所有 Transformer 都在做一件反常的事:把大量注意力集中到少数几个特定 Token 上。这不是 bug,而是 Transformer 固有的「注意力汇聚」(Attention Sink)。首篇系统性综述,带你从利用、理解到消除,全面掌握这一核心现象。
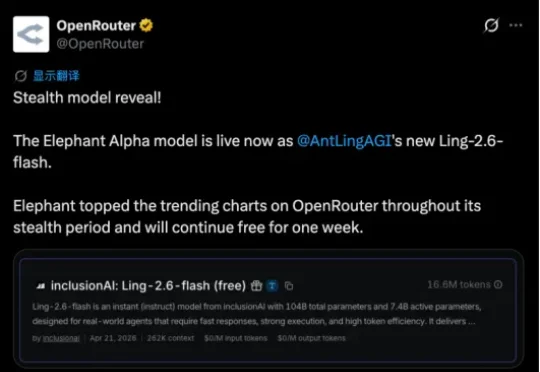
4月22日,蚂蚁百灵正式推出Ling-2.6-flash Instruct模型。该模型总参数量为104B,激活参数仅7.4B,核心主打高“Token 效率(Token Efficiency)”。API定价方面,Ling-2.6-flash输入每百万tokens定价0.1美元,输出 0.3 美元。目前,Ling-2.6-flash API已在OpenRouter及百灵tbox平台上线。
当 AI 智能体不再只是「一次性工具」,而是能够持续学习、自我进化的「数字伙伴『数字同事』,会发生什么?自进化智能体应该采取怎样的设计原则?

小米大模型时隔一月能力飙涨,比Kimi K2.6省42% Token。

大厂福利变迁史,也是一部生产力进化史。
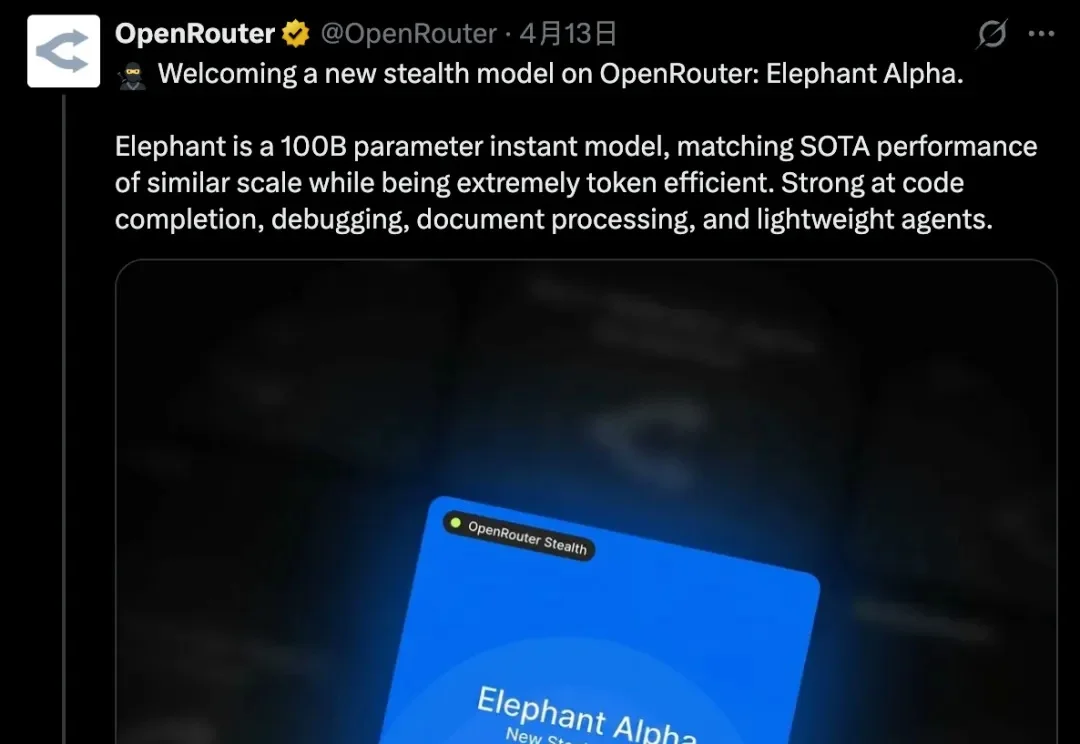
神秘模型Elephant的面纱,终于被揭开了。
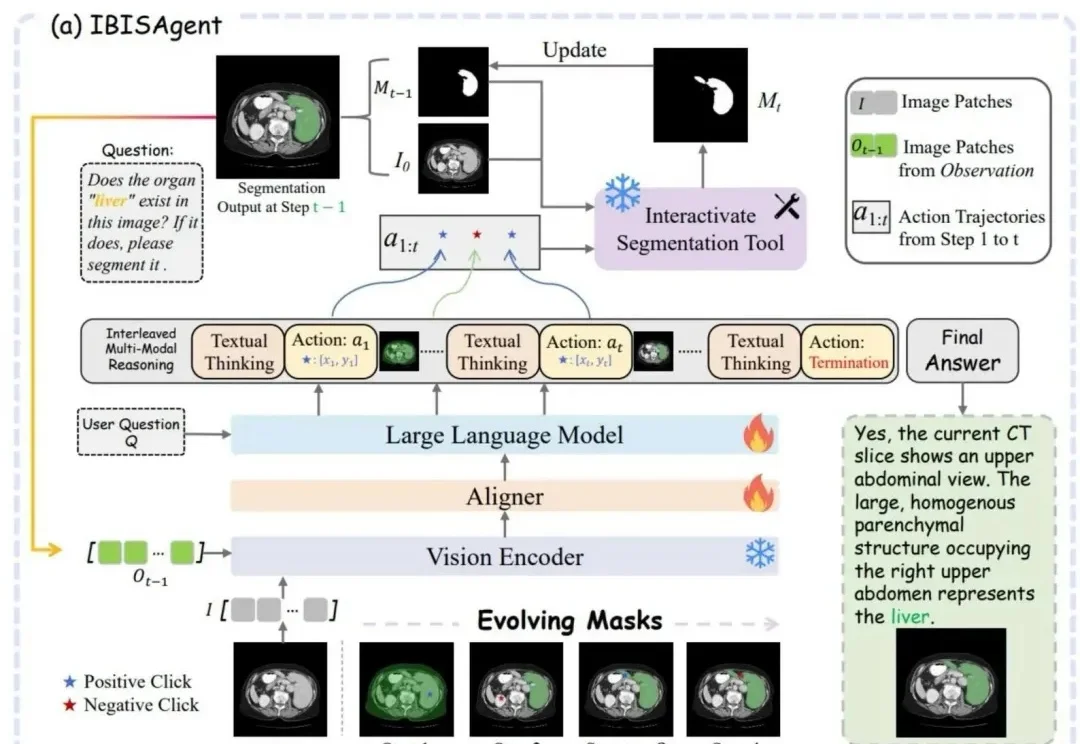
这个生物医学视觉推理框架,被CVPR 2026接收了!

如果你在网络安全圈混,最近一定被“Mythos”刷过屏——Anthropic 搞出了一个能挖 Bug 的 AI 模型,但因为怕被坏人滥用,愣是没敢公开发布。

当前大模型的发展呈现出类似于“军备竞赛”的趋势——模型规模持续攀升,对计算硬件的需求也随之快速增长。