热门Harness项目OpenSquilla:拯救烧token烧到绝望的Agent们,估值1亿
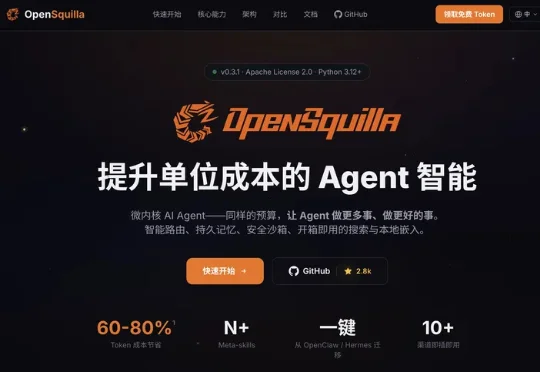
热门Harness项目OpenSquilla:拯救烧token烧到绝望的Agent们,估值1亿OpenSquilla 是一个开源 Agent Harness 框架(https://github.com/opensquilla/opensquilla)。它在 Agent 应用和模型之间加了一层运行中枢。OpenSquilla 由上海基元律动科技有限公司开发。基元律动成立仅几个月后,已完成首轮融资,估值高达1亿美元。
来自主题: AI资讯
9257 点击 2026-06-06 10:34