
牛津、英伟达等提出记忆压缩新范式:训练时让模型学会断舍离
牛津、英伟达等提出记忆压缩新范式:训练时让模型学会断舍离2026 年初,各大 AI 厂商在上下文窗口长度上展开激烈角逐。Google 的 Gemini 3 Pro 已支持 100 万级 token 上下文,Meta 的 Llama 4 Scout 更宣称可处理 1000 万 token。GPT-5 系列也在快速推进长上下文能力。
来自主题: AI技术研报
10000 点击 2026-06-02 11:23
 搜索
搜索
2026 年初,各大 AI 厂商在上下文窗口长度上展开激烈角逐。Google 的 Gemini 3 Pro 已支持 100 万级 token 上下文,Meta 的 Llama 4 Scout 更宣称可处理 1000 万 token。GPT-5 系列也在快速推进长上下文能力。

让用户实现从「租赁智能」到「拥有智能」。

2026年5月30日,半导体研究机构SemiAnalysis发布深度报告《AI Dark Output: The Visible Cost of Invisible Output》,提出了一个“暗产出”的概念,判断AI正在大规模创造真实经济价值,但这些价值在GDP、价格指数和就业统计中几乎无迹可寻,规模“可能不亚于工业革命”。
在这场日益蔓延的“Token焦虑”中,Agnes AI的举动显得格外扎眼——这家全球榜单排名第九的AI Lab宣布,自6月1日起,旗下全模态模型API无限期免费开放。Agnes AI本次开放覆盖其三款核心模型:文本模型Agnes-2.0-Flash、图像模型Agnes-Image-2.0-Flash以及视频模型Agnes-Video-V2.0。

4月,OpenAI Codex正式把计费口径从按消息估算转向按token用量;Anthropic侧的企业续约和新版模型tokenizer(分词器),也让 Claude Code的实际账单压力集中显现。明升与暗涨,两家各有各的玩法。

本次2026中国AIGC产业峰会上,MiniMax ToB中国区商业化负责人胡维琦,分享了自己在AI创业公司中的实践与思考。与其焦虑AI,不如加入AI。大家不用看营销号,更多的还是自己动手试试。
最近和几个做 AI 出海的朋友聊天,大家已经很少去聊哪个模型又刷了榜。谈论最多的,是哪个模型调度平台好用、实惠、安全。 这话题我是一点都不意外。毕竟前不久全球大佬都在扎堆往 AI 这个方向挤。老话说得

根据外媒 Axios 的最新报道,一位 AI 顾问告诉 Axios,他有个客户最近一个月在 Claude 上花了 5 亿美元。不是 500 万,不是 5000 万,是 500000000 美元,折合人民币三十三亿。
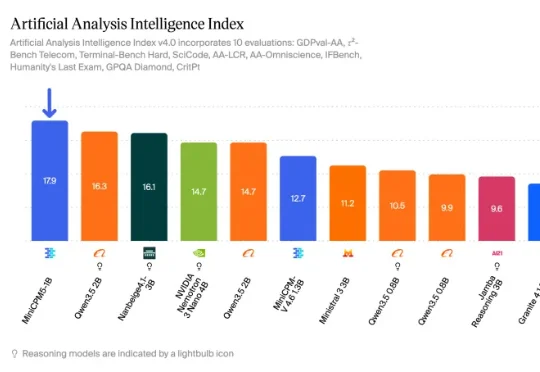
我去搜了下 MiniCPM5-1B 的数据,发现面壁智能刚刚把背后的核心数据集给开源了。一共是两份 L3 级数据集:Ultra-FineWeb-L3 :600B tokens,中英文都有,是目前最大的中文开源合成预训练数据集。

Omdia这份名为《2026全球AI工厂市场格局》的报告,点明了新时代的核心逻辑——决定胜负的,不再是谁拥有更多GPU,而是谁能够更高效地把“电力+算力+数据”转化为真正有价值的Token。