Being-VL的视觉BPE路线:把「看」和「说」真正统一起来
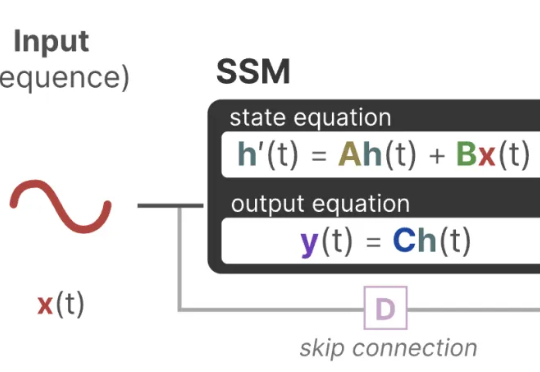
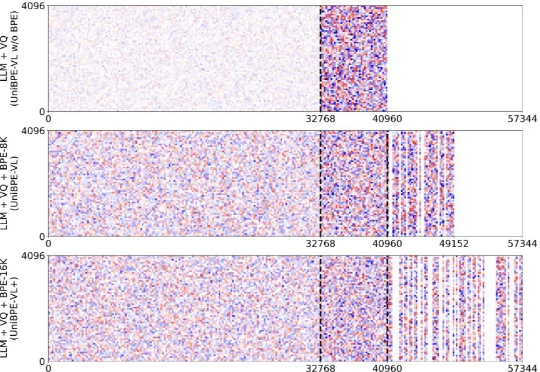
Being-VL的视觉BPE路线:把「看」和「说」真正统一起来为此,北大、UC San Diego 和 BeingBeyond 联合提出一种新的方法——Being-VL 的视觉 BPE 路线。Being-VL 的出发点是把这一步后置:先在纯自监督、无 language condition 的设定下,把图像离散化并「分词」,再与文本在同一词表、同一序列中由同一 Transformer 统一建模,从源头缩短跨模态链路并保留视觉结构先验。
来自主题: AI技术研报
8649 点击 2025-10-14 09:58